이번 글에서는 Chatper 6을 정리해보려고 합니다.


다른 Chapter 대비 분량이 많아서, 6.1부터 6.10까지 한번 끊고 6.11부터 6.21까지 다른 글로 정리해보겠습니다.
Chapter 6.1 배열 기초 [1 of 2]
이번 Chapter 에서는 배열의 기초에 대해서 다루게 된다. 배열 내용이 많다보니, 2개 강의에 걸쳐 설명하신다고 한다.
예제 코드 1
using namespace std;
struct Rectangle
{
int length;
int width;
};
int one_student_score; // 1 variable
int student_scores[5]; // 5 int
student_scores[0] = 100;
student_scores[1] = 80;
student_scores[2] = 90;
student_scores[3] = 50;
student_scores[4] = 0;
//student_scores[5] = 20;
for (int i = 0; i < 5; i++)
{
cout << student_scores[i] << endl;
}
Rectangle rect_arr[10];
rect_arr[0].length = 1;
rect_arr[0].width = 2;
배열을 사용하는 방법은 단순하다. 자료형 변수명[크기] 순으로 사용하면 된다.
위 코드에서는 int student_scores[5]로 사용하였다. 이전에는 변수 1개를 선언했다면, 배열은 같은 자료형의 여러 개의 변수가 담길 수 있는 그릇을 선언하는 셈이다.
배열의 값에 접근할 때는 []를 사용하며, index를 이용해서 값을 주거나 출력을 할 수 있다.
이전에 배웠던 여러 변수들을 함께 정의하는 방법인 구조체를 사용해서도 동일한 방식으로 배열을 선언할 수 있다.
rect_arr에서 0번째를 접근할 때는 [0]로 접근하고, 구조체 내 변수들의 값을 핸들링할 때는 . 을 사용하여 접근할 수 있다.
예제 코드 2
enum StudentName
{
JACKJACK, // 0
DASH, // 1
VIOLET, // 2
NUM_STUDENTS // 3
};
//int my_array[5] = { 1, 2, 3, 4, 5 };
//int my_array[5] = { 1, 2, };
//int my_array[] = { 1, 2, 3, 4, 5 };
int my_array[]{ 1, 2, 3, 4, 5 };
for (int cnt = 0; cnt < size(my_array); cnt++)
{
cout << my_array[cnt] << endl;
}
int student_scores[NUM_STUDENTS];
student_scores[JACKJACK] = 0;
student_scores[DASH] = 1;
student_scores[VIOLET] = 2;
const int num_students = 20;
//cin >> num_students;
// compile time에 length가 반드시 결정되어 있어야 함
int student_scores[num_students];
배열을 선언할 때 직접적으로 값을 주면서 선언하는 방법은 여러가지가 있다.
int my_array[5] = { 1, 2, 3, 4, 5 }; 처럼 배열의 크기와 배열 내 요소들의 값을 명시적으로 주는 방법도 가능하고,
int my_array[5] = { 1, 2, }; 처럼 만드는 경우 3번째부터 5번째까지의 element는 값이 모두 0이다.
int my_array[] = { 1, 2, 3, 4, 5 }; 처럼 만들면 값을 명시적으로 준 경우라 배열의 크기를 유추할 수 있으니 5개짜리 배열이 만들어진다.
int my_array[]{ 1, 2, 3, 4, 5 }; 처럼 만드는 것도 가능하다.
이전에 배웠던 enum을 활용하는 방법도 가능하다.
enum 안에 NUM_STUDENTS 변수를 만들어두면, 보기 좋게 배열의 크기를 선언할 수 있다는 점이 눈에 띈다.
마지막으로 배열의 크기에는 반드시 상수가 들어가야만 한다.
그래서 단순히 int형 변수를 선언한 후 배열 선언할 때 배열의 크기로 사용하면 에러가 나며, 변수가 상수가 될 수 있도록 const를 사용해주면 배열을 선언할 때 배열의 크기에 변수를 사용할 수 있다.
Chatper 6.2 배열 기초 [2 of 2] array
챕터 6.1에 이어서 배열에 대해서 알아본다. 챕터 6.1에서는 기본적인 배열이 무엇인지에 대해서 알아보았다면, 6.2에서는 포인터와 메모리 주소 관점에서 다룬다.
예제 코드 1
int main()
{
const int num_students = 20;
// 배열의 이름 = 배열의 식별자, 내부적으로 주소로 사용됨.
int students_scores[num_students] = { 1, 2, 3, 4, 5, };
// array는 첫번째 주소를 가지고 있음.
cout << (int)&students_scores << endl;
// 배열은 주소 연산자를 붙이지 않아도 주소를 얻을 수 있다.
// 배열은 주소로 데이터를 주고 받는 것이 원소를 전부 복사하는 것 보다 효율적이기 때문에 문법이 이렇게 되어 있음.
cout << (int)students_scores << endl;
cout << (int)&students_scores[0] << endl;
}

예제 코드 1번에서 다루는 내용은, 우선 첫 번째로 배열의 이름은 배열의 식별자로 내부적으로 주소로 사용된다는 점이다.
C++에서 어떤 변수의 주소를 확인하려면 &를 붙여서 확인해야 하는데, 배열의 경우 변수명만 출력해도 해당 배열의 주소를 확인할 수 있다.
그리고 특이한 점은 array가 첫 번째 주소를 가지고 있다는 것이다.
따라서 stduent_scores로 출력하나, &students_scores로 출력하나, &students_scores[0]로 출력하나 모두 다 같은 주소를 가리키게 된다.
예제 코드 2
int main()
{
const int num_students = 20;
int students_scores[num_students] = { 1, 2, 3, 4, 5, };
cout << (int)&students_scores[0] << endl;
cout << (int)&students_scores[1] << endl;
cout << (int)&students_scores[2] << endl;
cout << (int)&students_scores[3] << endl;
}

20개의 int 변수로 이루어진 배열에서, 첫 번째 요소의 주소, 두 번째 요소의 주소, 세 번째 요소의 주소, 네 번째 요소의 주소를 각각 찍어보면 4씩 이동하는 것을 알 수 있다.
따라서 배열은 일종의 20개의 집이 붙어있는 주택 단지 같은 개념이고, 한 집씩 이동할 때 마다 주소가 4씩 이동한다고 이해하면 된다.
예제 코드 3
void doSomething(int student_scores[])
{
cout << (int)&student_scores << endl;
cout << (int)&student_scores[0] << endl; // 첫 번째 주소값을 출력하면 밖에서 정의한 주소랑 같음.
cout << student_scores[0] << endl;
cout << student_scores[1] << endl;
cout << student_scores[2] << endl;
cout << "Size? : " << sizeof(student_scores) << endl; // 넘어올 때 포인터로 넘어왔음. 포인터 사이즈가 4라는 의미임.
}
int main()
{
const int num_students = 20;
// 배열의 이름 = 배열의 식별자, 내부적으로 주소로 사용됨.
int students_scores[num_students] = { 1, 2, 3, 4, 5, };
// array는 첫번째 주소를 가지고 있음.
cout << "address in main " << (int)&students_scores << endl;
// 함수의 parameter로 넣어줄 수 있다.
doSomething(students_scores);
}
예제 코드 3번에서 다루고 있는 내용은, 함수의 parameter로 배열을 전달할 수 있다는 점이다.
다만, 굉장히 독특한 부분이 있는데, 함수의 parameter로 전달된 것은 배열이 아니라 포인터이다.
즉, 우리가 생각하기에 함수 doSomething의 parameter인 student_scores[]는 당연히 배열이라고 생각하지만, 컴파일러는 내부적으로 이를 포인터로 처리하게 된다.
추가로, 또 독특한 부분 중 하나가 바로 함수 내부에서 &student_scores를 할 때와 밖에서 &student_scores를 할 때가 주소가 다르다는 점인데, 이는 함수 내부에서의 student_scores는 '배열의 주소 값을 저장하는 다른 변수'이기 때문이다.
그래서 함수 내부에서의 &student_scores를 찍어보면 주소 값을 저장하는 다른 변수의 주소가 출력이 된다.
그런데 첫 번째 주소값을 출력하면 밖에서 정의한 주소와 같다. (&student_scores[0])
마지막으로 함수 내에서 sizeof(student_scores)를 하면 4로 출력되는데, 이는 student_scores가 포인터이기 때문이며 포인터의 사이즈가 4라는 의미이다.
Chapter 6.3 배열과 반복문
이번 챕터에서는 배열에 반복문을 사용하는 케이스에 대해서 알아본다.
예제 코드 1
#include <iostream>
using namespace std;
int main()
{
const int num_students = 5;
int scores[num_students] = { 84, 92, 76, 81, 56 };
//const int num_students = sizeof(scores) / sizeof(int); // 파라미터로 넘어간 array인 경우 포인터이므로 이와 같은 방식으로는 불가능.
int total_score = 0;
int max_score = 0;
int min_score = numeric_limits<int>::max();
// < 인지 <= 인지 확인.
for (int i = 0; i < num_students; i++)
{
total_score += scores[i];
max_score = (max_score < scores[i]) ? scores[i] : max_score;
min_score = (min_score > scores[i]) ? scores[i] : min_score;
}
double avg_score = static_cast<double>(total_score) / num_students;
cout << max_score << endl;
cout << min_score << endl;
}
이번 챕터에서는 배열에 반복문을 사용해본다.
이전 챕터에서도 얘기했지만, 배열의 크기는 반드시 상수를 사용해야 하므로, const int로 선언된 변수를 가지고 배열의 크기를 선언해야하고, 배열 내 값들은 { }를 활용하면 된다.
만약 위와 같은 케이스일 때는 배열 scores의 sizeof를 변수 타입인 int의 sizeof로 나누면 student의 수를 구할 수 있다. 다만, 이전 예제에서 나온 것 처럼 함수의 파라미터로 배열을 사용하는 경우, 파라미터는 배열 그 자체가 아니라 배열의 주소를 저장하는 포인터이므로 이와 같은 방식으로 사용하면 이상한 값을 구하게 된다.
다음으로는 for문과 배열을 활용해서 배열의 합, 최댓값, 최솟값을 구하는 방법이다.
배열의 값은 인덱스를 이용해서 접근할 수 있으며, 합은 단순하게 for문을 돌리면서 int 변수에 더해주면 된다.
최댓값의 경우, 0 값을 가지는 변수로부터 시작해서, for문을 돌면서 배열의 각 index의 값과 비교해서 큰 경우 해당 변수에 값을 저장하도록 하는 원리를 이용해서 구할 수 있다.
위 예제 코드상에서는 삼항 연산자로 작성했으나, if문 활용해서 작성도 가능하다.
최솟값은 최댓값과 반대로 작성하면 구할 수 있다.
Chapter 6.4 배열과 선택 정렬 selection sort
이번 챕터에서는 배열을 이용해서 선택 정렬을 배워본다.
예제 코드에 들어가기 전에, 선택 정렬(selection sort)가 어떻게 이루어지는지부터 설명하고, 이를 코드로 옮겼을 때 어떻게 구현이 가능한지 살펴본다.
예를 들어서 배열이 array = {3, 5, 2, 1, 4}로 구성되어 있다고 가정하자.
선택 정렬은 첫 번째 값과 그 이후에 있는 값들을 반복적으로 비교하면서 가장 작은 값을 찾고, 이를 서로 교체해준다.
그 다음으로는 두 번째 값과 그 이후에 있는 값들을 반복적으로 비교하면서 가장 작은 값을 찾고, 이를 서로 교체해준다.
이렇게 쭉 반복해서 마지막에서 두번째 값과 그 이후에 있는 값을 비교한 다음 작으면 교체해준다.
첫 번째 step에서는, 3과 그 이후의 5, 2, 1, 4와 비교를 하게 된다.
5는 3보다 크니 넘어가고, 2는 3보다 크니 교체 후보가 된다.
1은 2보다 크니 교체 후보가 되며, 4는 1보다 작으니 교체될 수 없다. 그래서 첫 번째 step에서는 3과 1을 교체한다.
그럼 두 번째 step에서는 array가 {1, 5, 2, 3, 4}로 바뀐 후 작업을 진행한다.
동일한 방식으로, 이번엔 5와 나머지 2, 3, 4과 비교를 하게 된다.
2가 5보다 크니 후보가 되고, 그 후에 3, 4는 2보다 크니 최종적으로는 2가 교체 후보가 된다.
다음 세 번째 step에서는 array가 {1, 2, 5, 3, 4}가 된다.
같은 방식으로 다음 단계에서는 {1, 2, 3, 5, 4}가 되고, 마지막으로는 {1, 2, 3, 4, 5}가 된다.
이를 코드로 구현하게 되면 다음과 같다.
const int length = 5;
int array[length] = { 3, 5, 2, 1, 4 };
printArray(array, length);
for (int i = 0; i < length - 1; i++)
{
int idx = i;
for (int j = i + 1; j < length; j++)
{
if (array[idx] > array[j])
{
idx = j; // 맨 처음 index보다 작을 때 마다 계속 갱신, 최종적으로 가장 작은 값의 index가 됨.
}
}
int tmp = array[i];
array[i] = array[idx];
array[idx] = tmp;
}
for문을 총 두개를 써야한다.
가장 메인으로 비교할 대상은 첫 번째, 두 번째, 세 번째 ,네 번째 있는 숫자로 이동하기 때문에 먼저 한 번의 for문이 필요하다.
그리고 메인으로 비교할 대상과 그 이후에 있는 숫자들을 비교해야 하니, 이 때 for문이 한번 더 필요하게 된다.
첫 번째 for문은 i = 0부터 length - 1 까지 진행되는데, 이는 배열의 마지막 요소는 비교할 대상이 없기 때문이다.
두 번째 for문은 j = i+1부터 length까지 진행된다.
메인으로 비교할 대상인 array[idx]와, 그 이후에 있는 array 요소들인 array[j]와 비교해서 만약 작으면, idx의 값을 바꿔준다.
이 작업을 계속 진행하면, 나머지 숫자들 중 가장 작은 숫자의 index를 얻을 수 있게 된다.
이렇게 해서 가장 작은 숫자의 index를 얻었다면, 기존 array[i]의 값을 tmp라는 변수에 저장한 다음, i번째 array 요소를 idx번째 array요소로 바꿔주고, idx번째 array 요소를 tmp 값으로 바꿔준다.
Chapter 6.5 정적 다차원 배열
이번 챕터에서는 기존 1차원 배열에서 확장하여, 다차원 배열에 대해서 다룬다.
#include <iostream>
using namespace std;
int main()
{
const int num_rows = 3;
const int num_columns = 5;
// row-major <-> column-major
// 두 번째 꺼는 꼭 값을 추가해줘야함.
// 첫 번째 꺼는 뺄 수 있음.
// int array[num_rows][num_columns] = {0}; // 이런식으로 전부 0으로 만들 수 있음.
int array[num_rows][num_columns] =
{
{1, 2, 3, 4, 5}, // row 0
{6, 7, 8, 9, 10}, // row 1
{11, 12, 13, 14, 15} // row 2
};
for (int row = 0; row < num_rows; row++)
{
for (int col = 0; col < num_columns; col++)
{
cout << array[row][col] << '\t';
//cout << (int)&array[row][col] << '\t'; // 실제로는 결국 1차원으로 이루어진 것을 접어서 표현한 것이다.
}
cout << endl;
}
}
1차원 배열을 선언했던 것과 비슷하게, 2차원 배열을 선언할 때는 array[3][5]와 같이 각각의 크기를 입력해주면 된다. 단, 2차원일 때는 왼쪽이 row이고 오른쪽이 column의 개수가 된다.
특이하게도 row는 빼도 되지만, column의 개수는 빼면 오류가 난다.
1차원 배열때와 비슷하게, 각각의 값은 { }를 이용해서 입력해주면 배열의 값을 채워줄 수 있다.
2차원 배열의 경우, 행과 열이 있는 표와 같은 형식이기 때문에 모든 요소를 출력하려면 for문을 row 쪽으로 한번, column 쪽으로 한번해서 총 두 번을 써야한다.
그리고 array 내 값들의 주소를 확인해보면, 배열이 실제로는 2차원이더라도 결국 본질적으로는 1차원이 이어져있는 형태임을 확인할 수 있었다.

첫 번째 row의 마지막 column이 9435320인데, 두 번째 row의 첫 번째 column은 9435324로, 4만큼 차이가 난다.
이 얘기는 결국 [0][0] -> [0][1] -> [0][2] -> [0][3] -> [0][4] -> [1][0] -> [1][1] -> [1][2] -> [1][3] -> [1][4] -> [2][0]... 이런식으로 연결되어 있음을 의미한다.
그저 1차원 배열을 잘 접어서 2차원처럼 보이도록만 만들어준 것이지 컴퓨터 내부적으로는 쭉 이어져있는 형태인 것이다.
Chapter 6.6 C언어 스타일의 배열 문자열
이번 챕터에서는 C언어 스타일로 문자열을 표현하는 방식을 배운다. 추후 문자열을 쓸 때는 std::string을 사용하지만, C언어 스타일의 문자열 사용방법도 중요하다고 한다.
예제 코드 1
char myString[] = "string";
// 마지막에 0이 나옴 -> Null character. 겹따옴표로 되어 있는 문자열은 \0이 하나 들어있음.
for (int i = 0; i < 7; i++)
{
cout << (int)myString[i] << endl;
}
cout << sizeof(myString) / sizeof(char) << endl;
char type으로 문자열을 선언한 다음, 해당 변수에 마우스를 올려보면 "string"인데도 크기가 7로 찍힌다.
string은 문자가 6개인데, 왜 7이 찍히는걸까?
이를 확인해보기 위해, for문을 이용해서 해당 char 변수의 각 자리에 어떤 문자열이 있는지 확인해본다.

확인해보면 마지막에 빈 문자열이 있는 것을 알 수 있는데, 이를 int로 casting해서 보면 다음과 같다.

이를 확인해보면, char 타입의 문자열은 가장 마지막에 int 기준으로 0인 Null character가 있는 것을 확인할 수 있다.
이처럼 겹따옴표로 되어 있는 문자열은 "\0" 이라고 하는 빈칸이 존재한다.
예제 코드 2
char myString[255];
cin >> myString;
myString[0] = 'A'; // 배열하고 똑같은 방식으로 처리할 수 있다.
cout << myString << endl;
int ix = 0;
while (1)
{
if (myString[ix] == '\0')
{
break;
}
cout << myString[ix] << " " << (int)myString[ix] << endl;
++ix;
}
이번에는 char type의 변수에 cin을 활용해서 문자열을 받아본다.
myString[0] = 'A';와 같은 방식을 통해서 cin을 통해 받은 문자열의 일부를 수정할 수 있다.

apple을 입력했을 때, Apple로 변하는 것을 확인할 수 있다.
예제 코드 3
char myString[255];
cin >> myString;
myString[4] = '\0'; // null character가 나오기 전까지만 출력하기 때문에, 이렇게 되면 그 이후 문자 끊김.
cout << myString << endl;
int ix = 0;
while (1)
{
if (myString[ix] == '\0')
{
break;
}
cout << myString[ix] << " " << (int)myString[ix] << endl;
++ix;
}
만약 문자열의 중간 위치쯤에 문자열을 \0로 바꾸면 어떻게 될까?

banana라는 문자열을 cin으로 받았을 때, myString[4] = '\0'로 바꾸면 4번째 문자열까지만 출력이 된다.
예제 코드 4
char myString[255];
std::cin.getline(myString, 50000);
cout << myString << endl;
int ix = 0;
while (1)
{
if (myString[ix] == '\0')
{
break;
}
cout << myString[ix] << " " << (int)myString[ix] << endl;
++ix;
}
만약 cin을 받을 때 띄어쓰기가 발생하더라도 문자열을 받아야 하는 상황이라면 어떻게 해야할까?
단순히 cin >> 으로 받을게 아니라, cin.getline을 이용해서 받는 방법이 있다.

apple banana를 입력했을 때, 처음부터 끝까지 다 들어오는 것을 확인할 수 있으며 중간에 빈칸은 int로 casting 했을 때 32인 것을 보면 null character와 다른 것을 알 수 있다.
예제 코드 5
#include <cstring>
char source[] = "Copy this!";
char dest[50];
strcpy_s(dest, 50, source); // 메모리 침범이 해킹이 될 수 있기 때문에 막아주기 위해서 최대 복사할 수 있는 메모리 사이즈를 강제로 적어주도록 함.
cout << source << endl;
cout << dest << endl;
C언어에서 많이 사용하게 되는 기능이라고 하는데, C++에서도 동일한 기능을 지원한다.
strcpy라는 함수는 source에 있는 문자열을 dest로 복사해준다.
단, 지금은 strcpy_s를 사용하여야 하고, destination의 사이즈를 명시해줘야한다.
이는 메모리 침범이 해킹이 될 수 있기 때문에 이를 막기 위해 최대로 복사할 수 있는 메모리 사이즈를 강제로 적어주도록 하는 것이라고 한다.

위 코드를 이용하면, 사이즈만 정의해준 dest라는 변수에 source와 동일한 문자열이 복사된 것을 확인할 수 있다.
예제 코드 6
#include <cstring>
char source[] = "Copy this!";
char dest[50];
strcpy_s(dest, 50, source); // 메모리 침범이 해킹이 될 수 있기 때문에 막아주기 위해서 최대 복사할 수 있는 메모리 사이즈를 강제로 적어주도록 함.
strcat_s(dest, source);
cout << source << endl;
cout << dest << endl;
cout << strcmp(source, dest) << endl;
strcpy와 비슷한 느낌으로, 문자열을 합쳐주는 기능을 가진 함수인 strcat도 사용해본다.

strcat_s를 사용하면 다음과 같이 source에 있는 문자를 dest 뒤에다가 합쳐준다.
strcmp는 두 문자열을 비교해주는 함수인데, 같으면 0을 리턴해주고, 동일하지 않으면 -1을 리턴해준다.
위 케이스에서는 dest와 source가 서로 다르므로, -1 값을 출력하게 된다.
Chapter 6.7 포인터의 기본적인 사용법
이번 챕터에서는 포인터에 대해서 다루게 된다.
예제 코드 1
int x = 5;
cout << x << endl;
cout << &x << endl; // & : address-of operator
cout << (int)&x << endl;
cout << *(&x) << endl;
변수를 선언한다는 것은, Operating System으로부터 변수를 선언할 공간을 빌려오는 것이다.
위 코드에서처럼, int x = 5; 라고 선언했다면 이것은 OS로부터 어떤 특정 메모리 공간을 빌려온 다음, 그 공간에 5라는 값을 복사해서 사용하는 것이다. 따라서 모든 변수는 내부적으로 메모리 주소를 가지고 있다.
&는 앰퍼샌드로, 변수의 주소를 알 수 있는 operator이다.

위 예시 코드 1번을 돌리면 위 사진처럼 나오게 되는데, 0096FBAC가 바로 x라는 변수의 메모리 주소라고 볼 수 있다.
*는 de-reference operator로, 포인터가 "저쪽 주소에 가면 이 데이터가 있어요"라고 가리키는 것에 직접적으로 접근해서 어떤 값이 있는지를 들여다보는 기능을 한다.
&x가 변수 x의 주소를 나타내기 때문에, *(&x) 는 x의 메모리 주소에 접근해서 어떤 값이 있는지를 확인하는 것이며, x가 5 이므로 5가 나오는 것을 확인할 수 있다.
포인터란?
포인터는 변수다. 메모리의 주소를 담는 변수다.
포인터는 왜 필요한가?
1) array에 데이터가 엄청 많을 때, 이 array를 함수 파라미터로 넣어주면 전부 모든 값을 다시 복사를 해야 함.
여기에 for문을 이용해서 여러 번 복사하면 엄청 느려지게 됨. 따라서 포인터로 첫 번째 주소하고 데이터의 개수만 알려주는 방식으로 효율적으로 사용할 수 있게 해줌.
2) 변수를 여기저기서 사용을 해야 될 경우가 있는데, 그때 매번 변수를 직접 보내면 복사를 해야 하니 부담이 된다.
예제 코드 2
int x = 5;
double d = 1.0;
int *ptr_x = &x; // 초기화 하지 않으면 de-reference 시도 시 에러 발생함.
double *ptr_d = &d;
cout << ptr_x << endl;
cout << *ptr_x << endl;
cout << ptr_d << endl;
cout << *ptr_d << endl;
cout << typeid(ptr_x).name() << endl;
cout << sizeof(x) << endl;
cout << sizeof(d) << endl;
cout << sizeof(&x) << " " << sizeof(ptr_x) << endl;
cout << sizeof(&d) << " " << sizeof(ptr_d) << endl;
포인터는 int *ptr_x = &x; 의 형식으로 사용한다.
포인터도 자료형을 가지고 있는데, 이는 추후 de-reference 할 때 어떤 자료형으로 값을 출력해줘야 하는지 알아야 하기 때문이다.

ptr_x를 출력하면, 00DAF7EC와 같은 메모리 주소 값이 나오는 것을 알 수 있다. 따라서 ptr_x라는 포인터 변수는 메모리 주소를 가지고 있는 변수이다.
다음으로 *ptr_x는 포인터 변수(메모리 주소)를 de-reference 한 것이므로 변수 x의 값인 5를 출력하게 된다.
ptr_d와 *ptr_d는 동일한 원리로 이루어진다.
그 다음으로 확인해볼 것은 sizeof 값이 어떻게 나오는지이다.
x는 int 변수이고, d는 double 변수 이기 때문에, sizeof를 사용하게 되면 각각 4와 8이 나오는 것을 확인할 수 있다.
그런데 신기하게도 &x와 &d, ptr_x, ptr_d는 모두 크기가 4이다.
주소는 말그대로 메모리 주소이기 때문에, 주소 자체를 저장하는 변수의 크기는 고정이기 때문이다.
32비트 운영체제에서는 포인터의 크기가 4이며, 64비트 운영체제에서는 포인터의 크기가 8이 된다.
Chapter 6.7a 널 포인터 Null Point
이번 챕터에서는 포인터 중 특수한 케이스인 널 포인터에 대해서 다룬다.
예제 코드 1
void doSomething(double *ptr)
{
if (ptr != nullptr)
{
// do something useful.
std::cout << *ptr << std::endl;
}
else
{
// 포인터 주소가 제대로 들어온게 아니구나. 아무것도 하지 말아야지.
// do nothing with ptr
std::cout << "Null ptr, do nothing" << std::endl;
}
}
int main()
{
//double *ptr = 0; // c-style로는 0을 넣어줌.
//double *ptr = NULL;
double *ptr = nullptr; // modern c++
doSomething(ptr);
doSomething(nullptr);
double d = 123.4;
doSomething(&d);
ptr = &d;
doSomething(ptr);
}
null pointer라는 것은, 포인터에 null이 들어가있는 경우를 의미한다.
포인터는 메모리 주소를 저장하는 변수이기 때문에, 포인터가 null이라는 것은 유효하지 않은, 아무것도 가리키지 않는 주소를 포인터가 담고 있는 경우라고 생각하면 된다.
double *ptr = 0; 으로 작성하거나, double *ptr = NULL;로 작성하거나, double *ptr = nullptr;로 작성할 수 있다. 가장 마지막인 nullptr가 가장 널리 사용되는 경우라고 한다.
포인터 변수가 유효한지를 확인하기 위해 if (ptr != nullptr)라는 조건문을 활용해서 점검할 수 있다.
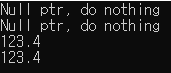
결과를 보면 알 수 있듯이, nullptr를 사용하면 (ptr != nullptr) 조건에 걸리지 않는 것을 볼 수 있고, double 변수인 d의 주소인 &d를 사용하거나, 이 주소를 저장하고 있는 변수인 ptr를 사용하게 되면 정상적으로 해당 조건에 걸리는 것을 확인할 수 있다.
예제 코드 2
void doSomething(double *ptr)
{
// 파라미터로 넘어오는 변수는 여기서 다시 선언이 되고
// argument로 들어온 변수에 들어있는 값이 복사가 되는것이다.
std::cout << "Address of pointer variable in doSomething() " << &ptr << std::endl;
std::cout << "ptr in func ? :" << ptr << std::endl;
if (ptr != nullptr)
{
// do something useful.
std::cout << *ptr << std::endl;
}
else
{
// 포인터 주소가 제대로 들어온게 아니구나. 아무것도 하지 말아야지.
// do nothing with ptr
std::cout << "Null ptr, do nothing" << std::endl;
}
}
int main()
{
double *ptr = nullptr; // modern c++
double d = 123.4;
ptr = &d;
doSomething(ptr);
std::cout << "Address of pointer variable in main() " << &ptr << std::endl;
std::cout << "ptr in main() ? :" << ptr << std::endl;
}

main() 안에서 확인해보면 ptr의 주소가 008FF7EC인 것을 알 수 있는데, 이를 doSomething 함수에 파라미터로 넣었을 때 doSomething 함수문 안에서 주소를 찍어보면 008FF7E8로 다른 주소가 찍히는 것을 확인할 수 있다.
이를 통해 알 수 있는 것은, 함수의 파라미터로 넘어오는 변수는 함수 내부에서 다시 선언이 되고, 파라미터로 들어온 변수에 들어있는 값이 복사가 되는 개념이라는 것이다.
main() 안에서 ptr의 값을 찍으면 008FF7F0인데, 동일한 방식으로 function 안에서 ptr의 값을 찍으면 동일하게 008FF7F0이 나오는 것을 확인할 수 있다.
즉, ptr이 가지고 있던 메모리 주소의 값은 함수의 파라미터로 넘어가면서 잘 전달이 된 것을 확인하였으나, ptr의 주소는 달라진 것이다.
이를 비유를 통해 표현하자면, ptr은 그릇이고 ptr이 가지고 있는 &d(메모리 주소)는 음식이다.
함수를 호출할 때, ptr를 전달하게 되면, 그릇이 다시 바뀌지만 안에 있는 음식은 그대로 유지해서 전달되는 상황인 것이다.
Chatper 6.8 포인터와 정적 배열
이번 챕터에서는 포인터와 정적 배열은 어떤 관계에 있는지에 대해서 알아본다.
사실상 포인터와 정적 배열은 같다.
예제 코드 1
int array[5] = { 9, 7, 5, 3, 1 };
for (int i = 0; i < size(array); i++)
{
cout << array[i] << endl;
}
// Array는 배열이 아니라 포인터이다.
// 포인터는 주소를 담고 있는데, 배열은 첫 번째 바이트의 주소를 담는다.
cout << array << endl;
cout << &(array[0]) << endl;
// de-reference 하면 첫 번째 배열의 값이 나옴.
cout << *array << endl;
int *ptr = array; //
cout << "ptr? : " << ptr << endl;
cout << "de-reference ptr? : " << *ptr << endl;
char name[] = "jackjack";
cout << *name << endl;

첫 번째 예제 코드에서는 포인터와 정적 배열의 관계에 대한 기본적인 내용들을 다룬다.
사실 이전 강의에서도 어느정도 다룬 내용들도 함께 포함되어 있다.
우선 정적 배열(array)의 요소들을 출력하려면 index를 통해서 접근하면 된다는 사실은 이미 이전에 나온 바가 있고, 이를 for문으로 구현해서 모든 배열의 요소를 출력해본 것이다.
array를 cout하면 배열의 주소가 나오는 것을 알 수 있고, 배열은 첫 번째 바이트의 주소를 담고 있기 때문에 첫 번째 요소의 주소를 출력하면 동일한 값을 얻을 수 있다. 이를 표현한게 &(array[0]) 라고 보면 된다.
이를 역으로 생각하면, 정적 배열의 주소를 dereference하게 되면 첫 번째 배열의 값을 구할 수 있다. 그래서 *array 를 cout하면 9라는 첫 번째 배열 값을 얻을 수 있다.
int형 pointer인 ptr를 선언하고, 여기에 array 값을 준다. 이러면 ptr은 array의 주소를 가지고 있게 된다.
따라서 ptr를 그대로 출력하면 array를 출력한 결과, &(array[0])를 출력한 결과와 동일하게 메모리 주소를 출력하게 된다.
그리고 ptr은 결국 배열 array의 주소를 가지고 있으니, ptr를 dereference해서 *ptr로 출력하면 *array한 것과 동일한 결과인 첫 번째 배열의 값인 9가 나오게 되는 것이다.
마지막으로는 간단하게 char type의 name이라는 배열을 만들어주고, 여기에 문자열을 주게 되면, 아까 숫자로 이루어진 배열과 동일하게 작동하는 것을 알 수 있다. 동일하게 name은 당연히 배열의 주소를 가지고 있고, 이를 dereference하게 되면 배열의 첫 번째 값을 얻을 수 있으니, 출력 결과는 문자열의 첫 번째 값인 j를 얻게 된다.
예제 코드 2
//void printArray(int array[]) // int array[]로 받아도 동일함
void printArray(int *array)
{
// array처럼 보이더라도 내부적으로는 포인터임.
cout << "size of array: " << sizeof(array) << endl;
cout << "De-referenceing: " << *array << endl;
*array = 100;
}
int main()
{
int array[5] = { 9, 7, 5, 3, 1 };
cout << sizeof(array) << endl; // int 4 byte x 5개 = 20
int *ptr = array;
cout << "size of ptr: " << sizeof(ptr) << endl; // 포인터 변수 자체의 사이즈가 4 byte
printArray(array);
// 함수 안에서 바뀐건데 함수 밖에서도 값이 변함.
for (int i = 0; i < size(array); i++)
{
cout << array[i] << endl;
}
// 포인터 연산(pointer arithmetic)
cout << *ptr << " " << *(ptr + 1) << endl;
}

먼저 sizeof(array)를 하게 되면, 배열의 size를 출력하는 것이기 때문에 int형 변수가 1개당 4 byte로, 5개가 있으니 20 byte라는 것을 알 수 있다.
int *ptr = array;로 해주면 ptr이라는 int형 pointer 변수에 array의 주소를 전달하게 되고, sizeof(ptr)은 포인터 변수의 사이즈를 묻는 것이니 4가 나온다. 이는 int형 pointer라서 그런게 아니라, 32비트 체계에서는 메모리 주소의 사이즈가 항상 4이기 떄문이다. 64비트로 바꾸면 8이 나오게 된다.
printArray 함수는 배열인 array의 주소를 array라는 변수 이름으로 전달 받는다.
printArray 함수 내 array라는 변수는 결국 포인터이니, 함수 내에서 sizeof(array)를 하면 포인터의 size를 묻는 코드라서 4가 나온다.
그리고 *array를 하게 되면 array 주소에 대해 dereference 하면 예제 코드 1번과 동일한 원리로 첫 번재 배열 값인 9를 얻을 수 있다.
printArray 함수 내에서 *array = 100;라는 코드가 있는데, 이는 array를 dereference한 결과에 100을 복사한 것이다.
array를 dereference하면 첫 번째 배열 값을 얻는 것이니, 결국 첫 번째 배열의 값을 100으로 바꿔주는 역할을 하는 것이다.
함수 내에서 *array의 값을 바꿔주더라도 main 문 안에서 array의 값을 뽑아보면 첫 번째 배열의 값이 100으로 변한 것을 확인할 수 있다.
마지막으로 포인터 연산이라는 부분이 있는데, *(ptr + 1) 으로 출력하면 두 번째 배열의 값을 얻을 수 있다.
예제 코드 3
struct MyStruct
{
int array[5] = { 9, 7, 5, 3, 1 };
};
// array가 struct나 class 안에 들어가있는 경우에는
// 포인터로 강제 변환이 되지 않는다. array 자체가 간다.
void doSomething(MyStruct ms)
{
cout << "doSomething size of ms array: " << sizeof(ms.array) << endl;
}
int main()
{
int array[5] = { 9, 7, 5, 3, 1 };
MyStruct ms;
cout << ms.array[0] << endl;
cout << "main () size of ms array: " << sizeof(ms.array) << endl;
doSomething(ms);
}

이번에는 array를 그냥 사용하는 경우가 아니라, 구조체 내부에 정의하는 경우이다.
MyStruct라는 구조체 타입으로 ms 변수를 정의하고, ms 내부에 있는 array에 접근할 때는 . 연산자를 이용하면 된다.
따라서 ms.array[0]로 접근하면 ms 내부에 있는 array의 첫 번째 요소를 얻을 수 있다. 그래서 결과가 9가 나오는 것이다.
sizeof(ms.array)를 출력하면 array의 크기를 알 수 있고, 20인 것을 확인할 수 있다.
정적 배열은 함수에 전달될 때 포인터로 전달되기 때문에 주소를 이용해서 전달이 되었는데, struct나 class의 경우는 포인터로 강제 변환이 되지 않는다. 따라서 ms.array로 출력이 바로 가능하다.
만약 ms 변수가 구조체로 전달되는 것이 아니라, 정적 배열처럼 전달이 되는 거였다면 결국 ms는 포인터이니, 포인터에 array가 없으므로 당연히 오류가 날 것이다.
따라서 doSomething 함수 내에서 ms에서 array를 직접적으로 바로 접근이 가능하다는 것은, ms가 포인터가 아니라는 것을 의미한다.
doSomething(&ms); 로 MyStruct 변수의 주소를 전달해주면,
doSomething의 파라미터로 MyStruct *ms로 바꿔주어 포인터 변수로 받아야하고,
이렇게 되는 경우 ms는 포인터가 되니, ms를 dereference 해서 구조체로 만들어준 다음 array를 접근해야하기 때문에 (*ms).array로 접근해야만 구조체 내부에 array에 접근할 수 있다.
Chapter 6.9 포인터 연산과 배열 인덱싱
이번 챕터에서는 포인터 연산에 대해서 알아본다. 이는 배열 인덱싱을 하던 것과 굉장히 유사한 방식으로 이루어진다.
예제 코드 1
int main()
{
double value = 7;
double *ptr = &value;
// ptr int형이면 4개씩, double형이면 8개씩 움직인다. short면 2개씩 움직임.
// pointer의 데이터 타입이 필요한 이유.
// 1) dereference 할 때 어떤 자료형으로 만들어줘야할지 알아야 하기 때문.
// 2) 포인터 연산을 할 때 1을 더한다고 하면 실제로 몇 바이트인지 알아야 하니까.
cout << uintptr_t(ptr) << endl;
cout << uintptr_t(ptr+1) << endl;
}

double형 변수인 value를 선언하고, value의 주소를 가지고 있는 변수인 ptr를 선언해준다.
uintptr_t는 메모리 주소를 int형 변수로 보여주기 위한 것으로, ptr의 메모리 주소를 보면 17823544이나 (ptr+1)의 메모리 주소를 보면 17823552인 것을 볼 수 있다.
이처럼 포인터 변수에 +1을 해주면 포인터의 자료형의 크기 만큼 이동하게 된다.
현재 ptr은 double형 변수이므로, 8 byte씩 이동하게 된다.
만약 ptr이 int형이였다면, 4 byte씩 이동하게 될 것이다.
이처럼 메모리의 주소를 담고 있는 포인터 변수에 연산을 할 수 있다.
예제 코드 2
int main()
{
int array[] = { 9, 7, 5, 3, 1 };
int *ptr = array;
for (int i = 0; i < 5; i++)
{
//cout << array[i] << " " << (uintptr_t)&array[i] << endl;
cout << *(ptr + i) << " " << (uintptr_t)(ptr + i) << endl;
}
}

int형 배열인 array를 선언해주고, array의 주소를 가지고 있을 int형 pointer 변수인 ptr를 선언해준다.
ptr + i를 dereference 하면 배열 내에서 for문을 돌면서 배열 내 요소들을 출력할 수 있고, 예제 코드 1번에서 포인터 연산을 보여주었듯이, ptr은 배열 array의 첫 번째 주소를 가지고 있으므로 ptr + i를 해주면 int형 변수이니 4 byte씩 이동하는 것을 확인할 수 있다.
예제 코드 3
int main()
{
char name[] = "Jack jack";
const int n_name = sizeof(name) / sizeof(name[0]);
char *ptr = name;
for (int i = 0; i < n_name; i++)
{
cout << *(name + i);
}
cout << " " << endl;
while (1)
{
if (*ptr == '\0')
{
break;
}
cout << *ptr;
ptr++;
}
}

이번에는 char type의 배열 name을 선언해주고, 배열 name의 메모리 주소를 가지고 있는 char type pointer 변수인 ptr를 선언해준다.
위 예제 코드하고 유사하게, name 변수는 배열 name의 첫 번째 메모리 주소를 가지고 있으니, (name + i)은 주소를 한 칸씩 이동하는 것이고, 이를 *를 통해서 dereferencing하게 되면 배열 name에 있는 문자열들을 for문을 이용해서 순차적으로 출력할 수 있다.
아래에 while문은 연습문제로 내주신 것인데, char 타입인 name은 맨 마지막에 우리 눈에는 보이지 않지만 null character를 가지고 있다는 특성이 있다.
따라서 이를 이용해서, while 문으로 무한 반복하게 만든 다음, null character가 발생했을 때 break를 하도록 만들면 반복해나가면서 문자열을 출력할 수 있다.
char type pointer인 ptr은 name의 첫 번째 메모리 주소를 가지고 있으니, *ptr를 하면 name의 첫 번째 요소인 J를 우선적으로 출력한다. 그 다음 ptr++를 해주면 ptr + i를 해주는 효과로, 메모리 주소상으로 한 칸씩 이동을 하게된다.
단 while의 경우 break를 반드시 해줘야하는데, break를 해주는 조건이 *ptr가 "\0"가 되는 경우이다. 따라서 이 조건을 추가해주게 되면 name에 있는 문자열을 모두 출력할 수 있다.
마지막에 while 문을 작성하는 연습문제를 해주면서, 사실 조금 헤매고 있었던 부분이 바로 *ptr == '\0'인지, 아니면 *ptr == "\0"인지 였다. 처음에 "\0"인줄 알고 작성했는데 계속 자료형이 맞지 않다고 해서 한참 고민했었는데, C++에서 작은따옴표와 큰따옴표가 다르다는 것을 제대로 알고 있지 못했다. 내가 주력으로 쓰는 python의 경우 두 케이스 모두 사실상 같은 것으로 인정되기 때문에 큰 차이 없이 사용할 수 있다.
따라서 이번 기회에 작은 따옴표와 큰 따옴표를 조금 정리하고 넘어가려고 한다. 아래 자료는 gemini를 사용해서 만든 자료이다.

작은따옴표의 경우 단일 char 타입이며, 문자 1개를 나타내는 것이다. 따라서 위 예제 코드에서 *ptr이 null character와 같은지 확인하기 위해서는 char type인 '\0'를 사용했어야 하는 것이다.
반면, 큰 따옴표의 경우 단일 문자가 아닌 문자열이며, 자료형은 const char*이다. 문자열은 마지막에 null character를 포함하고 있기 때문에 메모리 상에서 문자열 길이 + 1 바이트를 가지고 있게 된다.
분명 문자열을 사용하는 케이스가 많을태니, 두 따옴표 간 차이를 분명하게 알고 있어야겠다.
Chapter 6.10 C언어 스타일의 문자열 심볼릭 상수
이번 챕터에서는 문자열의 기호적 상수에 대해서 다루게 된다.
예제 코드 1
const char* getName()
{
return "Jack jack";
}
int main()
{
//char *name = "Jack Jack"; // 포인터는 메모리의 주소를 가리키기만 할 수 있기 때문에 불가능.
const char *name = "Jack Jack"; // 기호적인 상수처럼 사용할 수 있음. const 이용할 시
const char *name2 = "Jack Jack";
// const char*를 return하는 getName()을 이용해서도 동일하게 구현 가능.
//const char *name = getName();
//const char *name2 = getName();
cout << (uintptr_t)name << endl;
cout << (uintptr_t)name2 << endl;
}

앞에서 다루었듯이 포인터는 메모리 주소를 가지고 있는 변수이다. 따라서 pointer 변수에 문자열 값을 줄 수는 없다.
그런데 pointer 변수에 문자열 값을 줄 수 있는 방법이 있는데, 바로 const를 이용하는 것이다.
신기하게도 const char type으로 포인터를 선언하면 문자열을 줄 수 있다.
그리고 똑같은 문자열을 다른 이름의 포인터에 각각 주면, 두 변수가 모두 같은 위치의 메모리 주소를 가지고 있게 된다.
컴파일러가 name과 name2가 같으니, 메모리를 같이 쓰라고 하는 것이다.
만약 name2의 문자열을 name하고 다르게 만들어주면, 다른 메모리 주소를 가지고 있는 것을 확인할 수 있다.
추가로, const char type의 pointer를 return 해주는 함수인 getName()을 이용해서도 구현이 가능하다.
예제 코드 2
int main()
{
int int_arr[5] = { 1, 2, 3, 4, 5 };
char char_arr[] = "Hello, World!";
const char *name = "Jack Jack";
cout << int_arr << endl;
cout << char_arr << endl;
cout << name << endl;
}

앞 강의들에서 계속 언급했듯이, 배열은 포인터이다. 그래서 int_arr를 출력하게 되면 당연히 int_arr의 메모리 주소를 출력하는 것이 맞다.
그런데 char type인 char_arr는 cout으로 출력을 하면 char_arr의 메모리 주소를 출력하는 것이 아니라, 이 array가 가지고 있는 문자열을 그대로 출력해준다.
마찬가지로 const char 타입의 pointer인 name도 pointer임에도 불구하고 메모리 주소를 출력하는 것이 아니라 문자열을 그대로 출력해준다.
이는 cout에서 문자열은 특별히 처리를 하기 때문이다. 문자의 포인터가 들어왔을 때 이건 문자열이 아닐까? 하고서 메모리 주소를 출력하는 것이 아니라 array 자체를 쭉 출력해주게 되는 것이다.
예제 코드 3
int main()
{
char c = 'Q';
cout << &c << endl;
}
다음은 char type 변수의 주소를 cout으로 출력하면 어떻게 될까?

Q는 분명 잘 나왔는데, 그 이후에 이상한 문자가 섞여 나오는 것을 확인할 수 있다.
cout이 보기에는 문자열인가보다 하고 생각한 것이다. c가 문자열이라고 가정하고 null character가 나올 때까지 출력한 것인데, c는 실제론 문자열이 아니라 캐릭터 타입이다보니 그 뒤에 null character가 보장되지 않는 상황이다. 따라서 c 변수 이후의 메모리 영역에 접근하게 되고, 이 영역의 내용은 예측할 수 없다. 그래서 쓰레기 값이나 이상한 문자열이 출력될 수 있는 것이다.
Chapter 6이 워낙 길다보니, 6.1부터 6.10까지 전반부로 정리해보았다.
Chapter 6부터는 배열이나 포인터 등 중요한 내용들이 많이 나오고 있다보니 굉장히 흥미로운 것 같다.
챕터의 후반부는 다음 글에서 이어서 작성할 예정이다.
'C++ > 따라하며 배우는 C++' 카테고리의 다른 글
| 홍정모의 따라하며 배우는 C++ - Chapter 5 (1) | 2025.05.11 |
|---|---|
| 홍정모의 따라하며 배우는 C++ - Chapter 4 (0) | 2025.03.16 |
| 홍정모의 따라하며 배우는 C++ - Chapter 3 (0) | 2025.02.09 |
| C++ 공부 관련 정리글을 업로드 해보려고 합니다. (0) | 2025.02.02 |