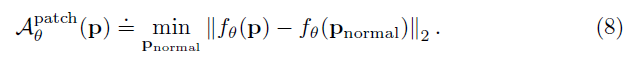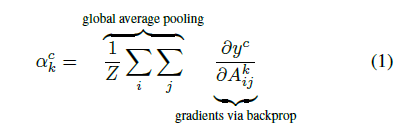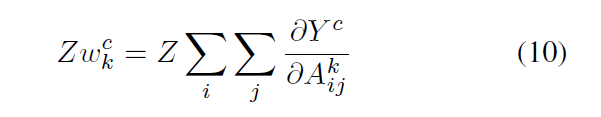저자들은 본 논문에서 mobile과 embedding vision applications에서 사용할 수 있는 효율적 모델인 MobileNets를 제시합니다.
MobileNets는 가벼운 deep neural network를 만들기 위해 depth-wise separable convolution을 사용하여 간소화된 architecture를 기반으로 하고 있습니다.
저자들은 latency와 accuracy 사이의 trade-off를 조절하는 두 개의 간단한 global hyper-parameter를 도입합니다.
이러한 hyper-parameters는 model을 만드는 사람이 문제의 제약에 기반해서 적절한 사이즈의 모델을 선택할 수 있도록 도와줍니다.
저자들은 resource와 accuracy 사이의 tradeoff에 대한 광범위한 실험을 제시하고 있으며, ImageNet classification에서 유명한 다른 모델들과 비교했을 때 강력한 성능을 낸다는 사실을 보여줍니다.
그러고 나서 object detection, finegrain classification, face attribute, large scale geo-localization을 포함한 다양한 use case에서 MobileNet의 효과성을 검증합니다.
1. Introduction
AlexNet이 ImageNet Challenge인 ILSVRC 2012에서 승리한 이후로, computer vision 분야에서 Convolutional neural network는 아주 흔해졌습니다.
일반적인 경향은 더 높은 accuracy를 달성하기 위해서 더욱 deep 하고 복잡한 모델을 만드는 것이었습니다.
하지만, 이러한 accuracy에서의 진보는 네트워크를 size와 speed 측면에서 더욱 효율적이게 만들지 않습니다.
로보틱스나 자율주행차, 증강현실과 같은 현실 세계의 application에서는, recognition task가 연산적으로 한계가 있는 플랫폼에서 timely fashion으로 이루어질 필요가 있습니다.
본 논문에서는 mobile과 embedded vision application에서의 design requirement에 쉽게 매칭 될 수 있는 매우 작고, low latency를 가지는 모델을 만들고자 효율적인 네트워크 아키텍처와 두 개의 hyper-parameter를 제시합니다.
Section 2에서는 작은 모델을 만드는 것에 대한 선행 연구들을 리뷰하고, Section 3에서는 MobileNets을 더욱 작고 더욱 효율적으로 정의할 수 있는 width multiplier와 resolution multiplier와 MobileNet architecture를 제시합니다.
Section 4에서는 ImageNet에 대한 실험과 더불어 다양한 application과 use case에서의 실험을 제시합니다.
Section 5에서는 summary 및 결론으로 마무리합니다.
2. Prior Work
생략하고 넘어갑니다.
3. MobileNet Architecture
이번 section에서, 저자들은 첫 번째로 MobileNet을 만드는데 가장 중요한 layer인 depthwise separable filter에 대해서 설명합니다.
그러고 나서 MobileNet network structure를 설명하고, 두 개의 모델 shrinking hyper-parameter인 width multiplier와 resolution multiplier에 대해서 설명하고 마무리합니다.
3.1 Depthwise Separable Convolution
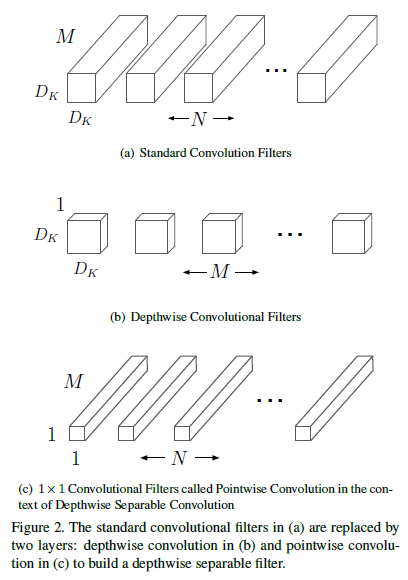
MobileNet model은 분리된 convolution의 한 형태인 depthwise separable convolution을 기반으로 하고 있으며, 이는 standard convolution을 depthwise convolution과 pointwise convolution이라고 불리는 1x1 convolution으로 분리합니다.
MobileNets에서 depthwise convolution은 하나의 filter를 각 input channel에 적용하게 됩니다.
Standard convolutional layer는 $D_K \times D_K \times M \times N$의 사이즈를 가지는 convolution kernel $K$에 의해서 parameterized 될 수 있으며, $D_K$는 kernel의 spatial dimension이며 $M$은 input channel, $N$는 output channel을 나타냅니다.
Standard convolution의 computational cost는 다음과 같이 정의될 수 있습니다.
이를 통해, computational ocst는 input channel $M$, output channel $N$, kernel size $D_k \times D_k$, feature map size $D_F \times D_F$에 비례한다는 사실을 알 수 있습니다.
MobileNet은 depthwise separable convolution을 사용해서 output channel의 수와 kernel의 사이즈 간의 interaction을 끊는 작업을 진행하게 됩니다.
Depthwise separable convolution은 depthwise convolution과 pointwise convolution의 두 layer로 구성됩니다.
Depthwise convolution은 input channel 각각에 대해서 single filter를 적용하게 됩니다. (기존 standard convolution은 input channel 사이즈랑 동일한 사이즈의 filter를 적용했었죠.)
Pointwise convolution은 depthwise layer의 output의 linear combination을 만들기 위해서 단순한 1x1 convolution을 사용하게 됩니다.
MobileNet도 batchnorm과 ReLU는 동일하게 사용됩니다.
먼저 Depthwise convolution의 computational cost부터 살펴보겠습니다.
Input channel의 각각에 대해서만 filter를 적용하면 되기 때문에, 기존에 있던 $N$은 사라지게 됩니다.
따라서 kernel size인 $D_K$와 inputer feature size인 $D_F$, 그리고 input channel의 수인 $M$에 비례하게 됩니다.
다음으로는 Depthwise convolution을 통해 얻어지는 output을 1x1 convolution을 통해 linear combination 해야 하므로, 다음과 같은 연산량을 갖게 됩니다.
1x1xM 사이즈의 kernel을 $D_F \times D_F$만큼 돌고, 이것이 output의 1개의 channel만 만들어내게 되므로, $N$ channel의 output을 만들기 위해서는 이러한 filter가 $N$개가 존재해야 합니다.
따라서, 위와 같은 computational cost가 발생하게 됩니다.
Depthwise separable convolution을 기존 standard convolution과 비교하면 다음과 같습니다.
MobileNet이 3x3 depthwise separable convolution을 사용하므로, computation 관점에서 8~9배 정도 줄어든다는 사실을 확인할 수 있습니다.
연산량은 이렇게 줄어들지만, accuracy에서는 작은 감소만 있음을 Section 4에서 검증합니다.
지금까지는 논문에 나온 내용을 토대로 설명을 드렸는데, 혹시나 이 글을 읽고 이해가 되시지 않는 분들을 위해서 조금 더 간단한 예시로 부가설명을 추가해보겠습니다.
예를 들어서, 6x6x5 짜리 input이 존재하고, 이를 convolution 연산을 통해서 얻게 되는 output이 4x4x7이라고 가정해보겠습니다. (kernel size는 3x3, stride = 1로 고정합니다.)
먼저 standard convolution의 경우 kernel size는 3x3x5가 됩니다. 그리고 이러한 작업을 가로로 4번, 세로로 4번 진행하게 됩니다. 그리고 output의 channel이 7 이므로 kernel을 7개 가지고 있어야 합니다. 따라서 전체 연산량은 (3x3x5)[kernel size]x4[가로 이동]x4[세로 이동]x7[kernel 수]이 됩니다. 총 5040입니다.
이를 Depthwise separable convolution으로 푼다면 다음과 같습니다.
먼저 kernel size는 3x3x1이 됩니다. 그리고 이러한 kernel이 input channel의 수 만큼 존재하므로 5개가 존재하게 됩니다. 이를 가지고 sliding window 작업을 진행하면 가로로 4번, 세로로 4번 진행하게 되고 이를 통해 얻게 되는 output은 4x4x5가 됩니다. 이때 연산량은 (3x3x1)[kernel size]x4[가로 이동]x4[세로 이동]x5[kernel 수]가 됩니다. 총 720입니다.
이를 가지고 4x4x7짜리의 output을 만들어야 하므로, 1x1x5짜리 kernel을 가로 4, 세로 4만큼 이동하면서 4x4 짜리를 얻고 이를 7개의 kernel를 가지고 진행하여 4x4x7짜리를 얻게 됩니다. 이때 연산량은 (1x1x5)[kernel size]x4[가로 이동]x4[세로 이동]x7[kernel 수]가 됩니다. 총 560입니다.
두 단계를 더해주면 되므로, 총 1280의 연산량을 갖게 됩니다.
기존 방법론에 비해서 약 4배 정도의 연산량 감소가 있음을 확인할 수 있습니다.
제가 예시로 든 경우는 사이즈가 작기 때문에 연산량 감소가 적었지만, 사이즈가 커지면 커질수록 연산량 감소의 효과는 더 커지게 됩니다.
3.2 Network Structure and Training
MobileNet structure는 첫 번째 layer를 제외하고는 앞에서 언급된 depthwise separable convolution을 이용해서 구성됩니다.
MobileNet architecture는 Table 1에서 확인할 수 있습니다.
그리고 Figure 3에서 regular convolution, batchnorm, ReLU를 가지는 layer와 depthwise convolution, 1x1 pointwise convolution, bachnorm, ReLU를 가지는 layer를 비교합니다.
Downsampling은 depthwise convolution에 있는 strided convolution을 이용하여 처리되고요.
마지막 average pooling은 spatial resolution을 1로 줄이고, 이를 fully connected layer와 연결합니다.
MobileNet은 RMSprop을 사용해서 학습되었고, large model을 학습할 때와는 다르게 regularization과 data augmentation technique은 적게 사용하였습니다.
이는 small model이 overfitting을 겪을 가능성이 더 낮기 때문입니다.
추가적으로, depthwise filter에 매우 작은, 혹은 no weight decay (l2 regularization)을 적용하는 것이 중요하다는 사실을 확인하였고, 이는 여기에 작은 수의 parameter가 포함되어 있기 때문입니다.
3.3 Width Multiplier: Thinner Models
비록 base MobileNet architecture가 이미 작고 낮은 latency를 가지지만, 어떤 경우에는 모델이 더 작고 더 빠른 것을 요구하는 경우가 존재할 수 있습니다.
더 작고 연산량이 더 적은 모델을 만들기 위해, 저자들은 width multiplier라고 불리는 아주 작은 parameter인 $\alpha$를 도입하였습니다.
Width multiplier $\alpha$의 역할은 각 layer를 균일하게 더 얇게 만드는 것입니다.
Width multiplier $\alpha$가 주어졌을 때, input channel의 수 $M$는 $\alpha M$이 되고, output channel의 수 $N$는 $\alpha N$이 됩니다.
width multiplier $\alpha$를 도입한 경우 depthwise separable convolution의 computational cost는 다음과 같습니다.
다음 Table 3은 standard convolution과 depthwise separable convolution, 그리고 width multiplier, resolution multiplier를 적용했을 때를 비교한 표입니다.
standard conv과 depthwise separable conv 사이에도 큰 차이가 있지만, multiplier를 이용하면 연산량이 굉장히 감소하는 것을 확인할 수 있습니다.
4. Experiment
이번 section에서는 depthwise convolution의 효과와 network의 수를 줄이는 것이 아니라 network의 width를 줄이는 shrinking의 효과에 대해서 먼저 알아봅니다.
그다음으로는 width multiplier와 resolution multiplier의 기반해서 network를 줄이는 것에 대한 trade off를 보고, 여러 가지 유명한 모델과 성능을 비교합니다.
그러고 나서 MobileNet을 다양한 application에 적용할 수 있음을 알아봅니다.
4.1 Model Choices
첫 번째로 저자들은 full convolution을 사용한 모델과 depthwise separable convolution을 사용한 MobileNet을 비교한 결과를 제시합니다.
Table 4를 보면, depthwise separable convolution을 사용한 것이 Mult-adds와 parameters에서는 엄청나게 감소하였으나, accuracy에서는 1%만의 성능 감소가 있음을 확인할 수 있습니다.
다음으로는 width multiplier를 사용한 thinner model과 더 적은 layer를 사용하는 shallower 모델을 비교합니다.
MobileNet을 더 얕게 만들기 위해서, feature size 14x14x512를 사용하는 5개의 separable filter를 제거하였습니다.
Table 5는 유사한 정도의 computation과 parameter의 수를 가지고 있지만 얇은 MobileNet이 얕은 MobileNet보다 3% 정도 더 좋다는 것을 보여줍니다.
4.2 Model Shrinking Hyperparameters
Table 6은 width multiplier $\alpha$를 사용해서 MobileNet architecture를 shrinking 했을 때의 accuracy, computation, size trade off를 보여줍니다.
아키텍처를 너무 작게 만드는 $\alpha = 0.25$가 될 때까지 accuracy는 smoothly 하게 감소하는 것을 확인할 수 있습니다.
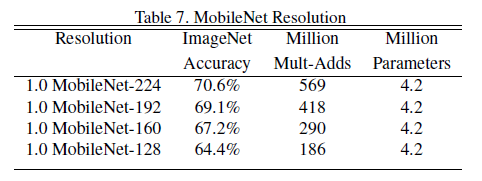
Table 7은 reduced input resolution을 사용했을 때 MobileNet을 학습하는 경우를 보여줍니다. resolution이 떨어질수록 accuracy가 감소하는 것을 확인할 수 있습니다.
Figure 4는 ImageNet Accuracy와 width multiplier $\alpha \in \left\{1, 0.75, 0.5, 0.25\right\}$, 그리고 resolution {224, 192, 160, 128}의 cross product를 통해 얻어지는 16개 모델에 대한 computation의 trade off를 보여줍니다. log linear 한 경향을 보여주고 있습니다.
Figure 5는 ImageNet Accuracy와 width multiplier $\alpha \in \left\{1, 0.75, 0.5, 0.25\right\}$, 그리고 resolution {224, 192, 160, 128}의 cross product를 통해 얻어지는 16개 모델에 대한 parameter의 수 간의 trade off를 보여줍니다.
Table 8은 original GoogleNet과 VGG16과 full MobileNet 간의 비교를 보여줍니다.
MobileNet은 VGG16만큼 정확하지만, 32배 더 작고 27배 더 적은 컴퓨터 연산량을 가지고 있습니다.
이는 GoogleNet보다는 더 정확하지만 모델이 더 작고 computation도 2.5배 더 작습니다.
먼저, Training dataset을 가지고 Multivariate Gaussian distribution의 parameter를 추정하는 작업을 진행합니다.
import random
from random import sample
import argparse
import numpy as np
import os
import pickle
from tqdm import tqdm
from collections import OrderedDict
from sklearn.metrics import roc_auc_score
from sklearn.metrics import roc_curve
from sklearn.metrics import precision_recall_curve
from scipy.spatial.distance import mahalanobis
from scipy.ndimage import gaussian_filter
from skimage import morphology
from skimage.segmentation import mark_boundaries
import matplotlib.pyplot as plt
import matplotlib
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision.models import wide_resnet50_2, resnet18
import datasets.mvtec as mvtec
GPU 연산이 가능한지를 use_cuda로 저장하고, 사용 가능한 장치를 device에 저장합니다.
그리고 해당 코드는 .py 파일로 구성되어 있어, argparse를 사용하고 있습니다.
--data_path는 MVTec AD의 경로를 지정해주고, save_path는 결과를 저장할 경로를 지정해줍니다.
--arch는 어떤 model을 사용할 것인지를 결정합니다.
def main():
args = parse_args()
# load model
if args.arch == 'resnet18':
model = resnet18(pretrained=True, progress=True)
t_d = 448
d = 100
elif args.arch == 'wide_resnet50_2':
model = wide_resnet50_2(pretrained=True, progress=True)
t_d = 1792
d = 550
model.to(device)
model.eval()
random.seed(1024)
torch.manual_seed(1024)
if use_cuda:
torch.cuda.manual_seed_all(1024)
idx = torch.tensor(sample(range(0, t_d), d))
이제 main 함수의 시작 부분입니다.
먼저 아까 정의했던 argparse를 args로 저장합니다.
--arch로 선택한 모델의 구조에 따라서, model을 불러옵니다.
t_d는 해당 모델의 Layer 1, Layer 2, Layer 3의 embedding vector를 concatenate 했을 때의 차원의 수를 나타내고, d는 그중에서 random dimensionality reduction을 진행할 random dimension의 수를 나타냅니다.
즉, ResNet18을 사용하면, embedding vector를 448차원으로 얻게 되고, 그중에서 100차원을 랜덤으로 뽑게 된다고 이해해주시면 될 것 같습니다.
idx는 t_d 차원에서 임의로 d차원을 뽑아서 저장해 torch tensor로 저장합니다.
mvtec ad의 class 각각에 대해서 for문을 작동시키고, 각 class의 train dataset과 test dataset을 만들어줍니다.
그리고 train dataset의 embedding vector와 test dataset의 embedding vector를 저장하기 위해서 OrderedDict을 이용해 Layer 1, Layer 2, Layer 3에 해당하는 embedding vector를 저장할 장소를 train_outputs과 test_outputs로 지정해둡니다.
# extract train set features
train_feature_filepath = os.path.join(args.save_path, 'temp_%s' % args.arch, 'train_%s.pkl' % class_name)
if not os.path.exists(train_feature_filepath):
for (x, _, _) in tqdm(train_dataloader, '| feature extraction | train | %s |' % class_name):
# model prediction
with torch.no_grad():
_ = model(x.to(device))
# get intermediate layer outputs
for k, v in zip(train_outputs.keys(), outputs):
train_outputs[k].append(v.cpu().detach())
# initialize hook outputs
outputs = []
for k, v in train_outputs.items():
train_outputs[k] = torch.cat(v, 0)
train_feature_filepath는 각 class에 대해서 저장한 Gaussian distribution의 parameter를 pickle 파일로 저장할 저장 경로를 저장하는 변수입니다.
다음으로는 for문을 돌게 되는데, 여기서 x는 train dataset의 이미지를 나타냅니다.
shape를 찍어보면 (32, 3, 224, 224) 임을 확인할 수 있습니다. (위에서 train_dataloader와 test_dataloader의 batch size가 32이기 때문에 32로 시작됩니다.)
그리고 _ = model(x.to(device))는 원래 model의 결과가 별도로 저장되어야 하는데, 본 모델에서는 모델의 최종 output을 필요로 하는 것이 아니라 중간 output을 필요로 하기 때문에 _를 사용하여 별도로 변수에 저장되지 않도록 처리한 것입니다.
이 코드 라인이 실행되면, 앞에서 지정한 forward hook에 의해서 Layer 1, 2, 3에서 얻어지는 중간 output 결과들을 outputs라는 변수에 저장이 됩니다.
for k, v in zip(train_outputs.keys(), outputs): 코드라인은 outputs에 저장된 각각의 요소들을 OrderedDict인 train_outputs의 각 Key에 append 하는 코드입니다.
forward hook이 Layer 1, 2, 3에 각각 작동하기 때문에 outputs에는 총 3개의 데이터가 append 되어 있는 상태입니다.
따라서 for문을 통해 각각을 train_outputs의 Key에 저장할 수 있게 됩니다.
그리고 outputs = []를 통해 중간 output을 저장하는 리스트를 다시 비워서 다음 class에 대해서 동일한 코드가 작동할 때 새롭게 저장될 수 있도록 만들어줍니다.
for k, v in train_outputs.items(): 코드라인은 앞에서 batch 단위로 저장되어 있는 데이터들을 합쳐서 전체로 만들어주는 코드입니다.
예를 들어서, bottle class는 209장의 train 이미지가 있는데, batch는 32이므로 32짜리로 여러 개의 데이터가 저장되어 있을 것입니다.
즉 가로와 세로가 절반씩 줄어드는 구조이기 때문에 단순히 Channel 방향으로 concat 시키는 것이 불가능하기 때문입니다.
일일이 shape를 다 확인하는 것도 방법이긴 하지만 대략 어떤식으로 embedding vector concat이 이루어지는지만 알고 있으면 충분할 것이라고 생각이 됩니다. (물론 코드를 하나하나 자세히 shape 찍어보시는 것도 좋지만 이 부분이 워낙 복잡하여 전체적인 컨셉만 짚고 넘어가려고 합니다.)
(N, 1, 4, 4) 크기의 embedding vector(A)와 (N, 2, 2, 2) 크기의 embedding vector(B)가 있다고 가정해보겠습니다.
N은 training dataset size이나, 4차원은 그림으로 표현할 수 없으므로 생략하고 3차원에 대해서만 그림으로 설명해보겠습니다.
embedding vector A와 B는 다음과 같이 그림으로 표현할 수 있습니다.
이를 위 함수를 이용해서 concat 하면 다음과 같은 방식으로 concat이 진행됩니다.
먼저 높이와 폭 기준으로 더 넓은 쪽인 (N, 1, 4, 4)가 앞쪽에 원래대로 위치하고, 높이와 폭이 1/2인 (N, 2, 2, 2)짜리는 각 위치에서 2x2 사이즈만큼 복사되어서 높이, 폭의 2배 사이즈 차이를 메우게 됩니다.
이게 말로 하려니 설명이 살짝 어려운데, 첫 번째 사진과 두 번째 사진을 보시면서 값들이 어떻게 배치되었는지 확인해주시면 이해가 크게 어렵지는 않을 것이라고 생각합니다.
이러한 방식을 이용하게 되면, 높이와 폭 사이즈는 그대로 유지되면서, 합쳐지는 두 embedding vector의 차원 수만 합쳐지는 결과를 가지고 오게 됩니다.
이런 방식으로 Layer 1, Layer 2, Layer 3에서 나오는 embedding vector를 합칠 수 있게 되고, ResNet18 기준으로 얻어지는 (Training dataset size, 64, 56, 56), (Training dataset size, 128, 28, 28), (Training dataset size, 256, 14, 14)을 concat 하게 되면 (Training dataset size, 64+128+256, 56, 56) 사이즈의 embedding vector를 얻을 수 있게 됩니다.
# randomly select d dimension
embedding_vectors = torch.index_select(embedding_vectors, 1, idx)
위 과정을 통해서 얻어진 embedding vector에서 d 차원만큼을 랜덤으로 선택합니다.
PaDiM 논문에서는 embedding vector 전체를 사용하는 것에 비해서 random 하게 차원을 줄였을 때 시간 복잡도와 공간 복잡도가 줄어들지만 anoamly localization 성능에서는 큰 폭의 차이가 없음을 보였습니다.
# calculate multivariate Gaussian distribution
B, C, H, W = embedding_vectors.size()
embedding_vectors = embedding_vectors.view(B, C, H * W) # (209, 100, 56*56)
mean = torch.mean(embedding_vectors, dim=0).numpy() # (100, 56*56), 샘플 간 평균
cov = torch.zeros(C, C, H * W).numpy() # (100, 100, 56*56) 100차원 간 cov 계산
I = np.identity(C)
for i in range(H * W):
cov[:, :, i] = np.cov(embedding_vectors[:, :, i].numpy(), rowvar=False) + 0.01 * I
# save learned distribution
train_outputs = [mean, cov]
with open(train_feature_filepath, 'wb') as f:
pickle.dump(train_outputs, f)
다음은 얻어진 embedding vector를 가지고 multivariate Gaussian distribution의 parameter를 얻는 코드입니다.
먼저 embedding_vector를 (B, C, H*W)의 차원으로 바꿔줍니다.
ResNet18 기준이라면, (N, 100, 56*56)이 됩니다. (최종적으로 얻어진 embedding vector는 (N, 448, 56, 56)이지만 448차원 중 100차원을 랜덤으로 선택하였으므로 (N, 100, 56, 56)을 얻게 되고, 이를 (N, 100, 56*56)로 reshape 한 것입니다.)
그리고 0차원(데이터 셋 크기) 기준으로 평균을 구합니다. 이는 (100, 56*56)의 size를 가집니다.
의미적으로 본다면, 이미지에서 각 패치의 embedding 평균을 구한 것이 되겠죠?
그다음으로는 공분산을 계산해야 하는데, 먼저 torch.zeros로 0으로 채워진 (100, 100, 56*56) 짜리 tensor를 만들어줍니다.
embedding vectors[:, :, i]라면 patch의 각 위치에서의 데이터가 되고, 크기는 (N, 100)이 될 것입니다.
np.cov에 rowvar라는 인자가 있는데, 이는 row를 기준으로 분산을 구할 것인지를 물어보는 것입니다.
rowvar = False이므로, 우리는 row를 기준으로 분산을 구하지 않고 column을 기준으로 분산을 구하게 됩니다.
이렇게 하면 column인 100(embedding vector의 차원 수)을 기준으로 분산을 구할 수 있게 됩니다.
이를 cov[:, :, i]에 저장하게 되죠. cov가 (100, 100, 56*56) 였음을 감안한다면, cov[:, :, i]는 각 patch 위치에서의 (100, 100) 크기의 matrix가 되는 것을 알 수 있습니다.
0.01 * I는 논문에서도 언급하였듯이 regularization term이고, 공분산 matrix의 invertible이 보장되도록 하는 역할을 수행합니다.
마지막으로 우리가 구한 mean과 cov를 pickle.dump을 통해서 pickle 파일로 저장해줍니다.
else:
print('load train set feature from: %s' % train_feature_filepath)
with open(train_feature_filepath, 'rb') as f:
train_outputs = pickle.load(f)
만약 별도로 이미 저장된 pickle 파일이 있다면, 이를 읽어오기만 하면 됩니다.
아마 이미 계산된 mean과 cov가 있는 경우는 별도로 연산하지 않고 바로 불러올 수 있게끔 코드를 짜 놓은 것 같습니다.
Inference
gt_list = [] # label을 담는 list
gt_mask_list = [] # mask를 담는 list
test_imgs = [] # 이미지를 담는 list
다음으로는 test image에 대한 Inference를 진행하겠습니다.
먼저 label(0인지 1인지, 0이면 정상, 1이면 이상입니다.), segmentation mask(정답 mask), 정답 이미지를 담는 list를 먼저 지정합니다.
for (x, y, mask) in tqdm(test_dataloader, '| feature extraction | test | %s |' % class_name):
test_imgs.extend(x.cpu().detach().numpy())
gt_list.extend(y.cpu().detach().numpy())
gt_mask_list.extend(mask.cpu().detach().numpy())
# model prediction
with torch.no_grad():
_ = model(x.to(device))
# get intermediate layer outputs
for k, v in zip(test_outputs.keys(), outputs):
test_outputs[k].append(v.cpu().detach())
# initialize hook outputs
outputs = []
for k, v in test_outputs.items():
test_outputs[k] = torch.cat(v, 0)
# Embedding concat
embedding_vectors = test_outputs['layer1']
for layer_name in ['layer2', 'layer3']:
embedding_vectors = embedding_concat(embedding_vectors, test_outputs[layer_name])
# randomly select d dimension
embedding_vectors = torch.index_select(embedding_vectors, 1, idx)
test_dataloader에서 나오는 이미지 데이터(x)와 라벨(y), segmentation mask(mask)를 각각 앞에서 미리 지정된 list에 extend로 추가합니다.
그다음 코드들은 제가 앞에서 설명한 것과 동일하죠??
이미지를 주고 예측을 하게 만든 다음, 최종 output은 저장하지 않고 forward hook을 이용해서 Layer 1, 2, 3에서 나온 결과들이 저장되도록 만들고 test_outputs에 저장해두는 과정을 거칩니다.
그리고 얻어진 embedding vector를 concat 하고, 이 중에서 랜덤으로 d 차원만 골라줍니다.
# calculate distance matrix
B, C, H, W = embedding_vectors.size() # (N, 100, 56, 56)
embedding_vectors = embedding_vectors.view(B, C, H * W).numpy() # (N, 100, 56*56)
dist_list = []
for i in range(H * W):
mean = train_outputs[0][:, i]
conv_inv = np.linalg.inv(train_outputs[1][:, :, i])
dist = [mahalanobis(sample[:, i], mean, conv_inv) for sample in embedding_vectors]
dist_list.append(dist)
다음으로는 Test image의 embedding_vector에 대해서 Mahalanobis distance를 계산하는 코드입니다.
patch의 각 위치에 대해서 평균과 공분산을 가져오고, distance 계산을 위해 공분산을 역행렬로 바꿔줍니다.
그리고 평균과 공분산을 가지고서 각 test image의 embedding vector에 대해서 distance 계산을 수행합니다.
저자들은 본 논문에서 one-class learning setting일 때 이미지 내에서 anomaly를 검출하면서 동시에 위치를 찾아내고자 Patch Distribution Modeling을 위한 새로운 framework를 제시합니다.
PaDiM은 patch embedding을 위해서 pretrained convolutional neural network를 사용하고, normal class의 확률적 representation을 얻고자 multivariate Gaussian distribution을 활용합니다.
이는 anomaly의 위치를 더 잘 찾기 위해 CNN의 다양한 semantic level 사이의 correlation 또한 사용할 수 있게 해 줍니다.
PaDiM은 MVTec AD와 STC dataset에 대해서 anomaly detection과 localization 모두 현재 SOTA보다 더 나은 성능을 나타냅니다.
실제 산업 현장에서 이루어지는 inspection과 유사한 환경을 만들기 위해, 저자들은 anomaly localization algorithm의 성능을 평가하는 evaluation protocol을 non-aligned data로 확장하는 결과도 보여줍니다.
1. Introduction
사람은 동질의 자연스러운 이미지의 집합에서 이질적이거나 예상하지 못한 패턴을 검출할 수 있는데, 이러한 task는 anomaly detection 혹은 novelty detection이라고 알려져 있습니다.
하지만 제조 공정에서 anomaly는 매우 드물게 발생하며, 이를 수동으로 검출하는 것은 힘든 일입니다.
그러므로, anomaly detection automation은 사람 작업자의 작업을 촉진함으로써 지속적인 품질 관리를 가능하게 해 줍니다.
본 논문에서 저자들은 주로 산업 검사 상황에서의 anomaly detection과 anomaly localization에 초점을 둡니다.
Computer vision에서, anomaly detection은 이미지에 anomaly score를 매기는 것으로 이루어져 있습니다.
Anomaly localization은 각 픽셀이나, 혹은 픽셀들의 각 패치에 anomaly score를 assign 해서 anomaly map을 산출하는 더욱 복잡한 task입니다.
따라서, anomaly localization은 더욱 정확하고 해석 가능한 결과를 만들어내게 됩니다.
저자들의 방법론을 통해 만들어진 anomaly map의 MVTec Anomaly Detection (MVTec AD) dataset에서의 예시는 Figure 1에서 확인할 수 있습니다.
Figure 1
Anomaly detection은 normal class와 anomalous class 사이의 binary classification입니다.
하지만, anomalous examples가 자주 부족하고, 더욱이 anomalies는 예기치 않은 패턴을 가질 수 있기 때문에 anomaly detection을 위한 모델을 full supervision으로 학습시킬 수 없습니다. (supervised learning이 불가능하다 정도로 이해하시면 됩니다. 상대적으로 anomaly image를 구하기 어렵기 때문이죠.)
즉, 학습하는 동안 anomalous examples는 사용할 수 없으며 training dataset은 오직 normal class에서 나온 이미지만 포함합니다.
Test time일 때, normal training dataset과는 다른 examples이 anomalous로 분류됩니다.
최근에, one-class learning setting에서 anomaly localization과 detection task를 결합하기 위해 여러 방법론들이 제안되어 왔습니다.
하지만, 이러한 방법론들은 다루기 힘든 deep neural network training을 필요로 하거나, test time에서 전체 training dataset에 대해 K-nearest-neighbor (KNN) algorithm을 사용합니다.
KNN algorithm의 시간 복잡도와 공간 복잡도는 training dataset의 크기가 증가함에 따라 증가하게 됩니다.
이러한 두 확장성 문제(1. 다루기 힘든 DNN 학습을 필요로 함, 2. KNN algorithm의 사용)는 산업 현장에서 anomaly localization algorithm을 사용되는 것을 어렵게 만듭니다.
앞에서 언급된 문제들을 완화하고자, 저자들은 PaDiM이라고 부르는 새로운 anomaly detection and localization approach를 제안합니다.
이는 pretrained convolutional neural network (CNN)을 embedding extraction에 사용하고, 다음 두 가지 특성을 가집니다.
각 patch position은 multivariate Gaussian distribution으로 표현됩니다.
PaDiM은 pretrained CNN의 다른 semantic level 간의 correlation을 고려합니다.
이러한 새롭고 효율적인 접근법을 이용해, PaDiM은 MVTec AD와 ShanghaiTech Campus (STC) dataset에 대해서 anomaly localization과 detection의 현재 SOTA method보다 더 좋은 성능을 냅니다.
게다가, test time에서 PaDiM은 낮은 시간 복잡도와 공간 복잡도를 가지며 training dataset size와 독립적입니다.
저자들은 또한 non-aligned dataset과 같은 보다 현실적인 조건에서의 model performance를 평가하기 위해 evaluation protocol을 확장하였습니다.
2. Related work
Anomaly detection과 localization methods는 reconstruction-based나 embedding similarity-based methods로 분류될 수 있습니다.
2.1 Reconstruction-based methods
Reconstruction-based methods는 anomaly detection과 localization에서 널리 사용되는데요.
Autoencoder (AE)와 같은 Neural network architectures, variational autoencoders (VAE), 혹은 generative adversarial networks (GAN)는 오직 normal training image만 복원하도록 학습됩니다.
그러므로, anomalous image는 잘 복원되지 않기 때문에 검출될 수 있습니다.
Image level에서, 가장 간단한 접근법은 reconstructed error를 anomaly score로 사용하는 것이나, latent space나 intermediate activation, 혹은 discriminator로부터 얻을 수 있는 추가적인 정보는 anomalous image를 더 잘 파악하는데 도움을 줄 수 있습니다.
Anomalies의 위치를 파악하기 위해서, reconstruction-based methods는 pixel-wise reconstruction error나 structural similarity를 anomaly score로 사용할 수 있습니다.
비록 reconstruction-based methods가 매우 직관적으로 해석 가능하지만, AE가 때때로 anomalous image에 대해서도 좋은 reconstruction results를 만들어낼 수 있다는 사실에 의해 이들의 성능은 제한적입니다.
2.2 Embedding similarity-based methods
Embedding similarity-based methods는 anomaly detection을 위한 전체 이미지나 anomaly localization을 위한 이미지 패치를 묘사하는 meaningful vector를 추출하는 deep neural network를 사용하게 됩니다.
Anomaly detection만을 수행하는 embedding similarity-based methods는 유망한 결과를 내고 있으나 anomalous image의 어떤 부분이 높은 anomaly score에 대해 기여하고 있는지를 아는 것이 불가능하므로 해석 가능성이 부족한 경우들이 있습니다.
이러한 경우에 anomaly score는 training dataset으로부터 얻어지는 reference vector와 test image의 embedding vector 사이의 distance가 됩니다.
Normal reference는 normal image로부터의 embeddings, Gaussian distribution의 parameters, 혹은 normal embedding vector의 전체 집합을 포함하는 n-sphere의 중심이 될 수 있습니다.
마지막 option은 anomaly localization에서 가장 좋은 성능을 낸 SPADE에서 사용되었습니다.
하지만, 이는 test time에서 normal embedding vector의 집합에 K-NN algorithm을 실행하게 되며 이는 training dataset size에 따라 선형적으로 inference 복잡도를 증가하게 만듭니다.
이는 해당 방법을 산업 현장에서 사용하기 어렵게 만듭니다.
저자들의 방법론인 PaDiM은 앞에서 언급된 접근법들과 유사하게 anomaly localization을 위한 patch embedding을 만들어냅니다.
하지만, PaDiM에서 normal class는 pretrained CNN model의 semantic level 간 correlation을 모델링하는 일련의 Gaussian distribution을 통해 묘사됩니다.
이전 연구에서 영감을 받아, 저자들은 ResNet, Wide-ResNet, EfficientNet과 같은 pretrained networks를 선택하였습니다.
PaDiM은 현재 SOTA method보다 더 좋은 성능을 내며, 시간 복잡도는 낮고 예측 단계에서 training dataset size와 독립적입니다.
3. Patch Distribution Modeling
3.1 Embedding extraction
Pretrained CNN은 anomaly detection을 위해 관련 있는 특징들을 뽑아낼 수 있습니다.
그러므로, 저자들은 patch embedding vector를 만들기 위해서 오직 pretrained CNN을 사용함으로써 다루기 힘든 neural network optimization을 회피하는 것을 선택하였습니다.
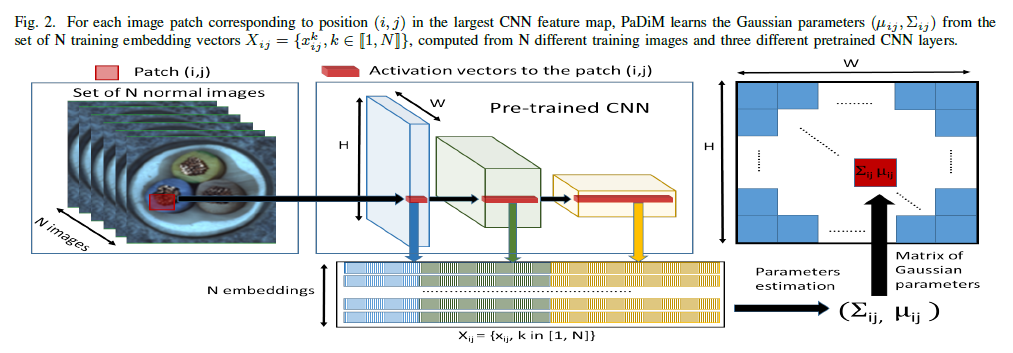
PaDiM에서의 patch embedding process는 SPADE에서와 유사하며, Figure 2에서 확인할 수 있습니다.
Figure 2
학습 phase 동안에, normal image의 각 patch는 pretrained CNN activation map에서 공간적으로 대응되는 activation vector와 연관됩니다. (예를 들어서, 원래 이미지는 224x224이고 위 그림에서 Pre-trained CNN의 맨 왼쪽 파란색 activation vector는 ResNet18 기준으로 56x56가 되는데요. 이는 원래 이미지의 4x4 만큼의 Patch가 activation vector에서 1x1이 된다고 생각할 수 있습니다.)
Fine-grained and global context를 encoding 하기 위해서, 다른 semantic level과 resolution으로부터의 정보를 가지고 있는 embedding vector를 얻고자 다른 layers로부터의 activation vector는 concatenated 됩니다.(위 Figure 2에서 파란색 embedding과 녹색 embedding, 노란색 embedding을 모두 합친다는 의미라고 이해해주시면 됩니다.)
Activation maps가 input image보다 더 낮은 resoltuion을 가지기 때문에 많은 pixel들은 동일한 embeddings를 가지게 되며, original image resolution에서 어떠한 overlap도 없는 pixel patch를 형성하게 됩니다. (앞에서 설명드린 224x224가 56x56이 되는 것을 생각해보시면 별도로 overlap 되는 것 없이 작업이 된다는 것을 이해하실 수 있을 것이라고 생각합니다.)
그러므로, input image는 $(i, j) \in [1, W] \times [1, H]$의 grid로 분할될 수 있으며, $W \times H$는 embeddings를 만들어낼 때 사용된 가장 큰 activation map의 resolution을 나타냅니다.
마지막으로, 이러한 grid에서의 각 patch position $(i, j)$는 위에서 묘사된 것처럼 계산된 embedding vector $x_{ij}$와 관련이 있습니다.
생성된 patch embedding vector가 중복된 정보를 가질 수 있기 때문에, 저자들은 이들의 사이즈를 줄이기 위한 가능성을 실험적으로 연구했는데요.
저자들은 고전적인 PCA를 통해 임의로 몇몇 차원만을 선택하는 것이 더욱 효율적이라는 것을 알게 되었습니다.
이러한 단순한 random dimensionality reduction은 SOTA performance를 유지하면서도 training and testing time 둘 다에서의 model의 복잡도를 상당히 감소시키게 됩니다.
마지막으로, test image에서의 patch embedding vector는 다음 subsection에서 설명하는 대로 normal class의 학습된 parametric representation을 가지고 anomaly map을 만들어내는 데 사용됩니다.
3.2 Learning of the normality
위치 $(i, j)$에서의 normal image 특성을 학습하기 위해, 저자들은 첫 번째로 N개의 normal training image로부터 $(i, j)$에서의 patch embedding vector의 집합 $X_{ij} = \left\{x^k_{ij}, k \in [1, N]\right\}$를 계산합니다.
이 집합으로부터 얻어지는 정보를 요약하기 위해, 저자들은 $X_{ij}$가 multivariate Gaussian distribution $\mathcal{N}(\mu_{ij}, \Sigma_{ij})$에 의해서 생성되었다는 가정을 만들었으며, $\mu_{ij}$는 $X_{ij}$의 sample mean이고, sample covariance $\Sigma_{ij}$는 다음과 같이 추정됩니다.
Regularization term인 $\epsilon I$는 sample covariance matrix $\Sigma_{ij}$가 full rank이고 invertible 하게 만들어줍니다.
마지막으로, 각각의 가능한 patch position은 Gaussian parameter의 matrix에 의해서 Figure 2에서 나타나듯이 multivariate Gaussian distribution과 관련됩니다.
저자들의 patch embedding vector는 다른 semantic level로부터의 information을 포함하고 있습니다.
(이미 알려져 있는 것처럼, CNN의 각 layer는 각자 다른 수준의 특징을 잡아내게 됩니다. 해당 모델에서는 3개의 layer에서 embedding vector를 뽑아내므로, 각 embedding vector는 각자 다른 수준의 특징을 잡아낸다고 볼 수 있습니다.)
그러므로, 추정된 multivariate Gaussian distribution $\mathcal{N}(\mu_{ij}, \Sigma_{ij})$ 각각은 다른 level로부터의 information을 포착하고 있으며 $\Sigma_{ij}$는 inter-level correlation을 포함하게 됩니다.
저자들은 pretrained CNN의 다른 semantic level 사이의 관계를 모델링하는 것이 anomaly localization performance를 증가시키는데 도움이 준다는 사실을 실험적으로 보였습니다.
3.3 Inference: computation of the anomaly map
다른 논문들에서 영감을 받아, 저자들은 test image의 $(i, j)$에 있는 patch에 대해서 anomaly score를 만들어내고자 Mahalanobis distance $\mathcal{M}(x_{ij})$를 사용하였습니다.
$\mathcal{M}(x_{ij})$는 test patch embedding $x_{ij}$와 학습된 distribution $\mathcal{N}(\mu_{ij}, \Sigma_{ij})$간 거리로 해석될 수 있으며, $\mathcal{M}(x_{ij})$는 다음과 같이 계산됩니다.
(동일한 좌표 $(i, j)$에 대해서, 학습된 평균과 공분산을 통해 각 test image의 $(i, j)$위치에 대해 계산하게 되면 해당 test image의 각 좌표 $(i, j)$가 normal distribution과 비교했을 때 얼마나 차이가 많이 나는지를 계산할 수 있게 됩니다.)
이 map에서 높은 점수는 anomalous areas를 나타내게 됩니다.
전체 이미지의 최종 anomaly score는 anomaly map $\mathcal{M}$의 maximum 값이 됩니다.
마지막으로, test를 진행할 때, 저자들의 방법론은 patch의 anomaly score를 얻기 위해서 많은 양의 distance value를 계산하고 정렬할 필요가 없으므로 K-NN 기반의 방법론의 확장성 이슈를 가지고 있지 않습니다.
4. Experiments
4.1 Datasets and metrics
저자들은 첫 번째로 모델을 one-class learning setting에서 industrial quality control을 위한 anomaly localization algorithm을 테스트하기 위해 설계된 MVTec AD dataset에 평가하였습니다.
이는 대략 240개의 이미지로 구성된 15개의 클래스를 포함하며, 이미지의 resolution은 700x700부터 1024x1024로 다양하게 존재합니다.
여기에는 10 object class와 5 texture class가 있습니다.
Objects는 항상 well-centered이며, Transistor와 Capsule 클래스를 묘사한 Figure 1에서 볼 수 있듯이 dataset 전반에 걸쳐 동일한 방식으로 정렬되어 있습니다.
원래 dataset에 추가해서, 더 현실적인 상황에서의 anomaly localization model의 성능을 평가하고자, 저자들은 MVTec AD의 modified version인 Rd-MVTec AD라는 것을 만들었습니다.
이는 train과 test dataset 모두 (-10, +10)의 random rotation을 적용하였고, 256x256에서 224x224로 random crop을 진행하였습니다.
MVTec AD의 수정된 버전은 이미지 내에서 관심 있는 사물이 항상 중심에 있지 않고 정렬되어 있지 않은 상황에서의 quality control의 anomaly localization의 케이스를 더욱 잘 묘사할 것입니다.
Localization performance를 평가하기 위해, 저자들은 두 가지 threshold와 독립적인 metrics를 사용하였습니다.
저자들은 Area Under the Receiver Operating Characteristic curve (AUROC)를 사용하였는데, 여기서 true positive rate는 이상이 이상으로 올바르게 분류된 pixel의 비율을 나타냅니다.
AUROC가 large anomalies에 편향되기 때문에, 저자들은 per-region-overlap score (PRO-score) 또한 사용하였습니다.
(논문에는 PRO score에 대한 정보가 없어서, 다른 논문에서 발췌하여 추가합니다.)
(출처: Image Anomaly Detection Using Normal Data Only by Latent Space Resampling)
(Ground truth map과 비교했을 때 predicted segmentation map이 얼마나 많이 맞췄는지를 나타내는 것 같습니다. )
추가적인 평가를 위해서 PaDiM을 영상 데이터셋인 Shanghai Tech Campus (STC) Dataset에도 테스트를 진행했습니다.
이는 13개의 장면으로 나눠진 274,515 training frame과 42,883 test frame으로 구성되어 있고, 이미지 resolution은 856x480로 구성됩니다.
Training video는 normal sequence로만 구성되어 있고, test video에는 사람이 싸우거나 보행자 지역에서 vehicle이 등장하는 anomaly가 포함되어 있습니다.
4.2 Experimental setups
저자들은 PaDiM을 ResNet18(R18), Wide ResNet-50-2 (WR50), EfficientNet-B5의 다른 backbone을 사용하여 학습시켰으며, 모두 ImageNet에 pretrained 되었습니다.
다른 논문처럼, patch embedding vector는 ResNet backbone인 경우에 localization task를 위해 충분히 큰 resolution을 유지하면서 다른 semantic level로부터의 정보를 결합하고자 첫 번째 3개의 layer로부터 추출하였습니다.
이러한 아이디어를 유지하면서, EfficientNet-B5를 사용한 경우에 patch embedding vector를 layers 7(level 2), 20 (level 4), 26 (level 5)로부터 추출하였습니다.
저자들은 또한 random dimensionality reduction (Rd)을 적용하였습니다.
그리고 Equation 1에서 사용된 $\epsilon$에는 0.01의 값을 사용하였습니다.
MVTec AD에 있는 이미지들은 256x256로 resize 한 후, 224x224로 center crop을 진행하였습니다.
저자들은 localization map을 bicubic interpolation을 사용해서 만들어냈으며, anomaly map에 대해서 parameter $\sigma = 4$를 적용하는 Gaussian filter를 사용하였습니다.
5. Results
5.1 Ablative studies
첫 번째로, 저자들은 PaDiM에서의 semantic levels 간의 correlation을 모델링하는 것의 영향을 평가하였고, dimensionality reduction을 통해 본 논문에서 제안하는 방법론을 더욱 단순화시킬 가능성을 연구하였습니다.
Inter-layer correlation.
Gaussian modeling과 Mahalanobis distance의 결합은 이미 image level에서의 anomaly detection과 adversarial attack을 탐지하기 위한 이전 연구들에서 사용되어 왔습니다.
하지만, 이러한 방법론들은 PaDiM에서 한 것처럼 다른 CNN의 semantic levels 간의 correlation을 모델링하지는 않았습니다.
Table I에서, 저자들은 ResNet18 backbone을 사용하는 PaDiM의 MVTec AD에서의 anomaly localization performance를 보여주는데, 첫 번째 3개의 layer (Layer 1, Layer 2, Layer 3) 중에서 하나만 사용했을 때와 이러한 세 개의 model의 output을 가지고 첫 번째 3개의 layer를 고려하지만 이들 간 correlation은 고려하지 않는 ensemble method를 형성하고자 더했을 때의 결과를 보여줍니다.
Table I
Table I의 마지막 행은 ResNet18의 처음 3개의 layer와 이들 간 correlation을 고려하는 하나의 Gaussian distribution에 의해 각 patch location이 묘사되는 PaDiM을 나타냅니다.
단일 Layer만 사용하는 결과 중에서는, Layer 3을 사용하는 것이 3개의 레이어 중에서 AUROC 기준으로 가장 좋은 결과를 만들어낸다는 사실을 확인할 수 있습니다.
이는 정상성을 더 잘 묘사하는데 도움을 줄 수 있는 높은 수준의 semantic level information을 Layer 3이 포함하고 있다는 사실 때문으로 보입니다.
Output을 단순히 더한 model인 Layer 1+2+3와는 다르게, 저자들이 제안하는 PaDiM-R18은 semantic level 간 correlation을 고려하게 되는데요.
그 결과로, 이는 Layer 1+2+3에 비해서 더 좋은 결과를 나타내는 것을 확인할 수 있습니다.
이는 semantic level 간 correlation을 모델링하는 것의 적절성을 보여줍니다.
Embedding vector size를 감소시키는 것은 모델의 공간 복잡도와 계산 복잡도를 줄일 수 있기 때문에, 저자들은 두 가지의 다른 dimensionality reduction method를 연구하였습니다.
첫 번째로는 Principal Component Analysis (PCA) algorithm을 사용해서 vector size를 100차원이나 200차원으로 줄이는 것이고, 두 번째는 학습하는 동안에 임의로 선택된 feature를 가지고 random feature selection을 진행하는 것입니다.
이 경우에, 저자들은 10개의 다른 모델을 학습시키고, 평균 점수를 취하는 방식으로 실험을 진행하였습니다.
Table II를 살펴보면, 같은 수의 차원에 대해서 random dimensionality reduction (Rd) 방식이 PCA에 비해서 모든 클래스에 대해 더 좋은 성능을 내는 것을 확인할 수 있었습니다.
이는 PCA가 anomalous class로부터 normal class를 분류하는데 도움이 되지 않을 수 있는 가장 높은 분산을 가지는 dimension을 선택한다는 사실로 설명될 수 있습니다.
그리고 임의로 embedding vector size를 100차원으로 줄였을 때도 anomaly localization performance에는 매우 작은 영향을 준다는 사실을 확인할 수 있습니다.
이렇게 간단하면서도 효율적인 dimensionality reduction method는 PaDiM의 시간 복잡도와 공간 복잡도를 상당히 줄여줄 수 있습니다.
5.2 Comparison with the state-of-the-art
anomaly localization 기준으로는, PaDiM-WR50-Rd550가 가장 좋은 성능을 내는 것을 확인할 수 있습니다.
anomaly detection 기준으로는, PaDiM EfficientNet-B5가 가장 좋은 성능을 내는 것을 확인할 수 있습니다.
5.3 Anomaly localization on a non-aligned dataset
앞에서 소개한 non-aligned Rd-MVTec AD dataset에 대해서도 역시 PaDiM-WR50-Rd550가 anomaly localization 기준으로 가장 우수한 성능을 나타낸다는 사실을 확인할 수 있습니다.
5.4 Scalability gain
Time complexity
anomaly localization inference time을 비교했을 때, VAE가 가장 낮지만 PaDiM-R18-Rd100은 비슷한 시간이 걸림에도 불구하고 VAE보다 훨씬 더 좋은 성능을 낸다라는 사실을 확인할 수 있습니다.
Memory complexity
MVTec AD와 같은 작은 dataset에 대해서는 SPADE가 더 작은 memory를 요구하지만, STC와 같은 큰 데이터셋에 대해서는 SPADE가 훨씬 더 많은 공간 복잡도를 가짐을 확인할 수 있습니다. 따라서, 더 큰 데이터셋에 대해서는 PaDiM이 훨씬 더 적은 공간 복잡도를 가짐을 확인할 수 있습니다.
6. Conclusion
저자들은 본 논문에서 one-class learning setting에서 distribution modeling에 기반해 anomaly detection과 localization을 수행하는 framework인 PaDiM을 제시합니다.
이는 MVTec AD와 STC dataset에 대해서 SOTA performance를 달성하였습니다.
추가로, 저자들은 evaluation protocol을 non-aligned data으로 확장하여, PaDiM이 더욱 현실적인 데이터에 강건할 수 있음을 보였습니다.
PaDiM은 낮은 메모리와 시간 복잡도를 가지며, 산업 현장과 같은 다양한 application에서 사용하기에 적합합니다.
여기까지 PaDiM 논문에 대한 paper review를 진행해보았습니다.
기존에는 신경망을 별도로 학습했어야 하지만, PaDiM 방법론은 pretrained CNN을 사용하므로 별도로 신경망을 학습할 필요가 없다는 장점을 가지고 있습니다.
또한 normal data에 대해서 Gaussian parameter만 가지고 있으면 이를 통해 distance 계산만 하면 되기 때문에 빠르게 test가 가능하며, 이는 기존에 K-NN algorithm을 필요로 하는 방법론에 비해서 training dataset이 커졌을 때 더욱 시간 복잡도의 큰 감소 효과를 볼 수 있습니다.
이전에 리뷰했었던 Patch SVDD의 경우에 제가 가지고 있는 training dataset이 3천 장이 넘는 상황이라 이를 절반만 이용하여서 실험을 진행하는데도 불구하고 test를 진행하는데 엄청난 시간이 걸린다는 문제점이 있었습니다.
1.1에서는 학습이 전체적으로 어떻게 이루어지는지 글로 설명드리고, 1.2.x에서는 해당 내용을 코드 기준으로 설명해드립니다.
1.1 Training의 전체적인 흐름
가장 먼저 학습을 진행해야 하는 모델들을 정의해줍니다.
우리가 사용할 모델은 Encoder와 classifier가 있습니다.
다음으로는 학습을 하는 데 사용하는 데이터셋을 구축하게 됩니다.
데이터셋은 총 4개를 구축하게 되며, (1) 64x64 patch dataset (+pos), (2) 32x32 patch dataset (+pos), (3) 64x64 patch dataset (no pos), (4) 32x32 patch dataset (no pos)로 구성됩니다.
그리고 각 데이터셋은 항상 patch pair로 구성됩니다.
기본적으로 학습이 이루어질 때 main patch와 이와 인접한 neighborhood patch로 1쌍이 구성되기 때문입니다.
pos는 position 정보를 약자로 표현한 것인데 논문에서 제시한 self-supervised learning을 진행할 때 classifier가 맞춰야 하는 ground-truth가 됩니다.
예를 들어서, 논문의 Fig. 4의 그림을 기준으로 생각해보자면 해당 케이스에서는 pos가 0이 될 것입니다.
데이터셋이 구성되었다면, 일반적인 딥러닝 학습과 동일하게 batch size를 기준으로 dataloader를 통해 데이터셋을 불러오게 됩니다.
4개의 데이터셋에 대해서 각각 학습해야 하는 것이 아니라, 4개의 데이터셋을 하나의 Concat Dataset으로 구성하여 사용해서 batch 단위로 4개의 데이터셋에 포함된 데이터들이 나오도록 구성합니다.
position 정보를 포함한 데이터셋을 이용해서 $\mathcal{L}_{SSL}$을 계산하고, position 정보가 포함되지 않은 데이터셋을 이용해서 $\mathcal{L}_{SVDD'}$를 계산합니다.
정확히 얘기하자면, position 정보를 포함한 데이터셋은 64x64 patch dataset과 32x32 patch dataset이 있으므로 $\mathcal{L}_{SSL}$은 $\mathcal{L}_{SSL64}$와 $\mathcal{L}_{SSL32}$의 합이 되는 것이죠.
그리고 position 정보를 포함하지 않은 데이터셋도 마찬가지로 64x64 patch dataset과 32x32 patch dataset이 있으므로 $\mathcal{L}_{SVDD'}$은 $\mathcal{L}_{SVDD'64}$와 $\mathcal{L}_{SVDD'32}$의 합이 되는 것입니다.
이를 이용해서 논문에서 나온 대로 $\mathcal{L}_{Patch SVDD} = \lambda\mathcal{L}_{SVDD'} + \mathcal{L}_{SSL}$로 계산해 최종 loss를 계산해줍니다.
그리고 이를 이용하여 Backpropagation을 진행해 classifier와 encoder를 학습시키게 됩니다.
Training 과정이 끝나게 되면, 최종적으로는 학습이 완료된 Encoder를 얻게 됩니다.
코드 상으로는 논문에 나와있는 것처럼 normal patch를 별도로 저장하지는 않습니다.
1.2.1 Encoder 및 classifier 정의
1.2.x 에서는 세부적인 코드를 포함해 설명을 진행합니다.
먼저 Encoder 및 classifier 정의를 수행하는 부분을 살펴봅니다.
# main_train.py (line32 - line41)
with task('Networks'):
enc = EncoderHier(64, D).cuda()
cls_64 = PositionClassifier(64, D).cuda()
cls_32 = PositionClassifier(32, D).cuda()
modules = [enc, cls_64, cls_32]
params = [list(module.parameters()) for module in modules]
params = reduce(lambda x, y: x + y, params)
opt = torch.optim.Adam(params=params, lr=lr)
코드가 여러 가지. py 파일로 저장되어 있는 구조이므로, 찾기 쉽도록 주석을 이용하여 해당 코드가 포함된 파일의 위치와 line의 위치를 적어두겠습니다.
먼저 enc라는 변수로 Encoder를 정의하고, cls_64와 cls_32로 classifier를 정의합니다.
그리고 이를 modules로 합친 뒤, 각 모델에 있는 parameter를 params로 전부 합치고, reduce 함수를 통해서 모두 합쳐줍니다.
optimizer는 논문에 나온 대로 Adam optimizer를 사용하고 있는 모습입니다.
그렇다면 이제 Encoder와 classifier가 어떤 구조로 되어있는지 확인해봐야겠죠?
먼저 Encoder부터 살펴봅니다.
# networks.py line 132 - line 160
class EncoderHier(nn.Module):
def __init__(self, K, D=64, bias=True):
super().__init__()
if K > 64:
self.enc = EncoderHier(K // 2, D, bias=bias)
elif K == 64:
self.enc = EncoderDeep(K // 2, D, bias=bias)
else:
raise ValueError()
self.conv1 = nn.Conv2d(D, 128, 2, 1, 0, bias=bias)
self.conv2 = nn.Conv2d(128, D, 1, 1, 0, bias=bias)
self.K = K
self.D = D
def forward(self, x):
h = forward_hier(x, self.enc, K=self.K)
h = self.conv1(h)
h = F.leaky_relu(h, 0.1)
h = self.conv2(h)
h = torch.tanh(h)
return h
모델은 크게 두 부분으로 되어 있습니다.
self.enc와 self.conv1 + self.conv2입니다.
self.con1과 self.conv2는 너무 단순하니까 별도로 설명은 안 드려도 될 것 같고요.
self.enc를 보면 EncoderDeep으로 되어 있는 것을 알 수 있죠? 이걸 또 살펴봐야겠네요.
# networks.py line 75 - line 116
class EncoderDeep(nn.Module):
def __init__(self, K, D=64, bias=True):
super().__init__()
self.conv1 = nn.Conv2d(3, 32, 3, 2, 0, bias=bias)
self.conv2 = nn.Conv2d(32, 64, 3, 1, 0, bias=bias)
self.conv3 = nn.Conv2d(64, 128, 3, 1, 0, bias=bias)
self.conv4 = nn.Conv2d(128, 128, 3, 1, 0, bias=bias)
self.conv5 = nn.Conv2d(128, 64, 3, 1, 0, bias=bias)
self.conv6 = nn.Conv2d(64, 32, 3, 1, 0, bias=bias)
self.conv7 = nn.Conv2d(32, 32, 3, 1, 0, bias=bias)
self.conv8 = nn.Conv2d(32, D, 3, 1, 0, bias=bias)
self.K = K
self.D = D
def forward(self, x):
h = self.conv1(x)
h = F.leaky_relu(h, 0.1)
h = self.conv2(h)
h = F.leaky_relu(h, 0.1)
h = self.conv3(h)
h = F.leaky_relu(h, 0.1)
h = self.conv4(h)
h = F.leaky_relu(h, 0.1)
h = self.conv5(h)
h = F.leaky_relu(h, 0.1)
h = self.conv6(h)
h = F.leaky_relu(h, 0.1)
h = self.conv7(h)
h = F.leaky_relu(h, 0.1)
h = self.conv8(h)
h = torch.tanh(h)
return h
nn.Conv2d를 8개 쌓고, 중간에 activation function은 leaky_relu를 사용하였으며 마지막은 tanh를 사용한 구조가 되겠네요.
그렇다면, 사실상 Encoder는 EncoderDeep(conv 8개) + self.conv1 + self.conv2로 총 10개의 conv layer가 쌓인 형태라는 사실을 확인할 수 있겠습니다.
다음으로는 Classifier를 한번 살펴보겠습니다.
# networks.py line 214 - line 265
class PositionClassifier(nn.Module):
def __init__(self, K, D, class_num=8):
super().__init__()
self.D = D
self.fc1 = nn.Linear(D, 128)
self.act1 = nn.LeakyReLU(0.1)
self.fc2 = nn.Linear(128, 128)
self.act2 = nn.LeakyReLU(0.1)
self.fc3 = NormalizedLinear(128, class_num)
self.K = K
def save(self, name):
fpath = self.fpath_from_name(name)
makedirpath(fpath)
torch.save(self.state_dict(), fpath)
def load(self, name):
fpath = self.fpath_from_name(name)
self.load_state_dict(torch.load(fpath))
def fpath_from_name(self, name):
return f'ckpts/{name}/position_classifier_K{self.K}.pkl'
@staticmethod
def infer(c, enc, batch):
x1s, x2s, ys = batch
h1 = enc(x1s)
h2 = enc(x2s)
logits = c(h1, h2)
loss = xent(logits, ys)
return loss
def forward(self, h1, h2):
h1 = h1.view(-1, self.D)
h2 = h2.view(-1, self.D)
h = h1 - h2
h = self.fc1(h)
h = self.act1(h)
h = self.fc2(h)
h = self.act2(h)
h = self.fc3(h)
return h
함수들이 여러 개 있기는 하지만, 결국은 fully connected layer 3개로 이루어진 구조네요.
1.2.2 데이터 셋 불러오기
다음 단계는 데이터셋을 불러오게 됩니다.
코드상에서는 다음과 같습니다.
# main_train.py line 57 - line 59
with task('Datasets'):
train_x = mvtecad.get_x_standardized(obj, mode='train')
train_x = NHWC2NCHW(train_x)
mvtecad의 get_x_standardized를 확인하면 될 것 같습니다.
# mvtecad.py line 70 - line 73
def get_x_standardized(obj, mode='train'):
x = get_x(obj, mode=mode)
mean = get_mean(obj)
return (x.astype(np.float32) - mean) / 255
fpattern으로 obj의 mode에 해당하는 모든 데이터의 경로를 가져오고, 이를 sorted 해서 fpaths에 저장합니다.
그리고 imread 함수를 이용해서 fpaths에 있는 이미지 데이터들을 다 가져와 list로 만든 다음 이를 numpy array로 변경합니다.
imread는 imageio라는 패키지에 있는 함수로, 이미지를 불러오는 함수입니다.
그러고 나서 resize라는 함수를 적용해서 이미지를 resizing 시켜줍니다.
# mvtecad.py line 20 - line 21
def resize(image, shape=(256, 256)):
return np.array(Image.fromarray(image).resize(shape[::-1]))
resize는 이미지를 256 x 256의 형태로 바꿔주는 역할을 합니다.
따라서, get_x를 통해서 training image를 256 x 256으로 resize 시켜서 가져오고, get_mean을 통해서 평균을 구하고, 이를 get_x_standardized 함수에서 사용하여 이미지에서 평균을 빼고 255로 나누어 기본적인 전처리를 해줍니다.
255로 나눈다는 것은 0 ~ 255의 value space를 가지도록 만드는 게 아니라, 0 ~ 1의 value space를 가지도록 만들어준다는 것을 의미한다고 보시면 되겠습니다.
그리고 NHWC2NCHW 함수는 이름만 봐도 알겠지만 데이터의 차원을 변경해주는 함수가 되겠습니다.
Patch SVDD에서는 repeat이라는 parameter를 입력받게 되는데, 이는 1장당 패치를 몇 개 뽑을지를 결정한다고 보시면 되겠습니다.
따라서 __len__의 return이 N * self.repeat이 되는 것이죠.
__getitem__쪽도 보게 되면, N = self.x.shape[0] 이므로 train_x의 데이터셋 크기가 되고 n = idx % N 이므로 data의 index를 N으로 나눈 결과라고 보시면 되겠습니다.
다음으로 p1, p2, pos = generate_coords_position(256, 256, K)로 만들어지는 것을 보실 수 있는데요.
이는 다음 코드를 통해서 얻게 됩니다.
# datasets.py line 9 - line 40
def generate_coords(H, W, K):
h = np.random.randint(0, H - K + 1)
w = np.random.randint(0, W - K + 1)
return h, w
pos_to_diff = {
0: (-1, -1),
1: (-1, 0),
2: (-1, 1),
3: (0, -1),
4: (0, 1),
5: (1, -1),
6: (1, 0),
7: (1, 1)
}
def generate_coords_position(H, W, K):
with task('P1'):
p1 = generate_coords(H, W, K)
h1, w1 = p1
pos = np.random.randint(8)
with task('P2'):
J = K // 4
K3_4 = 3 * K // 4
h_dir, w_dir = pos_to_diff[pos]
h_del, w_del = np.random.randint(J, size=2)
h_diff = h_dir * (h_del + K3_4)
w_diff = w_dir * (w_del + K3_4)
h2 = h1 + h_diff
w2 = w1 + w_diff
h2 = np.clip(h2, 0, H - K)
w2 = np.clip(w2, 0, W - K)
p2 = (h2, w2)
return p1, p2, pos
generate_coords의 경우는 H와 W, K를 입력으로 받고 랜덤으로 좌표를 만들어주게 됩니다.
예를 들어서, 이미지가 256 x 256이고 우리가 생각하는 패치의 사이즈가 64x64라면
가로와 세로의 좌표가 0부터 192 사이에서 뽑혀야 가로 세로로 64만큼 뽑을 수 있겠죠?
그 좌표를 뽑아준다고 보시면 되겠습니다.
다음으로는 generate_coords_position인데요.
위 함수와 동일하게 H, W, K를 받게 되고요.
generate_coords를 통해서 뽑은 h와 w를 각각 h1, w1로 저장합니다.
그리고 랜덤으로 0부터 7까지의 숫자를 뽑아서 이를 pos로 저장하게 됩니다.
다음으로는 J = K // 4로 지정하고, K3_4 = 3 * K // 4로 지정한 다음
h_dir, w_dir로 곱해줄 상수를 결정합니다. 기준이 되는 patch를 기준으로 3x3 grid를 생각했을 때 하나를 결정하는 것이죠.
그리고 h_del, w_del로 2차원으로 0부터 J-1까지의 숫자 중에 랜덤 하게 뽑아주게 됩니다.
h_diff는 h_dir(3x3 grid 기준 위치)와 h_del + K3_4를 곱해줘서 결정하고, 이를 아까 앞에서 뽑아둔 h1과 w1에 더해줍니다.
그리고 np.clip을 통해서 만약 H-K나 W-K를 넘어가는 경우 clipping 해줍니다.
이는 뽑히는 위치에 따라서 patch를 실제로 뽑을 수 있는 좌표를 넘어가는 경우들이 있기 때문이죠.
마지막으로 결정된 p1(main patch의 시작점)와 p2(neighbor patch의 시작점), 그리고 neighbor patch의 위치인 pos를 결괏값으로 냅니다.
p1, p2가 결정되었으니, 이를 시작점으로 해서 실제 patch를 잘라내야겠죠?
그 작업이 crop_image_CHW 함수를 이용해서 이루어지게 됩니다.
# utils.py line 83 - line 85
def crop_image_CHW(image, coord, K):
h, w = coord
return image[:, h: h + K, w: w + K]
매우 간단한 함수로 짜져 있는데요.
channel은 그대로 사용하고, 시작점인 h와 w를 기준으로 K만큼 이동한 부분만 뽑아내 줍니다.
main patch와 neighbor patch를 각각 뽑아서 patch1과 patch2로 저장합니다.
그리고 논문에서 언급했던 self-supervised learning 과정에서 shortcuts을 학습하는 것을 방지하고자 RGB에 랜덤 하게 값을 추가해주는 작업이 이루어지고, 추가적으로 noise를 추가해줍니다.
이 작업을 통해서 main patch와 neighbor patch, position의 쌍을 구성하게 됩니다.
뽑히는 patch는 다음과 같은 느낌으로 뽑히게 됩니다.
위의 이미지는 제가 opencv를 이용하여 실제 뽑히는 patch를 MVTec AD의 한 데이터에 직접 적용해서 시각화를 한 자료입니다.
빨간색이 main patch이고, 검은색이 neighbor patch라고 보시면 될 것 같습니다.
다음으로는 SVDD_Dataset인데, 이 부분은 거의 사실상 동일하니까 넘어가겠습니다.
DictionaryConcatDataset이라는 함수로 4개의 데이터셋을 합쳐주게 되는데요.
해당 코드를 보게 되면 데이터가 4개의 key와 이에 해당하는 데이터로 data가 나오는 것을 확인할 수 있습니다.
# utils.py line 44 - line 59
class DictionaryConcatDataset(Dataset):
def __init__(self, d_of_datasets):
self.d_of_datasets = d_of_datasets
lengths = [len(d) for d in d_of_datasets.values()]
self._length = min(lengths)
self.keys = self.d_of_datasets.keys()
assert min(lengths) == max(lengths), 'Length of the datasets should be the same'
def __getitem__(self, idx):
return {
key: self.d_of_datasets[key][idx]
for key in self.keys
}
def __len__(self):
return self._length
다음으로는 DataLoader인데 이는 많이 사용되는 코드니 별도로 설명은 생략하겠습니다.
1.2.4 Loss 계산 및 학습 진행
DataLoader까지 만들었으니, 이제는 DataLoader를 이용해서 데이터를 batch 단위로 뽑아낼 수 있게 됩니다.
이를 통해서 각 batch 단위로 loss를 계산하고, 학습을 진행하게 됩니다.
# main_train.py line 55 - line 72
for i_epoch in range(args.epochs):
if i_epoch != 0:
for module in modules:
module.train()
for d in loader:
d = to_device(d, 'cuda', non_blocking=True)
opt.zero_grad()
loss_pos_64 = PositionClassifier.infer(cls_64, enc, d['pos_64'])
loss_pos_32 = PositionClassifier.infer(cls_32, enc.enc, d['pos_32'])
loss_svdd_64 = SVDD_Dataset.infer(enc, d['svdd_64'])
loss_svdd_32 = SVDD_Dataset.infer(enc.enc, d['svdd_32'])
loss = loss_pos_64 + loss_pos_32 + args.lambda_value * (loss_svdd_64 + loss_svdd_32)
loss.backward()
opt.step()
d가 바로 데이터가 되는 것이고요.
먼저 loss_pos_64부터 계산하는 과정을 살펴보겠습니다.
위에서 PositionClassifier를 소개해드렸는데, 이번에는 infer 부분만 보면 되겠습니다.
# networks.py line 242 - line 250
def infer(c, enc, batch):
x1s, x2s, ys = batch
h1 = enc(x1s)
h2 = enc(x2s)
logits = c(h1, h2)
loss = xent(logits, ys)
return loss
xent = nn.CrossEntropyLoss()
infer에서는 classifier와 encoder, batch를 input으로 받게 됩니다.
loss_pos_64 = PositionClassifier.infer(cls_64, enc, d['pos_64'])이므로 64차원 patch를 받는 classifier인 cls_64와 encoder인 enc, 그리고 데이터셋 중에 64x64 짜리 position 정보를 포함하는 batch를 받게 됩니다.
그리고 batch를 x1s, x2s, ys로 분리하고(x1s이 main patch, x2s가 neighbor patch, ys가 position 정보라고 생각하시면 됩니다.) x1s와 x2s를 각각 encoder에 통과시킨 뒤, 이 둘의 결과를 classifier에 통과시켜서 logit을 얻습니다.
logit과 ys, 즉 position 정보를 기준으로 cross-entropy loss를 계산해서 return 합니다.
loss_pos_32도 사실상 동일한 과정을 통해 얻게 되므로, 생략합니다.
다음으로는 loss_svdd_64를 보겠습니다.
이는 SVDD_Dataset.infer를 이용하게 되는데요.
# datasets.py line 106 - line 114
@staticmethod
def infer(enc, batch):
x1s, x2s, = batch
h1s = enc(x1s)
h2s = enc(x2s)
diff = h1s - h2s
l2 = diff.norm(dim=1)
loss = l2.mean()
return loss
self.N은 self.arr.shape[0]이며 self.arr는 memmap이므로 이는 데이터셋의 크기를 의미한다는 것을 파악할 수 있습니다.
예를 들어서, bottle class의 training set은 (209, 3, 256, 256)인데, 여기서 self.N은 209가 됩니다.
다음으로 self.row_num을 봐야 하는데, 이는 Stride와 K를 기준으로 row가 몇 개 나올지를 나타내게 됩니다.
예를 들어서, 256 x 256 짜리의 이미지에서 64 x 64 짜리 patch를 stride 16을 적용해서 뽑으면 row와 col이 얼마나 나올지를 나타낸다는 것이죠.
(256 - 64) / 16을 하면 12이므로 총 row와 col은 13개가 나옵니다.
따라서 이를 기반으로 training set이 (209, 3, 256, 256)인 경우 K=64, S=16를 적용 시 Dataset의 크기는 209 * 13 * 13개가 됩니다.
다음으로 __getitem__을 살펴보면 np.unravel_index를 통해서 n, i, j를 만드는 모습을 볼 수 있는데요.
np.unravel_index는 처음 보시는 분들도 계시겠지만, 어떤 크기의 데이터에서 원하는 번째의 좌표를 뽑을 수 있게 됩니다.
예시로, (209, 13, 13)에서 12번째 좌표를 뽑는다면, np.unravel_index(12, (209, 13, 13))이 되고 (0, 0, 12)가 output으로 나오게 됩니다.
이를 통해서 데이터셋 전체 중에서 i번째의 좌표를 계속해서 뽑아낼 수 있으며, 이를 이용해서 patch를 뽑아낼 수 있게 되는 것이죠.
image = self.arr[n]를 이용해서 n번째 데이터를 들고 오고, crop_CHW 함수를 이용해서 i, j 좌표에서 K=64 S=16를 적용해서 원하는 위치의 image patch를 뽑게 됩니다.
예를 들어서, (i, j) = (1, 2)이고 K=64, S=16라고 한다면 crop의 시작점은 (16, 32)가 될 것이고, 이를 기준으로 가로 세로로 64씩 만큼 image patch를 뽑을 수 있게 됩니다.
그리고 patch, n, i, j를 데이터셋의 output으로 만들어주게 되죠.
다음으로는 다시 infer 함수로 돌아가 보겠습니다.
embs는 저희가 결과로 저장할 embedding을 나타내고, embs의 shape는 (-1, row, col, D) 형태가 됩니다.
만약 데이터셋이 (209, 3, 256, 256)이고 K=64, S=16, encoder Dim = 64을 적용한다면 결과로 나오게 되는 embedding은 (209, 13, 13, 64)가 됩니다.
다음으로는 for문을 살펴보겠습니다.
for xs, ns, iis, js in loader: 부분인데요.
아까 PatchDataset에서 patch, n, i, j를 output으로 낸다는 얘기를 했었습니다.
즉, xs는 patch가 되며, 이 xs를 encoder에 투입하여 embedding을 얻게 됩니다. 64차원 embedding을 얻는 것이니, 이 embedding은 (Batch size, 64, 1, 1)의 shape를 가집니다. 두 번째 64는 차원을 나타내는 것이라고 보시면 되겠습니다.
그리고 이를 다시 for embed, n, i, j를 이용해서 각 위치에 64차원 embedding을 투입하게 됩니다.
위의 예시를 이용해서 생각해보자면 n, i, j는 (0, 0, 0)부터 (209, 13, 13)까지 총 209 * 13 * 13개가 나오게 될 것이고, 각각에 64차원짜리 embedding을 채워 넣어서 최종적으로는 (209, 13, 13, 64) 짜리 embedding을 완성하게 됩니다.
동일한 방법으로 test set에 대해서도 진행하여 test embedding을 얻게 됩니다.
32차원의 train embedding과 test embedding도 과정은 동일하니 설명은 넘어가도록 하겠습니다.
2.2.2 Nearest normal patch 찾기
2.2.1에서 64차원의 training embedding, 64차원의 test embedding, 32차원의 training embedding, 32차원의 test embedding을 만들었습니다.
논문에서 언급되었듯이, 이제는 embedding space에서 test embedding을 기준으로 가장 가까운 normal patch를 찾는 작업을 진행하게 됩니다.
작업은 모두 동일하게 이루어지니, 64차원 embedding을 기준으로 과정을 설명해보겠습니다.
먼저, embs64에서 emb_tr와 emb_te를 분리합니다.
각각은 64차원의 training embedding과 test embedding을 나타냅니다.
이를 가지고 measure_emb_NN라는 함수를 적용하여 nearest normal patch를 찾아주게 됩니다.
# inspection.py line 102 - line 110
def measure_emb_NN(emb_te, emb_tr, method='kdt', NN=1):
from .nearest_neighbor import search_NN
D = emb_tr.shape[-1]
train_emb_all = emb_tr.reshape(-1, D)
l2_maps, _ = search_NN(emb_te, train_emb_all, method=method, NN=NN)
anomaly_maps = np.mean(l2_maps, axis=-1)
return anomaly_maps
measure_emb_NN는 training embedding과 test embedding을 input으로 받고 nearest normal patch를 연산해주는 함수입니다.
먼저 train_emb_all이라는 변수로 training embedding을 2차원으로 reshape 해주게 됩니다.
예를 들어서 bottle class의 경우, 64차원 training embedding은 (209, 13, 13, 64)이므로, 이를 (209 * 13 * 13, 64)로 바꿔주는 것입니다.
그러고 나서 search_NN라는 함수에 test embedding과 2차원으로 reshape 된 training embedding을 input으로 투입합니다.
# nearest_neighbor.py line 9 - line 28
def search_NN(test_emb, train_emb_flat, NN=1, method='kdt'):
if method == 'ngt':
return search_NN_ngt(test_emb, train_emb_flat, NN=NN)
from sklearn.neighbors import KDTree
kdt = KDTree(train_emb_flat)
Ntest, I, J, D = test_emb.shape
closest_inds = np.empty((Ntest, I, J, NN), dtype=np.int32)
l2_maps = np.empty((Ntest, I, J, NN), dtype=np.float32)
for n in range(Ntest):
for i in range(I):
dists, inds = kdt.query(test_emb[n, i, :, :], return_distance=True, k=NN)
closest_inds[n, i, :, :] = inds[:, :]
l2_maps[n, i, :, :] = dists[:, :]
return l2_maps, closest_inds
아까 만들어놓은 2차원 training embedding을 가지고 KDTree를 만들어주고요.
가장 가까운 train embedding의 index를 저장할 closest_inds와 l2 distance를 저장할 l2_maps를 변수로 저장하고 Ntest, I, J, NN의 shape로 만들어줍니다.
NN은 몇 개의 Nearest normal patch를 찾을지 인데, 우리의 경우에서는 가장 가까운 patch 한 개만 찾으므로, 이는 1로 설정됩니다.
Nest, I, J, D는 test_emb의 shape가 되는데, bottle class의 경우 (83, 13, 13, 64)이므로 각각이 83, 13, 13, 64로 설정됩니다.
다음으로는 for문을 살펴보아야 하는데, 먼저 Ntest에 대해서 for문을 적용합니다. 즉, 이는 test embedding 각각에 대해서 for문을 돈다고 보시면 됩니다.
그리고 for i in range(I)인데, I는 두 번째 차원의 값입니다.
다음으로는 kdt.query를 test_emb[n, i, :, :]를 이용해서 작동시킵니다.
kdt.query는 KDTree를 이용해서 가장 가까운 요소를 찾아주는 코드라고 생각하시면 됩니다.
그리고 test_emb[n, i, :, :]라면 앞의 for문의 n과 i를 이용해서 첫 번째 차원과 두 번째 차원은 골라주고, 나머지 세 번째 차원과 네 번째 차원은 그대로 가져온다는 것을 의미합니다.
예를 들어서, bottle class의 경우 (83, 13, 13, 64)인데, 만약 n =0, i =0이라면 [13, 64] 차원의 데이터가 되겠죠.
이를 이용해서 kdt.query를 적용하게 되면, 가장 가까운 요소가 찾아지고, 이는 [13, 1]의 데이터가 됩니다.
(64차원짜리가 13개가 있는데, 13개 각각이 training embedding 중에서 가장 가까운 데이터를 찾는다 정도로 생각하시면 됩니다. 13개는 딥러닝에서 배치 단위로 데이터를 연산하는 것처럼 한 번에 연산하게 되는 단위? 정도로 보면 되겠네요.)
즉 이는 아까 위에서 언급했던 training embedding을 2차원으로 변경한 (209 * 13 * 13, 64)에서 가장 가까운 요소를 찾은 것이다 라고 보시면 되겠습니다.
이를 closest_inds와 l2_maps에 계속해서 저장해줍니다.
최종적으로 for문 2개를 모두 연산하게 되면, l2_maps와 closest_inds가 만들어지게 되고, 이를 return 해줍니다.
다시 measure_emb_NN로 돌아가면, l2_maps와 closest_inds 중에서 l2_maps만 저장을 하고, 이를 np.mean 해줍니다.
axis = -1인 것을 확인할 수 있는데, 왜냐하면 search_NN을 통해서 얻게 되는 결과물이 (Ntest, I, J, 1)의 shape를 가지기 때문입니다.
이 4차원 데이터를 3차원으로 바꿔주는 역할 정도로 볼 수 있겠네요.
이걸 통해서 anomaly_map을 최종적으로 얻게 됩니다.
bottle class를 기준으로 생각해보면, (209, 13, 13, 64) 짜리 64차원 training embedding과 (83, 13, 13, 64) 짜리 64차원 test embedding을 input으로 집어넣어서 test embedding 기준으로 embedding space에서 가장 가까운 training embedding과의 l2 distance를 다 찾은 뒤, (83, 13, 13) 짜리의 anomaly map을 만들었다! 정도로 이해하면 딱 깔끔한 것 같습니다.
다음으로 살펴볼 내용은 이 anomaly map을 이용해서 실제 논문에서 구현된 anomaly map을 만드는 과정입니다.
논문에서 나온 anomaly map은 이미지의 사이즈와 동일한 사이즈였죠?
그래서 이 (83, 13, 13) 짜리를 (83, 256, 256) 짜리로 만드는 작업이 필요합니다.
이 작업은 distribute_scores라는 함수를 통해서 구현됩니다.
# utils.py line 155 - line 158
def distribute_scores(score_masks, output_shape, K: int, S: int) -> np.ndarray:
N = score_masks.shape[0]
results = [distribute_score(score_masks[n], output_shape, K, S) for n in range(N)]
return np.asarray(results)
assess_anomaly_maps 함수는 우리가 방금 얻은 anomaly_map을 가지고 segmentation auroc와 detection auroc를 계산하는 함수가 되겠습니다.
detection auroc를 계산할 때는 우리가 구한 anomaly map 중에서 가장 큰 값을 anomaly score로 계산합니다.
(.max(axis=-1).max(axis=-1)를 참고해보시면 됩니다. 이렇게 하면 각 이미지 당 가장 높은 값이 나오게 됩니다.)
위 과정을 32차원 embedding에 대해서도 동일하게 적용하고, 64차원 anomaly map과 32차원 anomaly map을 element-wise addition과 element-wise multiplication을 해주면 최종적으로 모든 결과가 도출되게 됩니다.
여기까지 Training과 Inference에 대한 부분을 대략적으로 살펴보았습니다.
엄청 디테일하게 모든 코드를 다루기에는 코드의 양이 굉장히 많아 조금 어려울법한 내용들을 위주로 조금 디테일하게 설명하였고, 나머지는 대부분 이미 구현된 library를 쓰거나 했기 때문에 조금만 찾아봐도 내용이 나올 것이라고 생각합니다.
3. 실제 코드를 구동하면서 주의해야 할 점
마지막으로는 제가 Patch SVDD 모델을 사용하면서 주의해야 할 점이라고 생각하는 부분입니다.
(1) Dataset의 양이 많아지면 / 데이터의 크기가 크면 연산량이 기하급수적으로 늘어납니다.
저는 제가 연구하고 있는 Custom dataset을 가지고 있는데, training 데이터가 3000장 이상, train 데이터가 약 1000장 정도 가지고 있습니다.
이미지의 크기 또한 해당 모델에서 사용한 256x256보다 훨씬 큰 상황입니다.
따라서 inference를 한 번 시행하는데만 거의 10시간 가까이 소요되므로, 기존 main_train.py에 코드가 짜져 있는 대로 1 epoch 당 AUROC 성능 체크를 진행하게 되면 1 epoch 당 10시간씩 소요되게 됩니다.
그래서 제가 실제로 모델을 사용할 때는 1 epoch 당 AUROC 성능 체크하는 코드를 제외했습니다.
그리고 기존 코드에서 구현되어 있지 않았던 epoch 당 loss graph를 만들어주는 코드를 추가하여 loss가 정상적으로 우하향하는지를 점검하는 방식으로 변경하였습니다.
데이터셋의 양이 많아지면 연산량이 기하급수적으로 늘어나는 이유는, inference 시 Nearest normal patch를 찾아줘야 하는데 이미지의 사이즈가 커지면 당연히 embedding vector의 크기도 커지고 데이터의 양이 많아지면 전체적인 장수가 많아지므로 search 해줘야 하는 대상인 test embedding도 늘어나고 search 할 대상인 train embedding도 늘어나면서 전체적으로 연산량이 증가하게 됩니다.
(2) Dataset마다 최적의 lambda를 찾아줘야 합니다.
Dataset마다 최적의 lambda가 다릅니다.
논문에서도 언급되었지만, 데이터셋에 있는 이미지들의 특성에 따라서 lambda가 커야 좋을 수도 있고 작아야 좋을 수도 있기 때문이죠.
따라서 자신이 사용하는 Dataset에 적합한 lambda가 얼마일지는 실험을 통해서 찾아야만 합니다.
제 경우에서는 lambda를 올리면 성능이 떨어지게 되어, 0.001을 사용하고 있습니다.
저자의 Github에는 이와 관련된 Issue들이 올라온 상태이며, 저자가 추가적으로 설명해주고 있으니 이를 참고해보시면 좋을 듯합니다.
논문에서 제시하는 모델에 대한 설명은 Section 3에 나오므로, 모델 부분만 살펴보실 분들은 Section 3로 가주시면 되겠습니다.
그럼 시작해보겠습니다.
Abstract
이번 논문에서, 저자들은 image anomaly detection 및 segmentation 문제를 다룹니다.
Anomaly detection은 input image가 이상을 포함하고 있는지 아닌지를 결정하는 문제이고, anomaly segmentation은 pixel level에서 anomaly가 어디에 위치해 있는지 파악하는 것을 목표로 합니다.
Support vector data description (SVDD)는 anomaly detection을 위해서 오랫동안 사용되어온 알고리즘인데요, 본 논문에서 저자들은 이 알고리즘을 self-supervised learning을 사용하는 patch 기반의 딥러닝 방법론으로 확장하게 됩니다.
이러한 확장을 통해서 MVtec AD dataset에서 AUROC 기준으로 기존 SOTA method 대비 anomaly detection은 9.8%, anomaly segmentation은 7.0%의 성능 향상을 확인할 수 있었습니다.
1. Introduction
Anomaly detection은 input이 anomaly를 포함하고 있는지 아닌지를 결정하는 문제입니다.
이상을 탐지하는 것은 제조업이나 금융 산업에서 많이 마주할 수 있는 중요하고도 오래된 문제라고 할 수 있습니다.
(제조업에서는 제품을 생산하게 되면 생산된 제품이 양품인지 불량품인지를 판단해야 한다는 관점에서 이상 탐지가 필요하고, 금융 산업에서는 부정 거래 탐지 같은 것들이 되겠습니다. 예를 들어서, 한 달에 50만 원씩 쓰던 어떤 사용자가 갑자기 1000만 원짜리 제품을 구매하면 카드사에서 연락이 오게 됩니다. 일반적인 거래 패턴과는 다른 거래이기 때문에, anomaly로 탐지가 되는 것이죠.)
Anomaly detection은 보통 one-class classification으로 표현이 되는데, 이는 학습 도중에 분포를 모델링하는 데 있어서 비정상 샘플에 대한 접근이 불가능하거나 혹은 매우 불충분하기 때문입니다.
이미지 데이터에 대해서 생각해보면, 검출된 anomaly는 이미지 내 어떤 구역에 위치하게 되고 anomaly segmentation은 pixel level에서 anomaly의 위치를 찾아내는 문제입니다.
본 논문에서는 image anomaly detection과 anomaly segmentation 문제를 다룹니다.
One-class support vector machine (OC-SVM)과 support vector data description (SVDD)는 one-class classification에 사용되는 고전적인 알고리즘인데요.
OC-SVM은 kernel function이 주어졌을 때 원점으로부터 margin을 최대로 하는 hyperplane을 찾게 됩니다.
이와 유사하게, SVDD는 kernel space에서 데이터를 둘러싸는 hypersphere를 찾게 됩니다.
추후에, Ruff et al.은 SVDD를 딥러닝을 통해서 구현한 Deep SVDD를 제안하였고 이는 kernel function을 별도로 정해줘야 하는 기존의 방법론과는 달리 neural network를 통해서 kernel function을 대체하였습니다.
본 논문에서 저자들은 Deep SVDD를 patch-wise detection method로 확장하는 Patch SVDD를 제안합니다.
Patch SVDD는 상대적으로 높은 patch의 클래스 내 변동에도 강건하고, self-supervised learning에 의해서 더욱 강건해지게 됩니다.
Fig. 1은 제안된 방법론을 사용하여 anomaly의 위치를 파악하는 예시를 보여주고 있습니다.
2. Background
2.1 Anomaly detection and segmentation
Problem formulation
Anomaly detection은 input이 anomaly인지 아닌지를 결정하는 문제입니다.
Anomaly의 정의는 작은 결함에서부터 out-of-distribution image까지를 포함하게 되는데요.
(out-of-distribution image라고 한다면, 고양이 이미지만 가득한 dataset에 개 이미지만 있다고 생각해주시면 쉬울 것 같습니다.)
저자들은 전자에 해당하는 image 내에서의 결함을 찾는 것에 초점을 두고 있습니다.
일반적인 detection method는 input의 abnormality를 측정하는 scoring function $A_\theta$를 학습하는 과정을 포함하게 되는데요.
Test를 진행할 때는, 학습된 scoring function을 사용하여 높은 $A_\theta(x)$를 가진 input이 anomaly로 결정되게 됩니다.
scoring function에 대한 사실상 표준적인 지표는 Eq. 1로 표현되는 area under the receiver operating characteristic curve (AUROC)입니다.
Eq. 1
따라서, 좋은 scoring function은 normal data에 낮은 anomaly score를 매기고, abnormal data에 높은 anomaly score를 매길 수 있어야 합니다.
Anomaly segmentation도 유사하게 표현될 수 있는데, 각 pixel에 대한 anomaly score를 만들고(즉, anomaly map) 각 pixel에 대한 AUROC를 측정하는 것입니다.
Autoencoder-based methods
초기의 anomaly detection에 대한 deep learning approach는 autoencoder를 사용하는 것이었습니다.
이러한 autoencoder는 normal training data에만 학습되고, abnormal image에 대해서는 정확한 복원을 할 수 없게 됩니다.
따라서, input과 복원된 결과와의 차이가 abnormality를 나타내게 됩니다.
이후에 structural similarity indices, adversarial training, negative mining, iterative projection 등을 활용하는 연구들이 진행되었습니다.
과거 연구들 중 일부는 autoencoder의 학습된 latent feature를 anomaly detection에 활용하기도 했는데요.
Akcay et al. 은 latent feature의 reconstruction loss를 anomaly score로 정의하였고, Yarlagadda et al. 은 latent feature를 활용해 OC-SVM을 학습시키기도 했습니다.
더 최근에는, reconstruction loss보다도 restoration loss나 attention map과 같은 다른 요소들을 활용한 방법론들이 제안되었습니다.
Classifier-based methods
Golan et al의 연구 이후에, discriminative approach가 anomaly detection에 제안되어 왔습니다.
이러한 방법론들은 비정상 input image에 대해서 classifier가 confidence를 잃게 되는 현상을 사용하였습니다.
(예를 들어서, 어떤 classifier가 개, 고양이, 곰을 분류한다고 했을 때 개나 고양이, 곰의 이미지가 들어가게 되면 80%나 90% 이상으로 매우 높게 예측을 하게 됩니다. 하지만, 갑자기 새 이미지를 주고 예측을 하게 만들면 어쨌든 개, 고양이, 곰 중 하나로 예측을 하긴 하겠지만 80%나 90%처럼 높게 예측하지 않고 40%나 50%처럼 낮은 확률로 어떠한 class로 예측하게 됩니다.)
Unlabeled dataset이 주어졌을 때, classifier는 가상의 label을 예측하고자 학습하게 됩니다.
예를 들어서, Golan et al에서는 image를 random flip, rotate, translate 시킨 다음, classifier가 수행된 transformation의 유형을 예측하도록 만들게 됩니다.
만약 classifier가 confident 하고 correct 한 prediction을 만들 수 없다면, input image를 abnormal로 예측하게 됩니다.
Wang et al. 은 이러한 접근법이 training data 또한 anomaly를 일부 포함하는 unsupervised 상황에도 확장될 수 있음을 증명하였습니다.
Bergman et al.은 open-set classification method를 채택하여 non-image data를 포함시키고자 해당 방법론을 일반화시켰습니다.
SVDD-based methods
SVDD는 고전적인 one-class classification 알고리즘입니다.
이는 모든 normal training data를 predefined kernel space로 mapping 시키고, kernel space에 존재하는 모든 데이터를 감싸는 가장 작은 hypersphere를 찾게 됩니다.
anomaly는 학습된 hypersphere 바깥쪽에 위치할 것으로 예상할 수 있습니다.
kernel function이 kernel space를 결정하므로, 학습 과정에서는 hypersphere의 반지름과 중심을 주로 결정하게 됩니다.
Ruff et al. 은 이러한 접근법을 deep neural network를 활용하여 향상시켰습니다.
이들은 kernel function을 대체하고자 neural network를 채택하였고 hypersphere의 반지름을 가지고 학습시켰습니다.
이러한 변형을 통해 encoder는 data-dependent transformation을 학습할 수 있게 되었고, high-dimensional and structured data에서 detection 성능을 향상시키게 되었습니다.
이미지에서 representation을 학습하는 것은 computer vision에서 중요한 문제이며, image의 representation을 annotation 없이 학습할 수 있는 여러 방법론들이 제안되어 왔는데요.
여러 연구분야 중 하나는 synthetic learning signal을 제공하기 위한 self-labeled task인 pretext task를 가지고 학습하는 encoder를 training 시키는 것입니다.
network가 pretext task를 잘 풀도록 학습된다면, network는 의미 있는 feature를 추출할 수 있을 것이라고 기대할 수 있겠죠.
pretext task로는 relative patch location을 예측하는 것, jigsaw puzzle를 푸는 것, colorizing images, counting objects, prediction rotations 등이 있습니다. (뒤에서 보시면 아시겠지만, 해당 논문은 relative patch location을 예측하는 것을 이용하여 self-supervised representation learning을 수행하게 됩니다.)
3. Methods
해당 Section에서는 본격적으로 본 논문에서 제시하는 방법론에 대해서 설명합니다.
3.1 Patch-wise Deep SVDD
Deep SVDD는 전체 training data를 feature space에서 작은 hypersphere 안으로 들어오도록 mapping 시키는 encoder를 학습하게 되는데요.
Test를 진행할 때는 input의 representation과 center 사이의 거리가 anomaly score가 됩니다.
(앞에서 언급했었지만, 데이터를 가장 작은 hypersphere 안으로 들어가게끔 학습하므로, input의 representation이 hypersphere의 중심과 거리가 크다는 것은 hypersphere의 바깥쪽에 위치한다는 것임을 알 수 있겠죠.)
center $c$는 Eq. 3의 방법을 통해서 학습 이전에 계산됩니다. $N$는 training data의 수를 나타내고요.
Eq. 3
따라서, 학습을 통해서 feature들을 하나의 중심 주변으로 밀게 됩니다.
본 논문에서 저자들은 Deep SVDD를 patch 단위로 확장시키게 됩니다. Encoder는 Fig. 2에서 보이는 것처럼 이미지 전체를 encoding 하는 게 아니라, patch를 encoding 하도록 변경합니다.
Fig. 2
이에 따라서, inspection이 각 patch에 대해서 수행되게 됩니다.
Patch-wise inspection은 여러 가지 장점을 가지고 있는데, 첫 번째로 inspection이 각 position에 대해 수행할 수 있으므로 해당 방법론을 사용했을 때 defect의 위치를 찾을 수 있게 되며, 두 번째로, 이러한 작업이 전반적으로 detection 성능을 향상시키게 됩니다.
Deep SVDD를 patch-wise inspection으로 확장하는 것은 직관적인데요.
Classifier가 shortcuts을 활용하는 것을 방지하고자(예를 들어, color aberration), 저자들은 patch의 RGB channel을 임의로 perturb 하였습니다.
논문에서는 별도로 shortcuts이 무엇인지 언급되지 않았으나, 인용한 논문을 찾아보니 다음과 같은 내용을 찾을 수 있었습니다.
Shortcuts have been described as “trivial solutions” to the pretext task that must be avoided to “ensure that the task forces the network to extract the desired information”
In other words, shortcuts are easily learnable features that are predictive of the pretext label, and allow the network to stop learning once found.
위 내용에 따르면, Shortcuts은 소위 trivial solution(자명한 해)이며 이를 찾으면 network가 학습을 멈추게 만든다고 합니다.
즉, RGB channel을 별도로 perturb 하는 것은 어떻게 보면 useful feature를 찾아낼 수 있도록 하는 역할을 하는 것 같습니다.
Doersch et al. 의 접근법을 따라서, 다음과 같은 loss term을 추가하여 self-supervised learning signal을 추가합니다.
그 결과로, encoder는 Eq. 6에서 볼 수 있듯이 scaling hyperparameter $\lambda$를 이용한 두 loss의 combination을 사용해 학습이 이루어지게 됩니다.
최적화는 SGD와 Adam optimizer를 이용해 이루어집니다.
Eq. 6
3.3 Hierarchical encoding
anomaly의 크기가 다양하기 때문에, 다양한 receptive field를 가지는 여러 개의 encoders를 사용하는 것은 크기의 변화에 대응할 수 있도록 도움을 줄 수 있습니다.
Section 4.2에서 다룰 실험 결과는 encoder에서 hierarchical structure를 사용하는 것이 anomaly detection 성능에도 도움을 준다는 것을 나타냅니다.
따라서, 저자들은 작은 encoder를 포함하는 hierarchical encoder를 사용하였습니다.
hierarchical encoder는 다음과 같이 정의될 수 있습니다.
Fig. 5에서 볼 수 있듯이 input patch $p$는 2 x 2 grid로 분할되고 이들의 feature는 $p$의 feature를 구성하기 위해 합쳐지게 됩니다.
receptive field size $K$를 가진 각 encoder는 patch size $K$의 self-supervised task를 이용해 학습이 이루어지게 됩니다.
실험이 진행되는 동안, large encoder와 small encoder의 receptive field는 각각 64, 32로 정해집니다.
3.4 Generating anomaly maps
Encoders를 학습한 후에, encoder로부터 얻게 되는 representation은 anomaly를 탐지할 때 사용됩니다.
첫 번째로, 모든 normal train patch의 representation {$f_\theta(p_{normal}) | p_{normal}$}은 계산되고 저장됩니다.
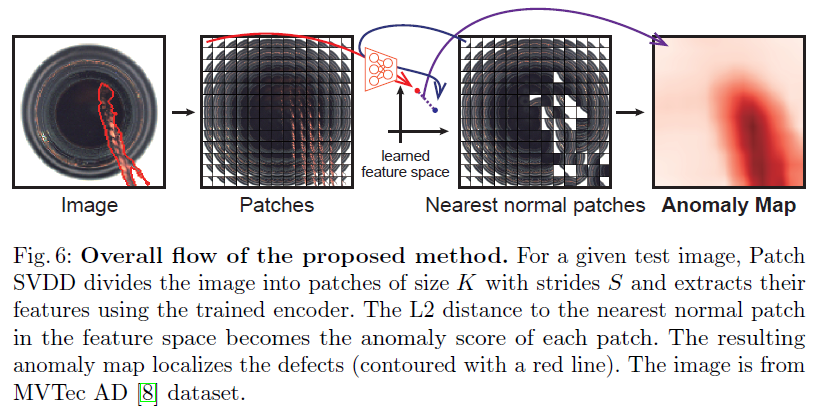
Query image $x$가 주어졌을 때, $x$에서 stride $S$를 이용해서 얻어지는 모든 patch $p$에 대해 feature space에서 가장 가까운 normal patch까지의 L2 distance는 anomaly score로 정의됩니다. (Eq. 8)
그 결과로, MVTec AD의 이미지 한 개에 대한 inspection은 대략 0.48초 정도 걸리게 됩니다.
Patch-wise로 계산된 anomaly score는 pixel로 분배가 되는데요.
그 결과로, 각 pixel들은 자신이 속한 모든 patch의 average anomaly score를 받게 되며 그 결과로 얻게 되는 anomaly map을 $\mathcal{M}$으로 표기합니다.
Section 3.3에서 논의한 multiple encoder는 multiple feature space를 구성하게 되며, 이에 따라 multiple anomaly map을 만들어냅니다.
저자들은 multiple anomaly map을 element-wise multiplication을 사용해 최종 anomaly map $\mathcal{M}_{multi}$를 얻게 되며 이는 anomaly segmentation 문제에 대한 answer가 됩니다.
$\mathcal{M}_{multi}$와 $\mathcal{M}_{big}$은 각각 $f_{small}$과 $f_{big}$을 사용해서 만들어지는 anomaly map입니다.
$\mathcal{M}_{multi}$에서 높은 anomaly score를 가지는 pixel이 defect을 포함하고 있다고 판단됩니다.
anomaly detection 문제를 해결하는 것은 간단한데요.
Eq. 10으로 표현된 것처럼, 이미지 내에서 가장 높은 anomaly score를 가지는 pixel이 해당 이미지의 anomaly score가 됩니다.
Eq. 10
Fig. 6은 제안된 방법론의 전체적인 흐름을 나타내고, pseudo-code는 Appendix A1에서 제공되고 있습니다.
Fig. 6
Appendix A1(train)
Appendix A1(test)
논문에는 해당 Pseudo-code가 제시되어 있는데, 실제 코드 구현과는 다른 내용이 있어 실제로 해당 논문을 사용하실 것이라면 반드시 코드 내용을 살펴보셔야 할 것 같습니다.
다음 포스팅인 code review에서는 실제 공개된 코드를 기반으로 위에 제시된 Pseudo-code를 수정해볼 예정입니다.
4. Results and Discussion
제안된 방법론의 유효성을 검증하고자, 저자들은 MVTec AD dataset에 이를 적용하였습니다.
MVTec dataset은 15개 class의 산업 이미지로 구성되어 있고, 각 class는 object 혹은 texture로 분류됩니다.
10개의 object class는 규칙적으로 배치된 object를 포함하고 있으며, 반면에 texture class는 반복적인 패턴을 포함하고 있습니다.
4.1 Anomaly detection and segmentation results
Fig. 7은 제안된 방법론을 사용하여 만들어진 anomaly map을 보여주고 있으며, defect의 크기에 상관없이 적절하게 찾아내는 것을 나타냅니다.
Fig. 7
Table 1은 AUROC 기준으로 SOTA baseline과 비교했을 때 MVTec AD dataset에서의 detection and segmentation 성능을 보여줍니다.
Patch SVDD는 autoencoder-based 방법론과 classifier-based 방법론을 포함하는 powerful baseline에 비해서 SOTA 성능을 내고 있으며, Deep SVDD에 비해 55.6% 향상을 보여주고 있습니다.
4.2 Detailed analysis
t-SNE visualization
Fig. 8은 여러 train image의 학습된 feature의 t-SNE visualization을 보여줍니다.
Fig. 8(b)에 보이는 points에 위치한 patch는 Fig. 8(a)과 Fig. 8(c)에 있는 동일한 색과 동일한 크기를 가지는 point에 mapping 됩니다.
Fig. 8(a)에서, 유사한 색과 사이즈를 가진 points는 feature space에서 cluster를 형성하고 있습니다.
cable class에 있는 이미지들이 규칙적으로 배치되어 있으므로, 다른 이미지에서 나왔더라도 같은 위치에서 나온 patch는 유사한 content를 가지고 있습니다.
유사하게, 규칙적으로 배치된 object classes의 경우, t-SNE visualization에서 유사한 색과 크기를 가진 points는 semantically similar라고 생각될 수 있습니다.
대조적으로, Fig. 8(c)에 나타난 leather class의 feature는 반대 경향을 보입니다.
이는 texture class에 있는 patches들이 이미지 내에서의 위치와는 상관없이 유사하기 때문입니다.
즉, texture image에 대해서는 patch의 위치가 이들의 semantics와는 전혀 관련이 없습니다.
Effect of self-supervised learning
Patch SVDD는 $\mathcal{L}_{SVDD'}$와 $\mathcal{L}_{SSL}$이라는 두 개의 loss를 사용해서 encoder를 학습시키는데요.
제안된 loss term의 역할을 비교하기 위해서, 저자들은 ablation study를 수행했습니다.
Table 2는 $\mathcal{L}_{SVDD}$를 $\mathcal{L}_{SVDD'}$로 변경한 것과 $\mathcal{L}_{SSL}$을 도입한 것이 anomaly detection과 segmentation 성능을 향상시킨다는 것을 제안하고 있습니다.
Fig. 9는 제안된 loss term의 효과가 classes마다 다르다는 것을 보여줍니다.
특히, texture classes (예를 들어, tile이나 wood)는 loss의 선택에 덜 민감하지만, cable과 transistor를 포함하는 object classes는 $\mathcal{L}_{SSL}$을 사용하는 것이 큰 도움이 되었음을 나타냅니다.
이러한 관측의 이유를 알아보기 위해, 저자들은 $\mathcal{L}_{SVDD}$, $\mathcal{L}_{SVDD'}$, $\mathcal{L}_{SVDD'} + \mathcal{L}_{SSL}$을 이용해 학습된 encoder를 통해 얻은 object class의 feature에 대해서 t-SNE visualization을 수행하였습니다. (Fig. 10)
학습이 $\mathcal{L}_{SVDD}$ (Fig. 10(a))나 $\mathcal{L}_{SVDD'}$ (Fig. 10(b))를 이용해서 이루어졌을 때, feature는 uni-modal cluster를 형성하는 것을 확인할 수 있습니다.
대조적으로, $\mathcal{L}_{SSL}$은 color나 size와 같은 semantics를 기반으로 Fig. 10(c)에서 보이는 것과 같이 multi-modal feature cluster를 만들어내는 것을 확인할 수 있습니다.
이러한 feature의 multi-modal property는 특히 patch 간에 높은 클래스 내 variation을 가지는 object classes에 도움이 됩니다.
다른 semantics를 가진 patch들의 feature는 분리되며, 이러한 feature를 사용하는 anomaly inspection는 더욱 정교하고 정확해지게 됩니다.
Hierarchical encoding
Section 3.3에서 hierarchical encoder의 사용을 제안하였는데요.
Fig. 12는 multiple encoder로부터 나온 multi-scale result를 aggregate 하는 것이 inspection performance를 향상시킨다는 것을 보여줍니다.
추가적으로, non-hierarchical encoder를 사용한 ablation study는 hierarchical structure 자체가 성능을 향상시킴을 보여줍니다.
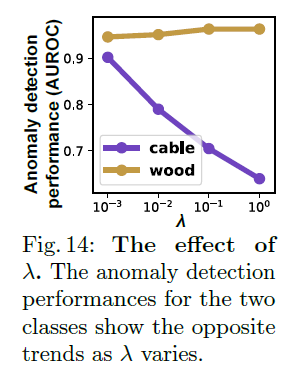
Hyperparameters
Eq. 6에서 볼 수 있듯이, hyperparameter $\lambda$는 $\mathcal{L}_{SVDD'}$와 $\mathcal{L}_{SSL}$ 사이의 균형을 맞추는 역할을 하게 됩니다.
큰 $\lambda$는 feature의 gathering을 강조하고, 작은 $\lambda$는 informativeness를 촉진시키게 됩니다.
놀랍게도, 가장 유리한 $\lambda$는 class에 따라 다릅니다.
object class에서의 anomaly는 작은 $\lambda$ 하에서도 잘 탐지되지만, texture class의 경우는 큰 $\lambda$ 하에서 잘 탐지되게 됩니다.
Fig. 14는 이러한 차이의 예시를 보여줍니다. 즉, cable class (object)는 $\lambda$가 감소함에 따라 detection performance가 향상되지만, 반면에 wood class (texture)는 반대의 경향을 보여주고 있습니다.
5. Conclusion
본 논문에서, 저자들은 image anomaly detection과 segmentation을 위한 방법론인 Patch SVDD를 제안하고 있습니다.
Deep SVDD와는 다르게, 이미지를 patch level에서 점검하며 defect의 위치를 확인할 수 있습니다.
게다가, 추가적인 self-supervised learning은 detection performance를 향상해줍니다.
그 결과로, 제안된 방법론은 MVTec AD dataset에서 SOTA performance를 달성하였습니다.
여기까지 Patch SVDD 논문 리뷰를 마무리하려고 합니다.
논문 내용 중 일부는 제가 생략한 부분도 있어, 관심이 있으시다면 본 논문을 참고하시면 되겠습니다.
단순히 이미지를 통째로 feature space에 mapping 하는 것이 아닌, patch 단위로 mapping 하므로 조금 더 localized defect을 잘 찾을 수 있다는 것이 큰 특징이라고 볼 수 있을 것 같습니다.
제가 현재 연구하고 있는 부분도 큰 이미지에서 굉장히 작은 크기의 결함 부위를 탐지하는 것을 진행하고 있는데, 이러한 연구에 있어서 굉장히 괜찮은 방법론이라고 생각되어 리뷰를 진행하게 되었습니다.
다음 포스팅에서는 해당 논문의 code review를 진행할 예정입니다.
이전에는 논문에서 제시하는 모델 하나를 리뷰했었기 때문에 모델 architecture를 위주로 code review를 진행했지만, 해당 논문의 경우 architecture보다는 어떤 방법론으로 anomaly detection을 수행하게 되는지를 봐야 하기 때문에 기존과는 조금 다른 방향으로 code review를 진행하게 될 것 같습니다.
이번 code review에서는 ImageNet Pre-trained resnet50을 이용해서 Grad-CAM을 만들어보면서 code review를 진행해보겠습니다.
물론, resnet50을 받아올 때 pretrained = False로 parameter를 setting 하게 되면 별도의 학습된 weight를 가지고 오지 않으므로, 이를 활용해서 원하시는 custom dataset에 동일한 방법을 사용해 Grad-CAM을 생성하실 수 있습니다.
custom dataset에 활용하는 방법은 제 Github에 구현되어 있으니, 확인해주시면 됩니다.
다만 제가 이번 code review에서 Pre-trained resnet50을 사용하는 이유는, 본 논문에서 제시되었던 Fig. 1을 직접 구현하기 위함입니다.
Fig. 1은 다음과 같습니다.
그럼 본격적으로 시작해보겠습니다.
import torchvision.models as models
import torch.nn as nn
import torch
import os
import cv2
import PIL
import torchvision
import torchvision.transforms as transforms
import datetime
import numpy as np
import torch.nn.functional as F
import matplotlib.pyplot as plt
import matplotlib
from torchvision.utils import make_grid, save_image
device = 'cuda' if torch.cuda.is_available() else 'cpu'
resnet50 = models.resnet50(pretrained = True).to(device)
resnet50.eval()
구현하는데 필요한 library를 불러오고, device를 cuda로 설정하였으며 Pre-trained resnet50를 가져옵니다.
그리고 Grad-CAM에서는 별도로 학습을 진행하지 않으므로, resnet50.eval()을 선언하여 inference mode로 전환합니다.
Guided backpropagation을 보게 되면 gradient가 현재 -2, 3, -1, 6, -3, 1, 2, -1, 3입니다.
여기서 먼저 0보다 큰 부분을 남기면 0, 3, 0, 6, 0, 1, 2, 0, 3이 될 것이고,
relu의 output이 양수인 부분만 다시 한번 걸러서 남겨주게 되면 0, 0, 0, 6, 0, 0, 0, 0, 3이 됩니다.
이와 같은 방식을 코드로 구현한 내용이라고 보시면 되겠습니다.
앞에서 설명드린 대로, Guided Backpropagation은 크게 forward와 backward 두 가지로 나눠서 생각해봐야 합니다.
Forward는 ReLU와 동일합니다.
input_img가 들어왔을 때, 값이 0보다 큰 경우만 남기기 위해 positive_mask를 생성합니다.
예를 들어서, input 값이 [1, -2, 3, -5, 7]이라고 한다면, positive_mask는 [1, 0, 1, 0, 1]이 됩니다.
만들어진 positive_mask를 이용해서, torch.addcmul 함수를 이용해 input_img 중에 양수인 부분만 남기도록 만들어줍니다.
torch.addcmul은 input와 tensor1, tensor2를 입력으로 받고, input + tensor1 x tensor 2를 결과로 내게 되는데 해당 코드에서는 input은 그냥 torch.zeros로 0으로 채워진 tensor를 만들어주고, input_img와 positive_mask를 곱해서 나온 결과를 output으로 만들어줍니다.
그러고 나서 self.save_for_backward 함수를 통해 input과 output을 저장해줍니다.
이렇게 저장을 해두면, backward 단에서 이를 가지고 와서 사용할 수 있게 됩니다.
다음으로는 backward입니다.
먼저 forward에서 저장된 input_img와 output을 self.saved_tensors를 통해서 가져옵니다.
backward에서는 앞에서 그림과 함께 설명한 대로, 두 가지 기준을 만족해야 하는데요.
1) forward에서 relu output이 0보다 큰 부분 / 2) gradient가 0보다 큰 부분이라는 조건을 만족해야 합니다.
따라서 이번에는 positive_mask를 두 개 생성합니다.
positive_mask_1은 input_img가 0보다 큰 부분을, positive_mask_2는 gradient가 0보다 큰 부분을 잡습니다.
그리고 이전과 동일하게 torch.addcmul 함수를 이용해 이 두 개의 mask를 적용해서 최종 결과를 내게 됩니다.
class GuidedBackpropReLUModel:
def __init__(self, model, use_cuda):
self.model = model
self.model.eval()
self.cuda = use_cuda
if self.cuda:
self.model = model.cuda()
def recursive_relu_apply(module_top):
for idx, module in module_top._modules.items():
recursive_relu_apply(module)
if module.__class__.__name__ == 'ReLU':
module_top._modules[idx] = GuidedBackpropReLU.apply
# replace ReLU with GuidedBackpropReLU
recursive_relu_apply(self.model)
def forward(self, input_img):
return self.model(input_img)
def __call__(self, input_img, target_category=None):
if self.cuda:
input_img = input_img.cuda()
input_img = input_img.requires_grad_(True)
output = self.forward(input_img)
if target_category is None:
target_category = np.argmax(output.cpu().data.numpy())
one_hot = np.zeros((1, output.size()[-1]), dtype=np.float32)
one_hot[0][target_category] = 1
one_hot = torch.from_numpy(one_hot).requires_grad_(True)
if self.cuda:
one_hot = one_hot.cuda()
one_hot = torch.sum(one_hot * output)
# 모델이 예측한 결과값을 기준으로 backward 진행
one_hot.backward(retain_graph=True)
# input image의 gradient를 저장
output = input_img.grad.cpu().data.numpy()
output = output[0, :, :, :]
output = output.transpose((1, 2, 0))
return output
다음으로 소개할 내용은 모델을 Guided Backpropagation이 가능한 모델로 바꿔주는 코드입니다.
__init__에서 받는 인자들을 보시면 model과 use_cuda를 받게 되고, 우리의 코드에서는 model = resnet50이고 use_cuda는 True입니다.
recursive_relu_apply라는 함수를 self.model에 적용하는 것을 확인할 수 있는데, 이는 ReLU를 GuidedBackpropReLU로 바꾸게 됩니다. GuidedBackpropReLU는 방금 위에서 설명드린 코드입니다.
실제로 이 모델이 불렸을 때 (call 되었을 때) 작동하는 부분도 보겠습니다.
인자로는 input_img와 target_category를 받게 됩니다. target_category는 어떤 class를 기준으로 Guided Backprop을 시행할지를 결정하는 것이라고 보시면 되겠습니다.
고양이에 대한 그림을 그리고 싶으면 target_category에 cat class에 해당하는 값을 집어넣으면 되고, 개에 대한 그림을 그리고 싶으면 dog class에 해당하는 값을 집어넣으면 됩니다.
먼저 input_img의 requires_grad를 True로 지정하고, 이를 가지고 self.forward로 모델을 통과시킵니다.
즉 이 작업은 이미지가 주어졌을 때, 이를 기반으로 어떤 class인지 예측을 하는 image classification을 작동시킵니다.
그럼 이걸 통해서 예측된 결과가 나오게 되겠죠? 그게 output이라는 변수에 저장됩니다.
one_hot은 output 사이즈만큼 np.zeros로 만들어주는 것이고, one_hot[0][target_category] = 1은 말 그대로 target_category에 해당하는 곳만 1로 만들어줍니다.
예를 들어서 고양이는 281번인데, target_category를 281로 지정하면 one_hot에서 281번째 위치만 1이 되고 나머지는 0이 됩니다.
그리고 이를 torch.from_numpy로 해서 torch Tensor로 바꿔줍니다.
다음으로는 one_hot = torch.sum(one_hot * output)이 되는데, 이는 예측한 값과 one_hot을 곱해 우리가 원하는 class의 예측값만을 빼냅니다.
즉, 고양이를 예로 들자면 고양이가 될 확률을 얼마로 예측했는지를 저장한 것이죠.
그리고 이를 가지고 .backward()를 통해서 backward를 진행합니다.
output이라는 변수로 input image의 gradient를 저장하고, numpy로 바꾼 다음 transpose를 통해 차원의 위치를 바꿔줍니다.
이 작업은 torch에서의 차원 순서 별 의미와 numpy에서의 차원 순서 별 의미가 다르기 때문에 작업합니다.
pytorch에서는 224x224 짜리 RGB 이미지를 (3, 224, 224)로 저장하게 되는데, numpy에서는 (224, 224, 3)으로 저장하기 때문이죠.
finalconv_name을 통해서 어떤 conv layer에서 Grad-CAM을 뽑아낼지 결정합니다.
만약 다른 conv의 결과를 가지고 Grad-CAM을 구현하고 싶다면, 이 부분을 변경하시면 됩니다.
feature_blobs는 forward 단계에서 얻어지는 feature를 저장하는 곳이고, backward_feature는 backward 단계에서 얻어지는 feature를 저장하는 곳입니다.
hook_feature라는 함수를 통해 forward 진행 시 특정한 layer에서 얻어지는 output을 feature_blobs에 저장합니다.
backward_hook이라는 함수를 통해 backward 진행 시 특정한 layer에서 얻어지는 output을 backward_feature에 저장합니다.
resnet50._modules.get(finalconv_name).register_forward_hook(hook_feature)은 forward 단계에서 hook_feature를 적용하도록 만드는 함수이고, 그 밑은 backward 단계에서 backward_hook을 적용하도록 만드는 함수입니다.
forward라는 것은, input image가 주어졌을 때 conv layer들을 거쳐서 최종 output을 내는 과정을 말합니다.
예를 들자면, 어떤 사진이 주어졌을 때, layer들을 거쳐 최종 output으로 해당 이미지가 어떤 종류의 이미지인지를 분류하는 것이죠.
ResNet 논문에 있는 전체 구조 table을 살펴보자면, 마지막 conv을 거치고 나온 결과는 output size가 7x7이고 channel 수가 512입니다.
따라서, forward를 진행하고 나서 이 feature가 feature_blobs에 저장될 것입니다.
Backward는 계산한 output을 가지고 backpropagation을 통해 gradient를 계산하는 과정이라고 보시면 됩니다.
논문에서 "gradients via backprop"이라고 표현된 부분이 바로 위의 코드에서 구현된 부분이라고 보시면 되겠습니다.
의미적으로 본다면, 해당 Activation map($A^k$)이 어떤 예측값에 영향을 준 정도가 되겠죠?
이 또한 마지막 conv을 거치고 나온 결과와 사이즈가 동일하므로, output size가 7x7이고 channel 수가 512가 나옵니다.
# get the softmax weight
params = list(resnet50.parameters())
weight_softmax = np.squeeze(params[-2].cpu().detach().numpy()) # [1000, 512]
# Prediction
logit = resnet50(normed_torch_img)
resnet50에 있는 모든 파라미터를 list로 만들어두고, 여기서 마지막에서 두 번째 파라미터만 빼냅니다
params[-1]은 1000개로 예측할 때 사용된 bias이고, params[-2]는 weight가 됩니다.
이 부분은 모델을 설계할 때 마지막 fc layer에서 bias = False로 지정될 경우 이를 -1로 바꿔줘야 하기 때문에 반드시 모델을 어떻게 설계했는지 확인하셔야 합니다.
아까 만들어뒀던 normalization을 거친 img를 resnet50에 투입하여 결괏값을 냅니다.
코드를 보시면, cv2.cvtColor라는 함수가 보이실 텐데, 이는 color space를 바꿔주는 함수입니다.
기본적으로 opencv는 BGR (Blue, Green, Red) 순으로 데이터를 저장합니다.
따라서, 그냥 cv2.imread를 이용해서 읽게 되면 RGB 데이터를 BGR로 읽은 것이므로 색이 이상하게 나오게 됩니다.
이를 방지하고자 cv2.cvtColor( ~~, cv2.COLOR_BGR2RGB)라는 기능을 사용하게 되는 것입니다.
그리고 cv2.hconcat은 가로로 이미지를 합치는 함수입니다.
이를 통해서 최종적으로 얻어지는 이미지는 다음과 같습니다.
Final Result
맨 위에서 얘기했던 논문의 Fig. 1과 동일한 그림을 얻을 수 있었습니다.
이번 글은 꽤나 내용이 많아 글이 많이 길어졌습니다.
사실 모델 자체가 엄청 복잡하거나 하지는 않지만, forward pass를 통해서 특정한 conv layer를 통과하고 난 이후의 결과를 얻는 방법, backward pass를 거쳐서 얻게 되는 gradient를 저장하는 방법, 이미지의 차원이나 값들을 적절히 처리하는 방법 등 다양한 기술들이 요구되는 코드라고 생각합니다.
저 또한 이렇게 min-max scaling을 했다가, 255로 곱했다가 이런저런 과정들을 거치면서 이미지를 처리해본 경험은 처음이라 많이 헤매면서 만들게 되었습니다.
특히 opencv의 함수를 쓰는 과정에서 np.uint8을 사용하지 않아 오류가 나거나, 이미지가 0 ~ 1 사이의 값이라서 cv2.imwrite를 했을 때 이미지가 검은색으로 저장되거나, color space가 RGB가 아닌 것을 모르고 저장했다가 이미지가 이상한 색으로 저장되는 등 다양한 상황에 부딪힐 수 있었습니다.
어쨌든 우여곡절 끝에 논문에서 나온 그림을 온전히 만들 수 있어서 재미있는 코드 작업이었습니다.
이번 포스팅에서 다룬 코드는 제 Github에서 확인하실 수 있으며, 코드 자체는 .ipynb로 되어 있어 바로바로 출력 결과를 확인하실 수 있습니다.
본 논문의 저자들은 Convolutional Neural Network (CNN) 기반의 모델이 만든 의사결정에 대한 'visual explanations'를 만드는 기술을 제안하며, 이는 CNN 기반의 모델을 더욱 투명하고 설명 가능하게 만듭니다.
저자들이 제안하는 접근법인 Gradient-weighted Class Activation Mapping (Grad-CAM)은 final convolutional layer로 흐르는 target concept (classification network에서는 'dog'가 될 수 있으며, captioning network에서는 word의 sequence가 될 수 있습니다.)의 gradient를 사용해서 concept을 예측할 때 이미지에서 중요한 부분들을 강조하는 coarse localization map을 만들어냅니다.
이전의 접근법과는 달리, Grad-CAM은 더 다양한 CNN 기반 모델에 사용할 수 있습니다.
(1) VGG와 같이 fully-connected layer를 가지는 CNN 기반 모델
(2) captioning처럼 structured output에 사용되는 CNN 기반 모델
(3) reinforcement learning이나 visual question answering과 같은 multi-modal input을 이용하는 task에 사용되는 CNN 기반 모델
위 3가지 모델들에 모두 적용 가능하며, 별도의 architectural 변화나 재학습을 필요로 하지 않는다는 것이 특징입니다.
본 논문의 저자들은 고화질의 class-discriminative visualization을 만들어 내기 위해서 Grad-CAM을 이미 존재하는 fine-grained visualization과 결합한 Guided Grad-CAM을 만들었고, 이를 ResNet-based architectures를 포함한 image classification, image captioning, visual question answering (VQA) model에 적용하였습니다.
이미지 분류 모델의 맥락에서, Grad-CAM은
(a) failure mode에 대한 insight를 제공합니다. (비합리적으로 보이는 예측이 합리적인 설명을 가지고 있다는 것을 입증합니다.)
(b) ILSVRC-15 weakly-supervised localization task에 대해서 이전 method에 비해 더 좋은 성능을 냅니다.
(c) adversarial perturbation에 강건합니다.
(d) underlying model에 대해 더욱 믿음을 가질 수 있게 해 줍니다.
(e) dataset bias를 확인함으로써 model generalization를 성취하는데 도움을 줍니다.
Image captioning과 VQA에 대해서, Grad-CAM은 심지어 non-attention based model도 input image의 discriminative region의 위치를 학습할 수 있음을 보여줍니다.
저자들은 Grad-CAM을 통해 중요한 neuron을 확인할 수 있는 방법을 고안하며 이를 neuron names와 결합해 model decision에 대한 textual explanation을 제공합니다.
마지막으로, 저자들은 Grad-CAM explanation이 user가 deep network로부터의 prediction에 적절한 신뢰를 만드는 데 있어서 도움이 되는지 아닌지를 측정하고자 human study를 설계하고 수행하였고, Grad-CAM은 심지어 두 모델이 동일한 예측을 만들었을 때도 학습되지 않은 user가 성공적으로 더 강한 deep network를 포착하는데 도움을 줄 수 있다는 사실을 보입니다.
1. Introduction
Convolutional Neural Networks (CNNs)을 기반으로 하는 deep neural model은 image classification, object detection 등 다양한 computer vision task에서 훌륭한 성능을 보여줬습니다.
이러한 모델들이 좋은 성능을 가능하게 만들었지만, 이들의 각각의 직관적인 요소로의 decomposability의 부족은 이들을 해석하기 어렵게 만들었습니다.
따라서 오늘날의 지능형 시스템은 어떠한 경고나 설명 없이 실패하는 경우가 많으며, 이는 사용자가 지능형 시스템의 일관성 없는 output을 보면서 시스템이 왜 그런 의사결정을 했는지에 대해서 궁금하게 됩니다.
Interpretability matters. (해석 가능성은 중요합니다.) 지능형 시스템에 있어서 신뢰를 구축하기 위해서는 왜 그렇게 예측했는지를 설명할 능력을 가진 'transparent' model을 구축해야 합니다.
모델의 투명성과 설명할 수 있는 능력은 인공지능 진화의 3가지 다른 단계에서 유용합니다.
첫 번째, AI가 인간보다 상당히 약하고 아직 신뢰하면서 사용하기 어려운 경우 (예: visual quenstion answering), 설명과 투명성의 목표는 failure mode을 확인하는 것이며, 이에 의해 연구자들이 더욱 생산적인 연구 방향에 집중할 수 있도록 도울 수 있습니다.
두 번째, AI가 인간과 동등하고 안정적으로 사용할 수 있는 경우 (예: 충분한 데이터에 학습된 image classification), 목표는 사용자에게 신뢰와 확신을 만들어내는 것입니다.
세 번째, AI가 인간보다 상당히 강력할 때 (예: 바둑, chess), 설명의 목표는 machine teaching에 있습니다. 즉, 기계가 어떻게 더 나은 의사결정을 만드는지에 대해서 사람을 가르치는 것입니다.
(실제로 요즘에 바둑 분야에서는 알파고와 같은 강화 학습 인공지능을 가지고서 연습을 하는 것으로 알려져 있습니다.)
전형적으로 accuracy와 simplicity or interpretability 사이에는 trade-off가 있습니다.
고전적인 rule-based나 expert system은 매우 해석 가능하지만, 매우 정확하거나 강건하지는 않습니다.
각 단계가 손수 설계된 분해 가능한 piepline은 각각의 individual component가 자연스러운 직관적 설명을 가정하므로 더욱 해석 가능하지만, deep model을 사용하는 경우 더 좋은 성능을 달성하기 위해 해석 가능한 모듈을 희생하게 됩니다.
최근 도입된 deep residual networks (ResNets)는 200-layer 이상으로 깊은 네트워크를 구성하며, 이는 여러 가지 어려운 task에서 SOTA 성능을 보여주었습니다.
이러한 복잡성은 모델을 해석하기 어렵게 만듭니다.
최근에 Zhou et al. 은 discriminative regions을 식별하고자 fully-connected layer가 없는 image classification CNN에 사용되는 기법인 Class Activation Map을 제안하였습니다.
본질적으로, CAM은 모델의 작동에 대한 투명성을 높이고자 모델의 복잡성과 성능을 절충하게 됩니다.
(Fully-connected layer를 제거하므로 parameter의 수가 줄어들게 되고 이에 따라 성능도 줄어들기 때문이죠.)
그에 반해서, 본 논문의 저자들은 모델의 architecture를 바꾸지 않고 존재하는 SOTA deep model을 interpretable 하게 만들며 이를 통해 interpretability vs. accuracy trade-off를 회피합니다.
본 논문에서 제시하는 접근법은 CAM의 generalization이며, 다양한 CNN model에 적용할 수 있습니다.
무엇이 좋은 visual explanation을 만들까요?
Image classification을 생각해보겠습니다. 어떤 target category의 타당함을 보여주기 위한 모델로부터의 '좋은' visual explanation은 (a) class-discriminative 해야 하고, (즉, 이미지 내에서 category의 위치를 알아낼 수 있어야 함) (b) high-resolution이어야 합니다. (즉, fine-grained detail을 포착해야 함)
Fig. 1은 'tiger cat' class (위)와 'boxer' (개) class (아래)에 대한 수많은 visualization output을 보여주고 있습니다.
Guided Back-propagation과 Deconvolution와 같은 pixel-space gradient visualization은 high-resolution이고 이미지 내에서 fine-grained detail을 강조하지만, class-discriminative 하지는 않습니다. (Fig. 1b와 Fig. 1h가 매우 유사한 것이 그 예시가 됩니다.)
그에 반해서, CAM이나 저자들이 제안하는 방법인 Gradient-weighted Class Activation Mapping (Grad-CAM)와 같은 localization approaches는 매우 class-discriminative 합니다. ('cat'에 대한 설명은 오로지 'cat' region만 강조하며 'dog' region을 강조하지 않습니다. Fig. 1c, Fig. 1i을 통해 확인할 수 있습니다.)
두 방법론의 장점을 결합하기 위해, 저자들은 high-resolution이고 class-discriminative 한 Guided Grad-CAM visualization을 만들어 내기 위해 pixel-space gradient visualization을 Grad-CAM과 결합하는 것이 가능하다는 것을 보입니다.
그 결과로, Fig 1d와 1j에서 보이는 것처럼, 심지어 이미지가 여러 가지 가능한 concept을 포함하고 있을 때에도 관심이 있는 어떤 의사결정에 대응되는 이미지의 중요한 region을 high-resolution으로 시각화합니다.
'tiger cat'을 시각화할 때, Guided Grad-CAM은 cat region을 강조할 뿐만 아니라 고양이에 있는 줄무늬도 강조하며, 이는 고양이의 특정한 종을 예측하는 데 있어서 중요합니다.
요약하자면, 본 논문의 contribution은 다음과 같습니다.
재학습이나 architectural change를 요구하지 않고 어떠한 CNN 기반의 network에 대해서 visual explanation을 만들어내는 class-discriminative localization technique인 Grad-CAM을 소개합니다. 저자들은 localization (Sec. 4.1)와 모델에 대한 믿음 (Sec. 5.3)에 대해서 Grad-CAM을 평가하였으며, 이는 baseline보다 더 좋은 성능을 나타냅니다.
저자들은 Grad-CAM을 존재하는 최고 성능의 classification model, captioning model, VQA model에 적용하였습니다. Image classification에 대해서는, 현재 CNN의 실패에 대한 통찰력을 제공하며, 보기에는 불합리해 보이는 예측이 합리적인 설명을 가지고 있음을 보여줍니다. Captioning과 VQA에 대해서는, CNN + LSTM이 grounded image-text pair에 대해서 학습되지 않았음에도 불구하고 discriminative image region의 위치를 찾는 데 있어서 잘한다는 사실을 보여줍니다.
Dataset에서 bias를 발견함으로써 해석 가능한 Grad-CAM visualization이 failure mode를 진단하는 데 있어서 어떻게 도움이 되는지를 보여줍니다. 이는 generalization을 위해서 중요할 뿐만 아니라, 사회에서 알고리즘에 의해 점점 더 많은 의사결정이 내려지기 때문에 공정하고 편견이 없는 결과를 위해서도 중요합니다.
저자들은 Image classification과 VQA에 적용된 ResNets에 대한 Grad-CAM visualization을 제시합니다.
Grad-CAM으로부터 neuron importance를 사용하며 model decision에 대한 textual explanation을 얻습니다.
Guided Grad-CAM explanation이 class-discriminative 하고 사람이 신뢰를 만드는 데 있어서 도움을 줄 뿐만 아니라, 심지어 두 모델이 동일한 예측을 만들었을 때도 untrained users가 '약한' 모델로부터 '강한' 모델을 성공적으로 알아보는데 도움이 된다는 것을 보여주는 human study를 수행합니다.
2. Related Works
선행연구는 생략합니다.
3. Grad-CAM
수많은 이전 연구들은 CNN에서의 deeper representation이 higher-level visual construct를 포착한다고 주장해왔습니다.
더욱이, convolutional layers는 선천적으로 fully-connected layers에서 잃은 spatial information을 보유하고 있으며, 따라서 저자들은 last convolutional layer가 high-level semantics와 detailed spatial information 사이의 절충안을 가지고 있을 것이라고 기대하였습니다.
이러한 layers에 있는 neuron들은 semantic 한 class-specific information을 image내에서 찾습니다.
Grad-CAM은 CNN의 마지막 convolutional layer로 흐르는 gradient information을 사용하여 관심이 있는 특정한 의사결정을 위해 각 뉴런에 importance value를 할당하는 방법입니다.
Fig. 2에서 보이는 것처럼, width가 $u$이고 height가 $v$인 어떤 class $c$에 대한 class-discriminative localization map Grad-CAM $L^c_{Grad-CAM} \in R^{u \times v}$을 얻기 위해서, 저자들은 먼저 class $c$에 대한 점수 $y^c$ (before the softmax)에 대한 gradient를 convolutional layer의 feature map activation $A^k$에 대해서 계산합니다.
즉 이는 $\frac{\partial y^c}{\partial A^k}$로 표현할 수 있습니다.
이 gradients는 neuron importance weights $\alpha^c_k$를 얻기 위해서 width와 height dimension에 대해서 global average pooled 됩니다.
weight $\alpha^c_k$는 target class $c$에 대한 feature map $k$의 'importance'를 포착합니다.
저자들은 forward activation maps의 weighted combination을 수행하고, 다음으로 ReLU를 수행하여 다음을 얻게 됩니다.
이는 convolutional feature maps와 동일한 사이즈의 coarse heatmap의 결과를 낳게 됩니다.
저자들은 maps의 linear combination에 ReLU를 적용하였는데, 이는 저자들이 오직 관심 있는 class에 positive 영향을 주는 feature에만 관심이 있기 때문입니다.
즉, $y^c$를 증가시키기 위해서 증가되어야 할 intensity를 가지는 pixel을 말합니다.
ReLU를 적용하지 않으면, localization에서 더 나쁜 성능을 보여준다고 합니다.
$y^c$는 image classification CNN에서 만들어진 class score일 필요는 없으며, caption이나 question에 대한 answer로부터 나오는 word를 포함한 어떠한 미분 가능한 activation도 모두 적용 가능합니다.
3.1 Grad-CAM generalizes CAM
이번 section에서는 Grad-CAM과 Class Activation Mapping (CAM) 사이의 connection에 대해서 논의하고, Grad-CAM이 다양한 CNN-based architecture에 대해 CAM을 일반화한다는 것을 형식적으로 검증합니다.
끝에서 두 번째 layer가 $K$ feature maps을 만든다고 가정한다면, $A^k \in R^{u \times v}$이며, 각 element는 i, j에 의해서 indexing 됩니다.
따라서, $A^k_{i, j}$는 feature map $A^k$의 location (i, j)에 있는 activation을 의미합니다.
이러한 feature map은 Global Average Pooling (GAP)을 사용하여 공간적으로 pooling 되며 각 class $c$에 대한 score $Y^c$을 만들어내고자 선형적으로 변형됩니다.
$F^k$를 global average pooled output이라고 가정합니다.
CAM은 final score를 다음과 같이 계산합니다.
$w^c_k$는 $c^{th}$ class와 연결된 $k^{th}$ feature map의 weight를 나타냅니다. Class $c$에 대한 score ($Y^c$)의 feature map $F^k$에 대한 gradient를 다음과 같이 계산할 수 있습니다.
(4)의 $A^k_{ij}$에 대한 partial derivative를 얻으면, 이는 $\frac{\partial F^k}{\partial A^k_{ij}}$ = $1/Z$입니다. 이를 (6)에서 대체하면, 이를 얻을 수 있습니다.
(5)으로부터 $\frac{\partial Y^c}{\partial F^k}$ = $w^c_k$를 얻습니다. 따라서,
(8)의 양변을 모든 픽셀 (i, j)에 대해서 모두 더하면,
$Z$와 $w^c_k$는 (i, j)에 의존하지 않으므로, 다음과 같이 쓸 수 있습니다.
(좌변은 i와 j를 모두 더한 것이므로, 그것의 개수인 Z가 남게 됩니다.)
$Z$는 feature map에서의 pixel 수를 나타내기 때문에, 다음과 같이 양변을 $Z$로 나눠줄 수 있습니다.
normalize out 해주는 proportionality constant (1/Z)를 빼면, $w^c_k$라는 expression은 Grad-CAM에 의해서 사용되는 $\alpha^c_k$와 동일합니다.
따라서, Grad-CAM은 CAM의 엄격한 generalization입니다.
3.2 Guided Grad-CAM
Grad-CAM은 class-discriminative 하고 관련이 있는 image region의 위치를 찾아주지만, 이는 Guided Backpropagation이나 Deconvolution과 같은 pixel-space gradient visualization methods와 같이 fine-grained details를 강조하는 능력은 부족하다고 합니다.
Figure 1c를 보게 되면, Grad-CAM은 쉽게 고양이의 위치를 찾아내지만, coarse heatmap으로부터 왜 network가 이 특정한 instance를 'tiger cat'으로 예측했는지는 불명확합니다.
양쪽의 장점을 결합하고자, 저자들은 Guided Backpropagation과 Grad-CAM visualizations을 element-wise multiplication을 통해서 융합합니다.
이를 통해 얻게 되는 visualization은 high-resolution이고 class-discriminative 합니다.
3.3 Counterfactual Explanations
Grad-CAM을 약간 수정하면 네트워크가 이것의 예측을 바꾸게 만드는 지역을 강조하는 설명을 얻을 수 있게 됩니다.
그 결과로, 이러한 regions에서 나타나는 concept을 제거하는 것이 이것의 예측에 대해서 모델이 더욱 확신할 수 있게 만듭니다.
저자들은 이러한 explanation modality를 counterfactual explanations이라고 부릅니다.
구체적으로, 저자들은 class $c$에 대한 score인 $y^c$의 convolutional layer의 feature maps $A$에 대한 gradient 값을 마이너스로 만듭니다.
따라서 importance weight $\alpha^c_k$는 다음과 같은 식으로 바뀌게 됩니다.
이전의 (2)에서 보여준 것처럼, 저자들은 weights $\alpha^c_k$를 forward activation maps A의 weighted sum을 취하고, 이를 ReLU에 통과시켜 Fig. 3에서 나타나는 counterfactual explanations을 얻게 됩니다.
여기까지가 모델과 관련된 내용이며, 다음 내용부터는 실험과 관련된 내용입니다.
실험과 관련된 내용들은 간단하게만 다루겠습니다.
4. Evaluating Localization Ability of Grad-CAM
4.1 Weakly-supervised Localization
이번 section에서는 image classification 맥락에서 Grad-CAM의 localization 능력을 평가하게 됩니다.
CAM 논문에서와 동일하게, 이미지가 주어졌을 때 network는 class prediction을 하게 되며 만들어진 Grad-CAM map의 max 값의 15%를 threshold로 지정하여 이보다 큰 값들을 가지게 되는 map의 위치들을 포함할 수 있는 하나의 bounding box를 만들어냅니다.
ILSVRC-15 데이터셋에 대해서, localization error는 다음과 같습니다.
VGG16에 대한 Grad-CAM이 top-1 loalization error에서 최고 성능을 나타냈으며, CAM은 모델 구조의 변경으로 인해 re-training이 필요하고 classification error가 높아지지만, Grad-CAM은 classification performance에 있어서 악화되는 현상이 없다는 것이 장점입니다.
5. Evaluating Visualizations
이번 section에서는 human study를 수행한 결과를 나타냅니다.
5.1 Evaluating Class Discrimination
실험은 90개의 image-category pair에 대해서 4가지의 visualization (Deconvolution, Guided Backpropagation, Deconvolution Grad-CAM, Guided Grad-CAM)을 제시하고, 각 이미지에 대해서 정답이 무엇인지에 대한 평가를 받습니다.
Guided Grad-CAM을 보여줬을 때, 실험에 참가한 사람들은 케이스의 61.23%에 대해서 category를 맞췄으며, 이는 Guided Backpropagation의 44.44%와 비교했을 때 human performance를 16.79%만큼 향상한 결과입니다.
유사하게, Grad-CAM은 Deconvolution을 더욱 class-discriminative 하게 만들었으며, 53.33%에서 60.37%로 향상되었습니다.
6. Diagnosing image classification CNNs with Grad-CAM
이번 section에서는 image classification CNN의 failure mode를 분석할 때, adversarial noise의 효과를 이해할 때, dataset에서의 bias를 확인하고, 제거할 때 Grad-CAM의 사용을 검증합니다.
6.1 Analyzing failure modes for VGG-16
네트워크가 어떤 실수를 만들었는지 보기 위해서, 저자들은 먼저 network가 분류를 정확히 하지 못한 예시들을 확인하였습니다.
이러한 오분류된 케이스에 대해서, Guided Grad-CAM을 사용하여 정답 class와 예측된 class를 시각화하였습니다.
Fig. 6에서 확인할 수 있듯이, 몇몇 failure는 ImageNet classification에서 내재된 애매모호함 때문에 발생하였습니다.
즉, network가 아예 잘못된 예측을 한다기보다는, 사진이 다른 class로 오분류될 수 있을 법한 애매모호함을 가지고 있다는 것이죠.
겉보기에는 비합리적인 예시가 합리적인 설명을 가지고 있다는 것을 이를 통해 증명하였습니다.
6.2 Effect of adversarial noise on VGG-16
저자들은 ImageNet-pretrained VGG-16 model에 대해 adversarial image를 생성하여 모델이 이미지 내에서 나타나지 않은 category로 높은 확률 (>0.9999)을 assign 하고 이미지 내에 나타난 category로 낮은 확률을 assign 하도록 만듭니다.
그러고 나서, 이미지에 나타난 category에 대해 Grad-CAM visualization을 만들었습니다.
Fig. 7에서 나타난 것처럼, network는 이미지에 존재하는 category에 대해서 매우 낮은 확률로 예측하고 있으나, 그럼에도 불구하고 이것들의 위치는 정확하게 잡아내는 것을 확인할 수 있습니다.
이를 통해 Grad-CAM은 adversarial noise에 꽤 강건하다는 사실을 알 수 있습니다.
6.3 Identifying bias in dataset
이번 section에서, 저자들은 training dataset에서의 bias를 확인하고 줄이는데 Grad-CAM을 사용할 수 있다는 것을 검증합니다.
편향된 데이터셋에 학습된 모델은 현실 세계의 문제에 일반화되지 않거나, 더 나쁜 경우 편견과 고정관념을 영구화할 수 있습니다. (예를 들어 성별, 인종, 연령 등)
training dataset과 validation dataset을 image search engine을 이용해 각 class 당 가장 관련 있는 250개의 이미지를 이용해 구성하였습니다.
그러고 나서 test set은 두 클래스 간 gender의 분포를 균형 있도록 통제하였습니다.
비록 trained model은 좋은 validation accuracy를 달성하였으나, 일반화에서는 성능이 떨어졌습니다. (82% test accuracy)
모델 예측에 대한 Grad-CAM visualization (Fig. 8의 middle column의 red box region)은 모델이 간호사를 의사로부터 구별하는 데 있어서 사람의 얼굴과 머리 스타일을 보도록 학습되었음을 나타내며, 따라서 gender stereotype을 학습하였다는 것을 나타냅니다.
실제로, 모델은 여러 여성 의사를 간호사로, 남성 간호사를 의사로 오분류하였습니다.
명확하게, 이는 문제가 됩니다.
image search result는 gender-biased 되었다는 사실이 판명되었습니다. (의사 이미지의 78%가 남성이었으며, 간호사 이미지의 93%가 여성이었습니다.)
Grad-CAM visualization으로부터 얻은 이러한 직관을 이용해서, 클래스 당 이미지의 수는 유지하면서 남성 간호사와 여성 의사의 이미지를 추가함으로써 training set에서의 bias를 감소시킬 수 있습니다.
re-trained model은 더 잘 일반화할 뿐만 아니라 (90% test accuracy), 올바른 구역을 본다는 것을 알 수 있었습니다. (Fig. 8의 마지막 column)
이는 Grad-CAM이 dataset에서의 bias를 확인하고 제거하는데 도움을 줄 수 있으며, 이는 더 나은 일반화와 공정하고 윤리적인 결과를 위해서 중요합니다.
여기까지 Grad-CAM 논문을 살펴보았습니다.
더 많은 실험 내용이 궁금하신 분들은 논문을 직접 봐주시면 되겠습니다.
다양한 CNN 기반의 모델에 모두 적용할 수 있고, 또 원하는 layer에 대해서 적용할 수 있으며, failure mode을 판단하는데도 사용될 수 있고 training set의 bias를 확인하는 데 사용할 수 있는 등 기존 CAM에 비해서 굉장한 확장성을 보여주는 모델이라고 생각합니다.
paper review는 여기까지 마무리하고, 다음 글에서는 Grad-CAM을 코드로 구현한 내용들에 대해서 살펴보겠습니다.
test dataset을 가지고 torchvision.datasets.ImageFolder로 dataset 객체를 만들어준 뒤에, 이를 DataLoader에 투입시킵니다.
이때, batch_size는 1로 주어 한 개의 이미지씩 나오도록 만들어줍니다.
물론 여러 장씩 나오게 할 수도 있지만, 1개씩 나오게끔 하는 것이 전반적으로 간단해질 것 같아 이렇게 설정하였습니다.
그리고 결과를 저장해주기 위해서, saved_loc이라는 이름으로 현재 실행 시간을 폴더명으로 해서 폴더를 만들어줍니다.
마지막으로, 불러온 resnet18 모델을 GPU로 이동시킵니다.
3. CAM 만들기
본격적으로 CAM을 만들어보겠습니다.
import torch.nn.functional as F
import matplotlib.pyplot as plt
from scipy.ndimage import label
from skimage.measure import regionprops
import matplotlib
# final conv layer name
finalconv_name = 'layer4'
# inference mode
resnet18.eval()
# number of result
num_result = 3
먼저 CAM을 만드는데 필요한 library를 가지고 오고, 마지막 conv layer의 이름을 가져옵니다.
그리고 resnet18을 inference mode로 변경한 뒤, result를 몇 개 나오게 만들 것인지를 결정합니다.
feature_blobs = []
# output으로 나오는 feature를 feature_blobs에 append하도록
def hook_feature(module, input, output):
feature_blobs.append(output.cpu().data.numpy())
resnet18._modules.get(finalconv_name).register_forward_hook(hook_feature)
# get the softmax weight
params = list(resnet18.parameters())
weight_softmax = np.squeeze(params[-2].cpu().detach().numpy()) # [2, 512]
feature_blobs는 빈 형태의 list인데, 추후 여기에 feature가 들어가게 됩니다.
hook_feature라는 함수는 output으로 나오는 feature를 feature_blobs에 append 하도록 짜인 함수입니다.
그리고 resnet18._modules.get(finalconv_name).register_forward_hook(hook_feature)라는 코드를 통해서 마지막 conv layer인 'layer4'를 거쳐서 나오게 되는 feature를 feature_blobs에 저장하도록 만들어줍니다.
resnet18의 parameter들을 list로 만들어 params에 저장해주고, 여기서 마지막에서 두 번째 weight를 weight_softmax라는 변수로 저장해줍니다.
resnet18의 parameter는 layer 순서대로 저장이 되어 있는데, 가장 마지막은 fully-connected layer의 bias로 구성되어 있고 마지막에서 두 번째는 fully-connected layer의 가중치가 저장되어 있습니다.
따라서 params [-2]를 weight_softmax에 저장해주게 됩니다.
만약 제가 사용한 모델이 아니라 별도의 모델을 사용하시는 경우, 본인의 모델의 parameter들 중에서 어떤 부분이 output을 내는데 이용되는 parameter인지를 확인하신 후 사용하셔야 합니다.
# generate the class activation maps
def returnCAM(feature_conv, weight_softmax, class_idx):
size_upsample = (224, 224)
_, nc, h, w = feature_conv.shape # nc : number of channel, h: height, w: width (1, 512, 7, 7)
output_cam = []
# weight 중에서 class index에 해당하는 것만 뽑은 다음, 이를 conv feature와 곱연산
cam = weight_softmax[class_idx].dot(feature_conv.reshape((nc, h*w)))
cam = cam.reshape(h, w)
cam = cam - np.min(cam)
cam_img = cam / np.max(cam)
cam_img = np.uint8(255 * cam_img)
output_cam.append(cv2.resize(cam_img, size_upsample))
return output_cam
먼저 CAM을 만드는 데 사용되는 함수부터 소개해드리겠습니다.
returnCAM이라는 함수는 마지막 conv layer를 통과해서 나오게 되는 feature와 마지막 output을 만드는 데 사용되는 weight, 그리고 해당 예측의 class index를 input으로 받아 CAM을 만들어주는 함수입니다.
먼저 어떤 사이즈로 CAM을 만들 것인지를 결정합니다.
저희 이미지는 (224, 224)로 구성되어 있어 이를 이미지의 사이즈와 동일하게 맞춰주면 됩니다.
다음으로는 feature_conv.shape를 이용해 channel의 수와 height, width를 저장합니다.
output_cam은 빈 list로 추후 결과를 저장하는 list이며
cam은 weight_softmax [class_idx]와 feature_conv를 (nc, h*w)로 reshape 한 것을 곱 연산해줍니다.
weight_softmax의 경우 (2, 512)로 구성되는데요, 이 중에서 class index에 해당하는 값만 선택합니다.
그렇다면 shape가 (1, 512)가 되겠죠?
그러고 feature_conv는 (1, 512, 7, 7)의 shape를 가지고 있는데 이를 (512, 7*7) 형태로 바꿔주고 나서 dot product를 수행합니다.
matrix 연산은 첫 번째 matrix의 가로와 두 번째 matrix의 세로가 같아야만 연산이 되니까요. 그래서 결과는 (1, 7*7)이 됩니다.
이 결과를 (7, 7) 모양으로 다시 reshape 해주면 마지막 conv layer를 통과해서 나온 (1, 512, 7, 7)와 가로, 세로 관점에서 동일한 크기를 가지는 CAM을 만들게 되는 것이죠.
그러고 나서 이를 최솟값으로 빼주고, 최댓값으로 나눠줍니다. 이 작업은 보통 min-max scaling이라고 부르던 것 같은데 이 작업을 수행하게 되면 가장 작은 값은 0이 되고 가장 큰 값은 1이 될 겁니다.
그러고 나서 여기에 255를 곱해줘서 사실상 0부터 255의 값을 가지는 image를 만들어낸 것이라고 보시면 됩니다.
마지막으로는 이를 cv2.resize()를 활용해 이미지의 원래 사이즈인 (224, 224) 형태로 resize 해줍니다.
for i, (image, target) in enumerate(test_loader):
# 모델의 input으로 주기 위한 image는 따로 설정
image_for_model = image.clone().detach()
# Image denormalization, using mean and std that i was used.
image[0][0] *= 0.2257
image[0][1] *= 0.2209
image[0][2] *= 0.2212
image[0][0] += 0.4876
image[0][1] += 0.4544
image[0][2] += 0.4165
이제부터 본격적으로 CAM 만들기에 들어갑니다.
먼저 test_loader로부터 image와 target을 받고, 모델의 input으로 주기 위한 image를 따로 image_for_model로 지정합니다.
그리고 이전에 학습을 진행할 때와 test loader에도 동일하게 normalization을 해줬어서 normalized 되지 않은 이미지를 저장해주기 위해 이를 반대로 역정규화 해줍니다.
이렇게 하지 않으면 원본 이미지를 저장할 때 굉장히 이상한 이미지의 모습으로 보이기 때문에 정상적인 이미지 형태를 저장하고자 이 작업을 추가하였습니다.