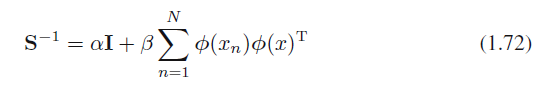안녕하세요.
오늘은 Anomaly Detection 분야의 논문 중, 최근에 나온 논문으로 제가 관심 있게 본 논문이라서 논문 review를 남기고자 합니다.
대학원에 있을 때는 새로운 논문이 나오면 바로 바로바로바로 follow-up 하곤 했는데, 회사에 다니고 나니 논문을 읽는 것 외에도 워낙 할게 많으니 바로바로 따라가기는 쉽지가 않네요.
그래도 제가 가장 관심 있는 분야라 시간이 되면 틈틈히 새로운 논문들 review 해보도록 하려고 합니다.
Official 코드가 나와있지 않은 관계로, 사람들이 unofficial로 implementation 코드를 만드시는 것 같은데 어느 정도 시간이 흐르고 결과가 유사하게 나오는 시점쯤이 되면 code review도 함께 진행해 보도록 하겠습니다.
https://arxiv.org/abs/2303.14535
EfficientAD: Accurate Visual Anomaly Detection at Millisecond-Level Latencies
Detecting anomalies in images is an important task, especially in real-time computer vision applications. In this work, we focus on computational efficiency and propose a lightweight feature extractor that processes an image in less than a millisecond on a
arxiv.org
1. Abstract
본 논문에서, 저자들은 computational efficiency에 집중하여 현대 GPU에서 1ms 이내로 이미지를 처리할 수 있는 lightweight feature extractor를 제안합니다. 그리고 anomalous feature를 검출하기 위해 stduent-teacher approach를 사용합니다.
저자들은 정상 이미지에서 추출된 feature를 예측하는 student network를 학습시킵니다.
Test time에서 anomaly의 검출은 student network가 추출된 feature를 예측하는데 실패하는 것을 통해 진행됩니다.
저자들은 정상이 아닌 이미지에 대해서 student network가 teacher network를 따라하지 못하도록 만드는 training loss를 제안합니다. 이는 student-teacher model의 computational cost를 대폭 감소시키면서 anomalous feature를 탐지하는 능력은 향상하게 됩니다.
저자들은 추가적으로 물건이 잘못 배치되는 것과 같은 logical anomaly를 잡아내는 문제 또한 다루고 있습니다. 저자들은 이러한 문제를 이미지를 전역적으로(globally) 분석하는 autoencoder를 효율적으로 활용해 검출하게 됩니다.
2. Introduction
최근 classification architecture들은 latency, throughput, memory consumption, 학습 가능한 파라미터의 수와 같은 특성들에 초점을 두고 있습니다. 이는 network들이 real-world application에 적용할 수 있다는 것을 보장하게 됩니다.
하지만, State-of-the-art anomaly detection 방법론들은, anomaly detection 성능을 증가시키기 위해서 computational efficiency를 희생하곤 합니다. 자주 사용되는 기법으로는 앙상블, large backbone의 사용, input image의 resolution을 768x768 사이즈로 올리는 방법들이 있습니다.
Real-world anomaly detection application에서는 방법론의 computational requirement에 제약이 있는 경우들이 많은데, 이는 anomaly를 너무 늦게 찾게 되면 상당한 경제적 피해를 가지고 오기 때문입니다. 예를 들어서, 금속 물질이 경작 기계의 내부에 들어간다거나, 혹은 기계를 작동하는 사람의 신체가 칼날에 접근하는 경우가 발생할 수 있습니다.
게다가 산업 현장에서의 환경은 높은 생산률을 유지하기 위해서 엄격한 runtime limit을 가지고 있는 경우가 많습니다. 따라서, 이러한 제약을 고려하지 않게 되면 생산성 감소를 만들 수 있고, 경제적 가능성을 감소시키게 됩니다.
그러므로, anomaly detection 방법론이 real-world에서 사용되려면 computational cost에 대해서 필수적으로 고려해야 합니다.
본 논문에서, 저자들은 anomaly detection 성능을 내면서도 inference runtime까지 동시에 고려하는, 새로운 표준이 될 방법론인 EfficientAD를 제안합니다.
첫 번째로, modern GPU에서 1ms 이내로 expressive feature를 계산하기 위한 efficient network architecture를 도입합니다.
두 번째로, anomalous feature를 검출하기 위해, student-teacher approach를 사용합니다.
저자들은 정상 이미지에 대해서 pretrained teacher network를 가지고 계산된 feature를 예측하는 student network를 학습합니다. Anomalous image에 대해서는 student network가 학습되지 않았기 때문에, 이러한 이미지에 대해서는 teacher network를 따라 하는 것에 실패하게 됩니다. 따라서, test time때 student network와 teacher network의 output 사이의 큰 distance를 기반으로 anomalous image를 검출하게 됩니다.
이러한 효과를 더 증가시키기 위해서, 'Asymmetric student-teacher networks for industrial anomaly detection' 논문에서는 teacher network와 student network간 architectural asymmetry를 사용하였는데요. 저자들은 대신에, 정상 이미지가 아닌 이미지에 대해서 student network가 teacher network를 따라 하지 못하게 만드는 training loss를 도입하여 loss-induced asymmetry를 도입하였습니다.
이 loss는 test time에서 computational cost에도 영향을 주지 않고, architecture design에 제약을 주지 않으며, anomalous feature를 정확히 검출하면서도 student network와 teacher network 모두에 efficient network architecture를 사용할 수 있게 만듭니다.
Anomalous local feature를 확인하는 것은 생산된 제품에 오염이나 얼룩과 같이, 정상 이미지와 구조적으로 다른(structurally different) anomaly를 검출하게 합니다. 하지만, 어려운 문제는 정상 이미지의 position, size, arrangement와 관련된 logical constraint에 대한 이상 여부를 찾아내는 것입니다. 이러한 문제를 해결하고자, EfficientAD는 'Beyond Dents and Scratches: Logical Constraints in Unsupervised Anomaly Detection and Localization' 논문에서 제안된 autoencoder를 사용합니다. 이 autoencoder는 test time에서 학습 이미지의 logical constraint를 학습하고, violation을 탐지하게 됩니다.
저자들은 autoencoder의 구조와 학습 protocol을 단순화 하면서, 어떻게 이를 student-teacher model과 효율적으로 통합할 수 있는지를 논문에서 설명합니다. 또한, autoencoder와 student-teacher model의 detection result를 합치기 전에 보정해서 anomaly detection 성능을 향상할 수 있는 방법 또한 제안합니다.
저자들의 contribution은 다음과 같이 요약해볼 수 있습니다.
- 이미지 한 장당 2ms 이내의 latency를 보여주면서, industrial benchmark에 대해서 anomaly detection과 localization에서 SOTA 대비 상당히 성능을 향상했습니다.
- 최근 anomaly detection 방법론들과 비교했을 때 feature extraction의 속도를 몇 배 향상할 수 있는 efficient network architecture를 제안합니다.
- Inference runtime에 영향을 미치지 않으면서 student-teacher model의 이상 탐지 성능을 상당히 향상시킬 수 있는 training loss를 도입합니다.
- autoencoder 기반으로 효율적으로 logical anomaly를 검출하고, student-teacher model의 검출 결과와 통합한 후 보정할 수 있는 방법을 제안합니다.
3. Related Work
3.1 Anomaly Detection Tasks
간단한 내용이라서, 해당 글에서는 생략하겠습니다.
3.2 Anomaly Detection Methods
전통적인 컴퓨터 비전 알고리즘은 수십 년간 산업용 이상 탐지 문제에 성공적으로 적용되어 왔습니다. 이러한 알고리즘들은 흔히 이미지 한 장당 몇 ms 이내에 이미지를 처리해야 하는 요구사항을 충족해 왔습니다. Bergmann는 이러한 방법론들을 평가해 보았고, 사물이 똑바로 위치해있지 않은 경우에는 실패한다는 것을 확인하였습니다.
딥러닝 기반의 방법론들은 이러한 케이스에서도 강건하게 작동한다는 것을 보여왔습니다. 최근에 성공적인 방법론들은 pretrained 되고 frozen 된 CNN의 feature space에서 밀도 추정을 하거나 outlier를 검출합니다. 만약 feature vector가 input pixel에 매핑될 수 있다면, 이들의 outlier score를 각각의 pixel에 할당해서 2D anomaly map을 만들 수 있게 됩니다.
최근 방법들은 다변량 정규 분포, Gaussian Mixture Models, Normalizing Flow, kNN 알고리즘을 사용하곤 합니다. kNN은 Nearest Neighbor를 찾는 것에 있어서 runtime을 많이 잡아먹게 되는데, PatchCore는 이를 해결하고자 군집된 feature vector들의 reduced database를 만들어서 여기서만 kNN을 진행하도록 합니다.
Bergmann은 이상 탐지를 위한 student-teacher (S-T) framework를 제안하였습니다. 여기서 teacher network는 pretrained frozen CNN입니다. 해당 연구에서는 3가지 다른 receptive field 크기를 가진 teacher network를 사용합니다. 각 teacher network는 학습 이미지에서 teacher network의 output을 따라 하는 3개의 student network를 학습시킵니다.
student network는 이상이 있는 이미지를 학습하는 동안에 본 적 없기 때문에, 이들에 대해서는 teacher network의 output을 예측하는 것에 실패하기 때문에 이를 기반으로 이상 탐지가 가능합니다. Bergmann은 student network의 output의 variance와 teacher network의 output 간의 distance를 가지고 anomaly score를 계산하였습니다.
S-T framework의 다양한 변형 버전들이 제안되어 왔는데요. Rudolph는 teacher network의 구조를 invertible neural network로 제한시켜서 PatchCore에 버금가는 이상 탐지 성능에 도달하는 데 성공하기도 하였습니다. 본 논문에서는 Asymmetric Student Teacher (AST) 모델과 original S-T method, 그리고 EfficientAD를 비교합니다.
autoencoder나 GAN과 같은 생성 모델 또한 이상 탐지를 위해서 범용적으로 사용되어 왔습니다. 최근 autoencoder 기반의 방법들은 정상 이미지에 대해서는 정확한 복원을, 비정상 이미지에 대해서는 부정확한 복원을 한다는 것에 의존하고 있습니다. 이는 input image에 대한 복원 결과와 비교해서 이상 이미지를 찾아낼 수 있게 만들어줍니다.
이러한 접근법에서 발생하는 흔한 문제는 정상 이미지에 대한 부정확한 복원으로 인해 발생하는 false-positive detection 문제입니다. (정상인데 비정상으로 탐지되는 것이라고 이해하시면 됩니다.) 이를 피하고자, Bergmann은 autoencoder가 pretrained network의 feature space에서 이미지를 복원하도록 하였습니다. 게다가 해당 논문에서는 autoencoder의 output을 예측하는 neural network를 학습시켰는데, 이 network는 normal image에 대한 systematic reconstruction error도 학습하게 됩니다. (논문에서 이 systematic reconstruction error에 대한 설명이 막 자세하진 않은데, 제가 이해하기로는 autoencoder의 output에서 나타나는 global한/거시적인 경향성을 의미하는 것 같습니다. autoencoder의 복원 결과가 전반적으로 흐릿하다면, 이것의 output을 예측하도록 학습된 모델 또한 전반적으로 흐릿한 결과를 뽑게 된다는 것입니다.)
4. Method
저자들은 다음 subsection들에서 EfficientAD의 각 요소들을 설명하고 있습니다. 4.1에서는 pretrained neural network로부터 나오는 feature를 어떻게 효율적으로 추출할 것인지를 다룹니다. 4.2에서는 test time에서 student-teacher model을 사용해서 어떻게 anomalous feature를 검출하는지에 대해서 다룹니다. 주된 난관은 전체적인 runtime을 낮게 가져가면서도 경쟁력 있는 이상 탐지 성능을 가지는 것이었는데요. 이를 위해 student-teacher network를 학습하기 위한 loss function을 도입하였습니다. 이는 inference 시 연산량에 영향을 주지 않으면서 이상 탐지의 성능을 향상하게 됩니다.
4.3에서는 autoencoder 기반의 접근법을 사용해서 어떻게 logical anomaly를 잡는지를 설명합니다. 4.4에서는 student-teacher model과 autoencoder의 탐지 결과를 어떻게 결합하고 보정하는지에 대해서 설명하게 됩니다.
4.1 Efficient Patch Descriptors
최근 이상 탐지 방법들은 보통 WideResNet-101와 같은 pretrained network를 사용하는데요. 저자들은 깊이가 극단적으로 줄여진 네트워크를 feature extractor로 사용합니다. 이는 단 4개의 conv layer로 구성됩니다. 구조는 아래 Figure 2를 참고하시면 됩니다.
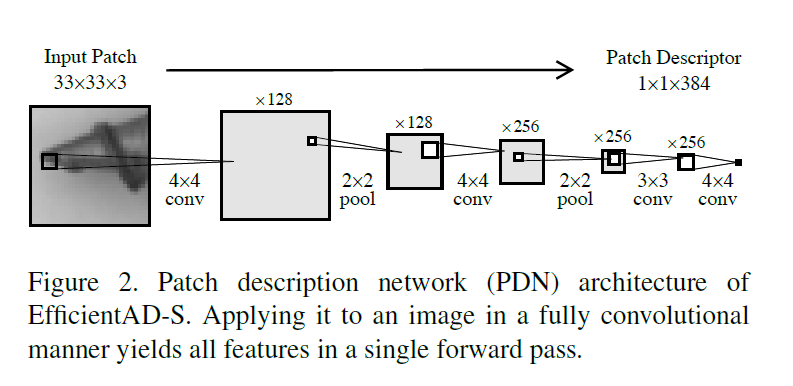
각 output 뉴런은 33x33 pixel의 receptive field를 가지고 있기 때문에, output feature vector의 각 요소들은 33x33 patch를 설명하게 됩니다. 이렇게 명확하게 대응되기 때문에, 저자들은 이 네트워크를 patch description network (PDN)이라고 명명했습니다. PDN는 한 번의 forward pass에 가변적인 사이즈의 이미지에서도 feature vector를 뽑아낼 수 있습니다.
'Uninformed Students: Student-Teacher Anomaly Detection With Discriminative Latent Embeddings' 논문에서도 유사하게 몇 개의 conv layer로만 이루어진 네트워크를 사용해서 feature를 뽑았는데요. 이러한 네트워크는 downsampling과 pooling이 없다 보니 꽤 높은 연산량을 요구했습니다.
해당 논문에서 사용된 네트워크의 파라미터 수가 1.6 million에서 2.7 million 정도로 비교적 낮았지만, GCAD에서 사용했던 31 million 파라미터를 가진 U-Net보다도 시간도 오래 걸리고 메모리도 더 요구하는 것을 실험적으로 확인했습니다. 이는 파라미터의 수가 특정 방법론의 latency, throughput, memory footprint에 대한 적절치 못한 metric이라는 것을 의미한다고 합니다.
최근 classification architecture들은 대부분 downsampling을 초기에 적용해서 feature map 사이즈를 줄이고, 시간 및 공간 복잡도를 감소시키는 편입니다. 저자들도 유사한 방식을 PDN에 적용, NVIDIA RTX A6000 GPU 기준 256x256 사이즈 이미지에서 feature를 얻는데 800μs가 소요된다고 합니다. (800μs = 0.8ms라고 보시면 됩니다.)
PDN이 expressive feature를 만들게 하기 위해서, 저자들은 deep pretrained classification network를 활용해 knowledge distillation를 적용합니다. ImageNet에 있는 이미지에 대해서 pretrained network에서 뽑은 feature와 PDN의 output 간의 MSE가 최소화되도록 학습이 진행됩니다.
PDN은 매우 효율적인 것 외에도, 일반 deep network를 사용하는 것과 비교했을 때 또 다른 이점이 있는데요. PDN에서 만들어진 feature vector는 각 픽셀에 대응되는 33x33 patch에만 의존한다는 것입니다. 반면에, pretrained classifier에서 나온 feature는 이미지의 다른 부분에도 long-range dependency를 가지게 되죠. 이는 Figure 3을 보면 확인할 수 있습니다.
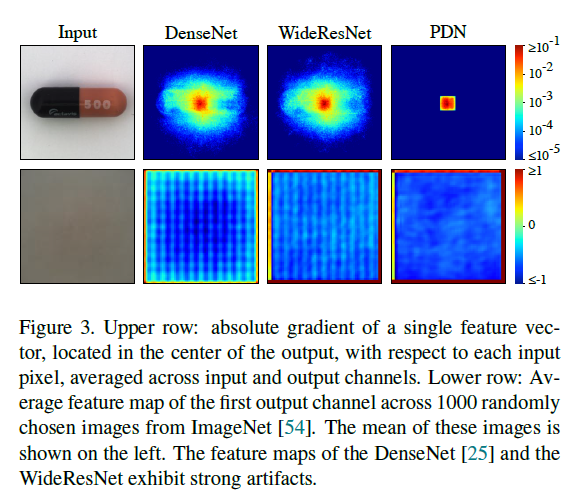
Figure 3의 위쪽 행은 output의 중심부에 위치한 1개의 feature vector에 대해서 각 input pixel에 대한 gradient를 나타낸 것입니다. 예를 들어서 모델의 output이 28x28이라고 하면, 아마 (14, 14)에 위치한 feature vector를 얘기하는 것 같은데요. 해당 vector 값에 대한 각 input pixel의 gradient 값을 시각화한 것으로 보입니다.
DenseNet이나 WideResNet을 보시면, 해당 feature vector에 대한 gradient가 input image의 정중앙 pixel 외에도 꽤나 넓은 범위에 걸쳐서 분포해 있는 것을 알 수 있습니다. 위에서 언급된 대로, 이미지의 다른 부분에도 dependency가 있다는 게 바로 이런 의미입니다. 반면에, PDN은 매우 국소 부위만 영향을 미치는 것을 알 수 있으며, 이미지의 나머지 부위들은 gradient가 아주 작은 값인 것으로 보입니다.
이렇게 PDN은 well-defined receptive field를 가지고 있기 때문에, 이미지의 다른 부분들로 인해서 anomaly localization에 악영향을 주는 경우가 없을 것이라고 밝히고 있습니다.
4.2 Reduced Student-Teacher
anomalous feature vector를 탐지하기 위해서 teacher network로는 distilled PDN을 사용하고, 동일한 architecture를 student에도 그대로 적용합니다. 이를 통해서 1ms 이내로 feature를 뽑을 수 있게 됩니다.
그런데, 최근 모델들이 anomaly detection performance를 증가시키고자 사용한 방법들, 예를 들어 여러 개의 teacher network와 student network를 앙상블 한다던가, student와 teacher 간의 architectural asymmetry를 활용한다거나 하는 테크닉이 적용되지 않았습니다. 따라서, 저자들은 연산량에 영향을 주지 않으면서도 성능을 높이는 training loss를 도입했습니다.
저자들은 일반적인 S-T framework에서 학습 이미지의 수를 증가시키면 이상 이미지에 대해서 teacher network를 모방하는 능력이 향상되는 것을 확인했다고 합니다. 이는 이상 탐지 성능을 악화시키죠. 그렇다고 해서 학습 이미지 수를 너무 많이 줄이면 정상 이미지에 대한 중요한 정보를 얻지 못하게 될 수 있죠. 그래서 저자들은 student network에 충분한 이미지를 제공해서 정상 이미지에 대해서는 teacher network를 잘 모방하도록 만들면서, 동시에 anomalous image에 대해서 generalization 하지 못하도록 만들어보고자 했다고 합니다.
Online Hard Example Mining과 유사하게, 저자들은 student network가 teacher network를 가장 잘 못 따라 하는 부분만 loss에 영향을 주도록 했습니다. 즉, 가장 높은 loss값을 가진 output element만을 loss에 활용한다는 것입니다.
이를 수식으로 표현하자면, teacher network $T$와 student network $S$가 있고 training image $I$가 있으면, 각각은 $T(I) \in R^{C \times W \times H}$, $S(I) \in R^{C \times W \times H}$를 만들어 내게 됩니다. 각 $(c, w, h)$에 대해서 squared difference는 $D_{c, w, h} = (T(I)_{c, w, h} - S(I)_{c, w, h})^2$로 계산됩니다.
mining factor $p_{hard} \in [0, 1]$을 기반으로, $D$에서 $p_{hard}$ quantile을 계산합니다. 이를 $d_{hard}$로 표현하고요. 위에서 구한 $D_{c, w, h}$에서 $d_{hard}$보다 크거나 같은 요소들의 평균을 training loss인 $L_{hard}$로 사용하게 됩니다.
$p_{hard}$의 의미를 생각해 보면, 이를 0으로 했을 땐 일반적인 S-T loss라고 이해할 수 있죠. 실제로 저자들의 실험에서는, 이 값을 0.999로 지정했다고 합니다. 99.9 분위수라고 하니, 매우 높은 값 일부만 사용한 것을 알 수 있습니다. 이 $p_{hard}$의 효과는 Figure 4에서 볼 수 있습니다.

hard feature loss를 사용하는 효과를 위 사진에서 볼 수 있는데요. 밝기는 backprop을 위해 사용된 feature vector의 차원이 얼마나 사용되었는지를 나타내고 있습니다. 못과 관련이 없는 background에는 하얀 요소들이 없는 것을 확인할 수 있으며, 이는 backprop에 사용되는 요소들이 없다는 것을 의미하고, stduent network의 output과 teacher network의 output 간의 difference가 적다는 것을 확인할 수 있습니다. 그래서 우리가 학습해야 할 사물 쪽 요소만 학습을 진행하게 됩니다.
Inference를 진행할 때 2D anomaly map $M \in R^{W \times H}$은 $M_{w, h} = C^{-1}\Sigma_{c}D_{c, w, h}$로 계산되며, 이는 채널 기반으로 평균을 낸 것이라고 이해하시면 되겠습니다. (표기상 $C^{-1}$로 표기 되어 마치 matrix처럼 보일 수 있지만, 실제로 $C$는 차원의 수 이기 때문에 512와 같은 int입니다. 그래서 실제로는 1/512와 같이 int 값의 역수라고 이해하시면 됩니다.)
추가적으로, hard feature loss를 적용하면 normal image에 대해서 false-positive detection이 발생하는 경우를 피할 수 있는 장점도 있습니다. (정상이 anomaly로 탐지되는 것을 의미합니다.)
hard feature loss 외에도, 저자들은 loss penalty라는 것을 추가로 적용했는데요. 이는 학습 중에 student가 normal training image에 없는 이미지에 대해서 teacher를 따라 하는 것을 방해하기 위해 적용한다고 합니다. 제가 생각하기에는 조금 독특하다고 느꼈는데, student network의 학습 도중에 teacher network의 pretraining때 사용된 이미지를 학습에 사용합니다. 즉 ImageNet에 있는 이미지 중에 랜덤 하게 뽑아서 이를 학습에 활용한다는 것이지요.
이를 반영한 loss를 계산하면, $L_{ST} = L_{hard} + (CWH)^{-1}\Sigma_{c} \parallel S(P)_{c}\parallel^{2}_{F}$로 계산이 됩니다. 이 penalty는 out-of-distribution image에 대해서 student network가 teacher network를 모방하지 못하게 막는 역할을 합니다. 수식이 조금 어려워 보일 순 있지만, ImageNet에서 뽑은 임의의 이미지가 $P$이고, student network가 $S$이니, $S(P)$는 이미지를 넣어서 나온 output이라고 보시면 됩니다. 이를 제곱을 해주고 channel 기준으로 sum한 다음, $CWH$로 나눠줍니다. 앞에서도 언급드렸지만, $CWH$는 matrix가 아니고 int입니다.
4.3 Logical Anomaly Detection
anomaly 중에서 logical anomaly가 발생할 가능성을 배제할 수는 없는데요. logical anomaly는 물체가 잘못 위치해 있다거나 하는 경우를 얘기합니다. 그래서 이런 경우들까지 탐지할 수 있어야 합니다. 'Beyond Dents and Scratches: Logical Constraintsin Unsupervised Anomaly Detection and Localization.' 논문에서 제안된 것처럼, 저자들은 이를 잡아내기 위한 용도로 autoencoder를 사용합니다. Figure 5에 EfficientAD의 전체 방법론을 나타내주고 있습니다.
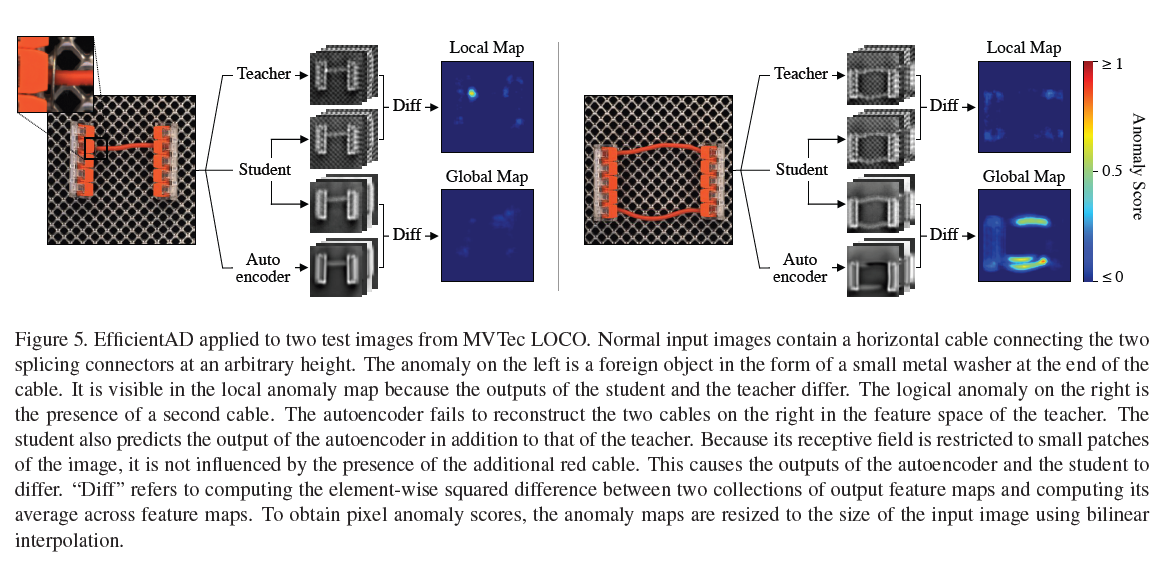
Figure 5를 확인해 보면, 앞에서 언급했던 student-teacher pair가 있고, 방금 전에 얘기한 autoencoder를 활용하는 것을 볼 수 있죠. autoencoder는 teacher network의 output을 예측하도록 학습된다고 합니다. 이를 수식으로 표현하자면, 이렇게 표현할 수 있습니다. Autoencoder는 $A$, training image $I$, 이를 활용하면 $A(I) \in R^{C \times W \times H}$를 output으로 뽑게 되죠. 그리고 autoencoder를 학습하는 데 사용할 loss는 $L_{AE} = (CWH)^{-1}\Sigma_{c}\parallel T(I)_{c} - A(I)_{c} \parallel^2_{F}$로 계산할 수 있습니다. $T$는 teacher network라고 하였으니, teacher network의 output과 autoencoder의 output 간 차이를 제곱해서 이를 평균 낸 값이라고 볼 수 있죠. 일반적인 autoencoder 학습에 사용하는 loss와 동일합니다.
student는 PDN이라는 것을 앞에서 언급했었는데요. student는 patch 기반의 network지만, autoencoder는 이미지 전체를 encode 하고 decode 하고 있습니다. 그래서 logical anomaly가 발생한 이미지에 대해서는 autoencoder가 복원을 제대로 못합니다. 하지만, 이러한 문제가 정상 이미지에도 발생하는데요. 이는 autoencoder가 fine-grained pattern 복원을 어려워하기 때문입니다. 이는 Figure 5에서도 확인할 수 있죠.
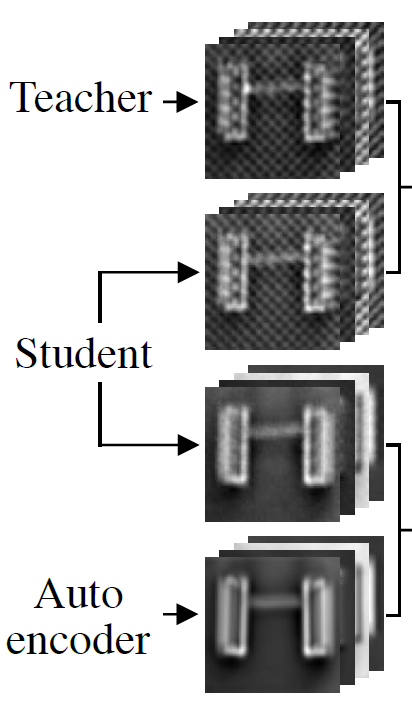
앞에서 언급했듯이, autoencoder는 teacher network의 output을 유사하게 따라가도록 학습되어 있는데요. 보시면 autoencoder에서 나온 output은 background에 있는 패턴들은 복원이 안된 걸 볼 수 있습니다. 이 부분을 얘기한다고 이해하시면 됩니다.
이런 문제 때문에 teacher network의 output과 autoencoder의 output 간 차이를 그대로 anomaly map으로 활용하기에는 false-positive가 발생할 수 있다고 합니다. 따라서, 저자들은 student network의 output channel의 수를 두배로 늘리고, 이를 autoencoder의 output과 teacher network의 output를 예측하도록 학습하도록 한다고 합니다.
이를 수식으로 표현하자면, $S'(I) \in R^{C \times W \times H}$가 student의 추가적인 output channel이라고 했을 때, student의 추가적인 loss는 다음과 같이 정의됩니다. $L_{STAE} = (CWH)^{-1}\Sigma_{c}\parallel A(I)_{c}-S'(I)_{c}\parallel^{2}_{F}$. 결론적으로 전체 training loss는 $L_{AE}$, $L_{ST}$, $L_{STAE}$의 합이라고 합니다.
이렇게 학습하면 student network는 autoencoder의 정상 이미지에 대한 systematic reconstruction error(예를 들면, 전체적으로 blurry 하게 복원되는 것)은 학습하면서, 동시에 anomaly에 대해서 발생하는 reconstruction error는 학습을 못하게 됩니다. 따라서, autoencoder의 output과 student network의 output 간 차이는 anomaly map으로 활용할 수 있게 됩니다. 이는 global anomaly map으로 부르게 되고요.
student network의 output과 teacher network의 output간 square difference를 계산하고, 이를 channel 기준으로 평균을 내서 이를 local anomaly map으로 활용합니다. 이 두 anomaly map을 결합해서 활용하고, maximum value를 image-level anomaly score로 활용합니다.
4.4 Anomaly Map Normalization
local과 global anomaly map이 있기 때문에, 이 둘을 통합해서 사용하기 전에 유사한 scale로 변경이 필요합니다. 이는 Figure 5에 나타난 것처럼, 양쪽 anomaly map 중에서 한쪽에서만 anomaly가 검출되었을 경우 중요하게 된다고 합니다. 그 외에도, 한 map에서의 noise가 결합된 map에서 정확하게 탐지하는 것이 어렵게 만들 수 있습니다.
정상 이미지에서의 noise의 scale을 추정하기 위해서 validation image를 별도로 사용한다고 합니다. 이들은 학습 셋에는 없는 이미지고요. 두 가지 anomaly map 각각에 대해서, validation image 전체에 대해서 모든 pixel anomaly score를 계산합니다. 그러고 나서 각각 계산된 pixel anomaly score(local, global)에 대해서 두 개의 $p$ qunatiles를 계산하는데, $q_{a}$는 anomaly score 0에 맵핑되고, $q_{b}$는 0.1에 맵핑되는 값입니다. test time에는, 계산된 각각의 맵핑에 맞춰서 normalized 된다고 보시면 됩니다. 뒤에 experiment 부분에서 보면, $q_{a}$는 0.9 quantile, $q_{b}$는 0.995 quantile을 선택해서 사용하는 것을 알 수 있습니다.
5. Experiments
실험 부분은 아주 간단하게만 정리하고 넘어가려고 합니다. 크게 EfficientAD-S와 EfficientAD-M이 있다는 점만 알아두시면 되고, EfficientAD-M은 conv layer의 커널 수를 두배로 늘린 것입니다. 뒤에 보시면 S와 M 각각 레이어 구성에 대해서도 다 자세히 나와 있습니다. 실험은 MVTec AD, VisA, MVTec LOCO 데이터셋에서 진행하였고요.
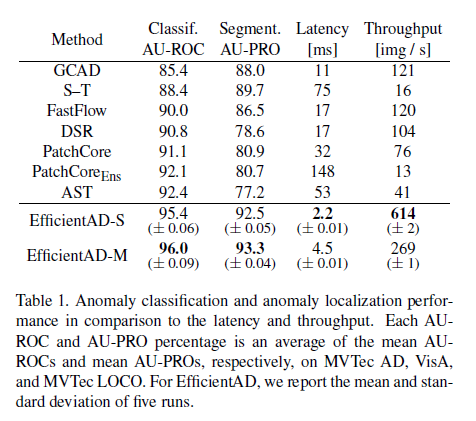
Table 1은 3개의 데이터 셋 전체에 대해서 평균 성능을 보여주고 있고, 나머지 방법론에 비해서 EfficientAD가 좋은 성능을 낸다는 점을 확인할 수 있습니다.
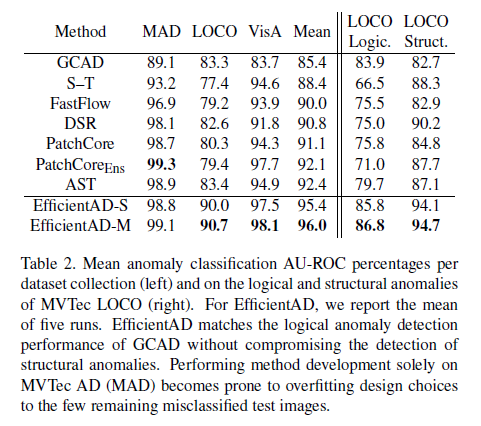
Table 1에 대한 세부적인 내용이 Table 2에 적혀있네요. MVTec AD에 대해서는 PatchCore, PatchCore ensemble, AST 모두 98 후반대가 나오고 있어서 이미 성능 기준으로는 saturation 된 상황인데, MVTec AD LOCO 데이터셋에 대해서 성능 차이가 심합니다. 아마 LOCO는 logical anomaly가 많아서, 기존 방법론으로는 탐지가 어려운 것이 아닐까 생각됩니다. 그래서 3개 데이터 셋에 대한 평균을 내니까 EfficientAD가 SOTA로 찍히는 모습입니다.
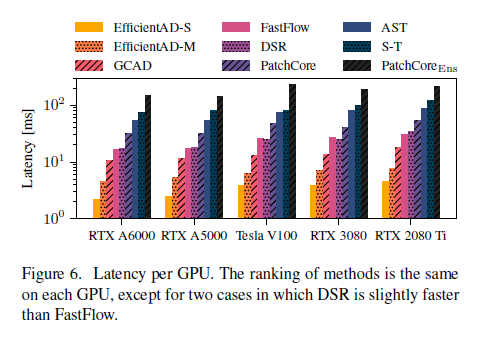
여러 가지 GPU에 대해서 Latency를 비교한 표입니다. EfficientAD가 가장 낮은 수준을 나타내고 있습니다.
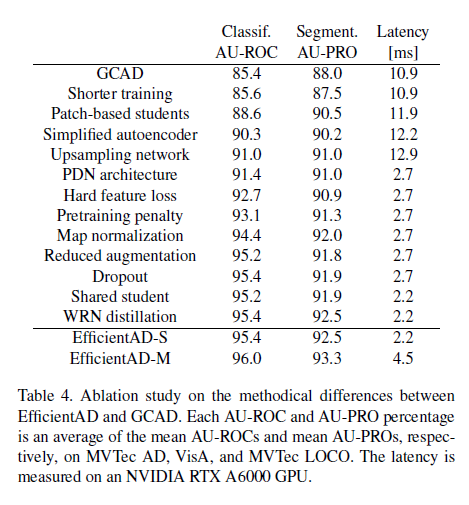
Table 4는 GCAD라는 모델에서 Ablation study를 진행한 모습입니다. 각각의 요소를 반영할 때마다 성능의 변화와, Latency의 변화를 보여주고 있습니다. 이 부분을 제대로 이해하려면 GCAD라는 모델에 대해서도 자세히 알면 더욱 이해하기가 쉽겠네요. 저는 아직 읽어본 논문이 아니라서 대략 감만 잡는 정도로 읽고 넘어갔습니다.
6. Conclusion
강력한 이상 탐지 성능과 매우 높은 연산 효율성으로 무장한 EfficientAD를 소개하는 논문이었습니다. 이는 logical anomaly와 structural anomaly를 모두 탐지하는 새로운 표준이 될 것으로 보이고요.
강력한 이상 탐지 성능과 높은 연산 효율성을 기반으로 하면 이를 실제 application 환경에서 적용하기에 좋을 것으로 보이네요. 추가로 논문에서 제안한 PDN를 활용하면, 다른 이상 탐지 방법론에서도 latency를 줄이는데 도움이 될 것이라고 합니다.
7. Limitations
Student-teacher model과 autoencoder는 각각 다른 유형의 anomaly를 탐지하도록 설계가 되어 있는데요. Autoencoder는 logical anomaly를, student-teacher network는 fine-grained structural anomaly를 탐지하는 역할입니다. 하지만, fine-grained logical anomaly는 여전히 도전적인 문제로 남아 있는데요. 예를 들면 2mm만큼 더 긴 나사 같은 게 있겠죠. 이런 것들을 잡아내려면, 전통적인 측량 방법론들을 사용해야 한다고 합니다.
최근 이상 탐지 방법론들과 비교했을 때 한계점으로는, kNN 기반 방법론들과는 대조적으로 autoencoder를 별도로 학습해야 합니다.
여기까지 해서 EfficientAD 논문을 정리해 보았습니다.
기존 방법론들이 단순히 pretrained CNN model에서 feature extraction을 하던 것에서 knowledge distillation을 통해 더 단순한 모델을 활용해서 feature extraction이 가능하도록 만들었다는 점이 굉장히 인상적이었고요.
또 일반적인 결함 외에도 logical anomaly까지 잡아내기 위해서 autoencoder까지 end-to-end로 연결한 process를 만들었다는 점도 흥미로웠던 것 같습니다.
논문 내용을 어느 정도 이해하셨다면, 논문 뒤에 있는 Appendix A을 확인해 보시면 전체 프로세스를 pseudo-code 형식으로 정리한 내용이 있습니다. 논문에서 언급된 요소들이 실제 어떤 흐름으로 진행되는지를 확인하실 수 있습니다.
추후 또 흥미로운 이상 탐지 논문을 발견하게 되면 리뷰를 진행해 보겠습니다.
감사합니다.
'딥러닝 & 머신러닝 > 논문 review' 카테고리의 다른 글
| ArcFace: Additive Angular Margin Loss for Deep Face Recognition(2019) review (8) | 2020.08.14 |
|---|