오늘은 cs231n의 lecture 4에 대해서 정리해보겠습니다.
딥러닝에서 가장 중요한 개념 중 하나인 backpropagation에 대해서 다루고, neural network가 무엇인지 간단하게 다룹니다.
실제로 딥러닝을 코드로 돌리면 backpropagation은 컴퓨터가 모두 계산해주므로 우리가 실제로 직접 backpropagation을 짤 일은 없을 겁니다. 하지만, 가중치를 업데이트하는 가장 핵심 아이디어인 만큼, 제대로 이해할 필요가 있다고 생각합니다.

먼저, 새로운 개념인 computational graph에 대해서 얘기해보도록 하겠습니다.
computational graph는 어떤 함수를 표현할 때 graph을 이용해서 표현하는 방법입니다.
위 슬라이드를 보게 되면, 노드(node)가 존재하고 화살표가 존재하는데 노드는 연산을 의미하고, 화살표는 데이터의 흐름을 나타냅니다.
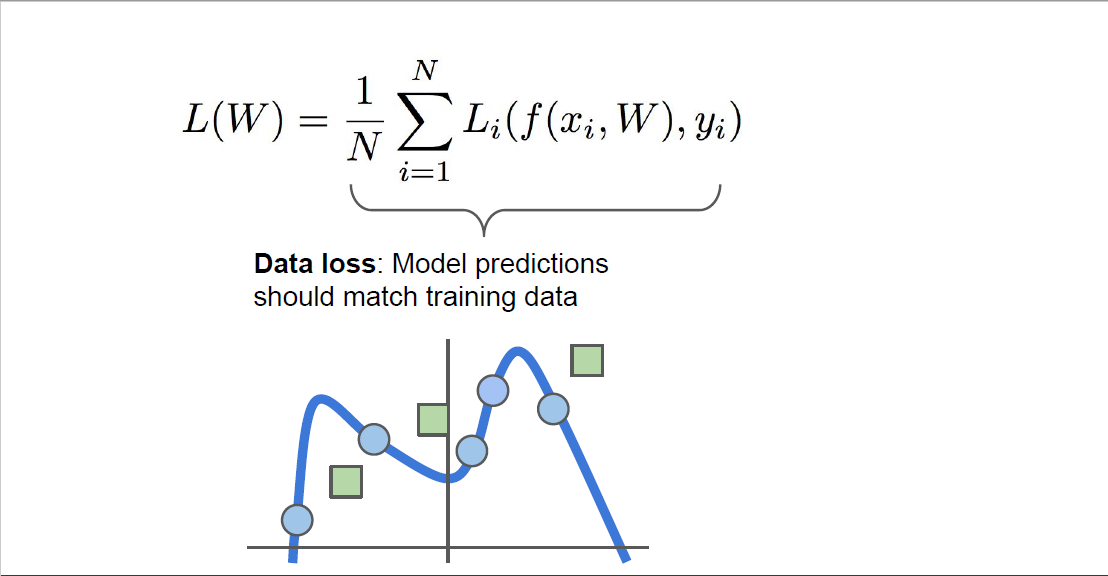
예를 들어서, 위 슬라이드에서 x와 w를 첫 번째 * 노드에 집어넣으면 W*x를 연산해주고, 여기서 나온 값이 $s$(scores)입니다. 그리고 여기에 hinge loss를 계산한 뒤, 여기에 $R(W)$를 더해서 최종 값인 L을 구하게 됩니다.
이렇게 computational graph를 이용해서 함수를 표현하게 되면, 모든 변수에 대해서 재귀적으로 gradient를 계산하는 backpropagation을 사용할 수 있게 됩니다.

첫 번째로 다뤄볼 예시는 가장 간단한 예시입니다.
사용되는 함수는 $f(x, y, z) = (x+y)z$ 라는 함수입니다. 즉, 입력으로 $x$, $y$, $z$를 받아 $(x+y) z$를 출력하는 함수입니다. 이때, $x$ = -2, $y$ = 5, $z$ = -4로 대입해 사용합니다.
슬라이드의 오른쪽 부분에는 방금 설명했던 computational graph를 이용하여 함수를 나타냈습니다.
computational graph의 위쪽에 녹색으로 표현된 숫자는 변수들의 값과 해당 노드에서의 연산 값을 나타내고 있습니다.
우리가 이번 예시에서 해볼 것은, 변수들에 대해서 함수의 gradient를 구해보는 것입니다.

다음으로는, 중간 노드들을 따로 변수로 지정하였습니다. $q = x + y$이고, $f = qz$입니다.
우리가 구하려고 하는 값들은 바로 $\frac {\partial f}{\partial x}$, $\frac {\partial f}{\partial y}$, $\frac{\partial f}{\partial z}$입니다.
각각은 함수의 input 값인 $x$, $y$, $z$가 변했을 때, 함수 $f$에 얼마나 영향을 미치는지를 나타냅니다.

자 그럼 gradient를 계산해볼까요?
backpropagation의 특징은, 가장 마지막 노드에서 시작해서 input 노드 쪽으로 계산이 된다는 점입니다.
따라서 가장 마지막 노드부터 계산을 시작해줍니다.
가장 마지막 노드는 함수 $f$ 그 자체를 나타내기 때문에, $\frac {\partial f}{\partial f}$가 되고, 값은 1로 구해집니다.
노드마다 아래쪽에 표시되는 빨간색 값은 gradient 값을 나타낸다고 생각하시면 됩니다.

다음으로 구해볼 값은 바로 $z$에 대한 gradient입니다.
수식으로는 $\frac {\partial f}{\partial z}$로 표현될 수 있으며, 해당하는 값은 파란색 박스 안에 표현되어 있습니다.
$f = qz$ 이므로, $f$를 $z$로 편미분 하게 되면 $q$가 되겠죠?
우리가 아까 $q$값을 미리 계산해서 써 두었는데, +로 표기된 노드에서 확인하실 수 있습니다. 값은 3이었죠.
따라서 $\frac{\partial f}{\partial z}$의 값은 3이 됩니다.

다음으로는 $q$의 gradient를 구해보겠습니다.
수식으로는 $\frac{\partial f}{\partial q}$로 표현될 수 있고, 이에 대한 정답도 파란색 박스에서 찾을 수 있습니다.
$f = qz$ 이므로, $f$를 $q$로 편미분 했을 때, 값은 $z$가 되죠.
$z$의 값은 -4라고 했기 때문에, $\frac{\partial f}{\partial q}$의 값은 -4가 됩니다.

다음으로는 $y$의 gradient를 구해보겠습니다.
어? 근데 $y$는 기존에 구해봤던 $q$나 $z$, $f$와는 차이가 있습니다.
바로 함수 $f$의 결괏값에 직접적으로 연결된 변수가 아니라는 점입니다.
즉, $y$는 + 연산을 거쳐 $q$를 계산한 뒤, $q$에 * 연산을 거쳐야만 $f$에 도달할 수 있습니다.
따라서, $y$의 gradient는 한 번에 구할 수 없으며, 두 번의 걸쳐 구해야 되는 것입니다.
여기서 사용되는 방법이 바로 Chain rule인데요, 아마 고등학교 수학을 배우셨다면 미분을 배울 때 많이 보셨겠죠.
쉽게 생각하면, gradient는 연산 한번 당 한 step씩 진행된다고 생각하시면 쉽습니다.
backpropagation은 끝부터 시작하기 때문에, $f$에서 $y$로 간다고 생각하면 먼저 $q$에서의 gradient를 계산해야 합니다.
따라서, 먼저 $\frac {\partial f}{\partial q}$를 계산해줍니다. 이는 아까 -4로 계산했습니다.
다음으로는, $\frac {\partial q}{\partial y}$를 계산해줍니다. 이는 빨간색 박스에서 정답을 찾을 수 있습니다. $q = x + y$ 이므로 $q$를 $x$나 $y$로 편미분 하면 1이 됩니다. 따라서 이 값은 1이 됩니다.
최종적으로, $\frac {\partial f}{\partial y}$는 -4로 계산됩니다.

다음으로 구해볼 gradient는 $x$입니다.
$x$도 마찬가지로, $f$에 도달하기 위해서 두 번의 연산이 필요합니다.
먼저 $f$에서 $q$로 진행되니, $\frac {\partial f}{\partial q}$를 계산해줍니다. 이는 -4로 계산되었습니다.
다음으로 $q$에서 $x$로 진행되니, $\frac{\partial q}{\partial x}$를 계산해줍니다. 이는 빨간 박스에서 값을 구할 수 있으며, 값은 1입니다.
따라서, 최종적으로 $\frac{\partial f}{\partial x}$는 -4입니다.

앞에서 backpropagation을 실제 예시를 통해서 계산해보았는데요.
이번에는 이를 좀 더 일반화해보겠습니다.
$x$와 $y$라고 하는 input 값이 존재하고, 이를 input으로 받아 어떤 특정한 연산인 $f$를 진행하며, 결괏값은 $z$로 내게 됩니다. 위에서 다뤘던 예시도 어떻게 보면 이러한 형태를 여러 개 붙여서 만든 케이스라고 볼 수 있습니다.

많은 노드로 구성된 케이스에 대해서 backpropagation을 진행하기 위해서는, local gradient를 계산해야 합니다.

위 슬라이드에 나와있는 gradients란, 함수의 output에 더 가까이 있는 노드에서 넘어오는 gradient를 나타낸 것입니다.

$\frac{\partial L}{\partial x}$와 $\frac{\partial L}{\partial y}$는 다음과 같이 이전에 넘어온 gradient와 local gradient의 곱으로 나타낼 수 있습니다.
backpropagation의 가장 핵심이 되는 아이디어죠.
그렇다면 첫 번째 예시에서 이 내용을 다시 한번 살펴볼까요?

위 슬라이드에서 우리가 구하려고 하는 것은 $\frac {\partial f}{\partial x}$ 였습니다.
하지만 이를 한 번에 구할 수 없기 때문에, 두 가지 단계를 거쳐서 구해야만 합니다.
먼저, "local gradient"를 계산해줍시다.
local gradient는 노드에 해당하는 연산을 진행하고 나서 나오는 output에 해당하는 변수를 현재 gradient를 구하려고 하는 변수로 편미분 해주는 것으로 기억해주시면 됩니다.
위 슬라이드에서는 local gradient를 구해야 하는 노드가 + 노드 이기 때문에, 이 노드를 진행하고 나서 나오는 output인 $q$를 현재 구하려고 하는 변수인 $x$로 편미분 해주면 됩니다.
수식으로 표현하자면 $\frac {\partial q}{\partial x}$가 되는 것이죠.
다음으로는, 이전 단계에서 넘어온 gradients를 확인해야 합니다. 이 경우에는, f에서 q로 gradient가 진행되기 때문에, 이전 단계에서 넘어온 gradients는 $\frac{\partial f}{\partial q}$로 표현할 수 있습니다.
최종적으로, $\frac{\partial f}{\partial x}$를 구하기 위해서는, 이전 단계에서 넘어온 gradients인 $\frac{\partial f}{\partial q}$와 local gradient인 $\frac{\partial q}{\partial x}$를 곱하면 되는 것입니다.
처음 보시는 분들은 이해가 안 되실 수 있습니다. 저도 이해하는데 꽤 오랜 시간이 걸렸으니까요.
앞으로 다른 예시들도 같이 보시면 더 이해가 되지 않을까 싶습니다.

두 번째로 다뤄볼 예시는 바로 이러한 케이스입니다. 아까보다 훨씬 복잡해졌죠?
아까는 더하기와 곱하기 연산만 있었지만, 이번에는 -1을 곱하는 것이나 exp를 취해주는 것도 포함되어 더 다양한 연산들에 대해 gradient를 구해볼 수 있는 케이스가 되었습니다.

밑에 4개의 식은 미분 공식을 나타낸 것입니다. 아마 모르는 사람들을 위해서 정리해두신 것 같네요.
아까처럼, 맨 마지막부터 연산을 시작합니다. 첫 번째는 $\frac {\partial f}{\partial f}$ 이므로 1입니다.

다음 다뤄볼 노드는 $x$를 input으로 했을 때, output으로 $\frac {1}{x}$가 나오게 됩니다.
따라서, 우리가 구해봐야 하는 것(local gradient)은 output을 input으로 편미분 하는 것이죠.
$\frac {1}{x}$를 $x$로 편미분 하면 $-\frac {1}{x^2}$이 됩니다.
$x$ 값이 이 지점에서는 1.37이므로, $x$에 1.37을 대입해주면 local gradient를 구할 수 있습니다.
거기에다가, 이전에 넘어온 gradient를 곱해줘야 하기 때문에, ($-\frac {1}{1.37^2}$)(1.00) = -0.53이 됩니다.

다음 다뤄볼 노드는 input으로 $x$가 들어가고, output으로 $x+1$이 나오게 됩니다.
$x+1$을 $x$로 나누면 1이기 때문에, local gradient의 값은 1이 됩니다.
이전 노드에서 넘어오는 gradient가 -0.53 이므로, (1)(-0.53) = -0.53이 해당 노드의 gradient가 됩니다.

다음 노드는 input으로 $x$가 들어가고, output으로 $e^x$가 나오게 됩니다.
따라서, $e^x$를 $x$로 편미분 해주면 되고, 편미분 한 결과는 똑같이 $e^x$가 됩니다.
해당 노드의 값이 -1이었기 때문에, local gradient는 $e^{-1}$이 되며, 이전에서 넘어오는 gradient인 -0.53과 곱해주면 -0.20로 gradient를 구할 수 있습니다.

똑같은 원리로 풀면 구할 수 있겠죠?
이전과 같이, input은 $x$, output은 $-x$임을 기억하시면 됩니다.
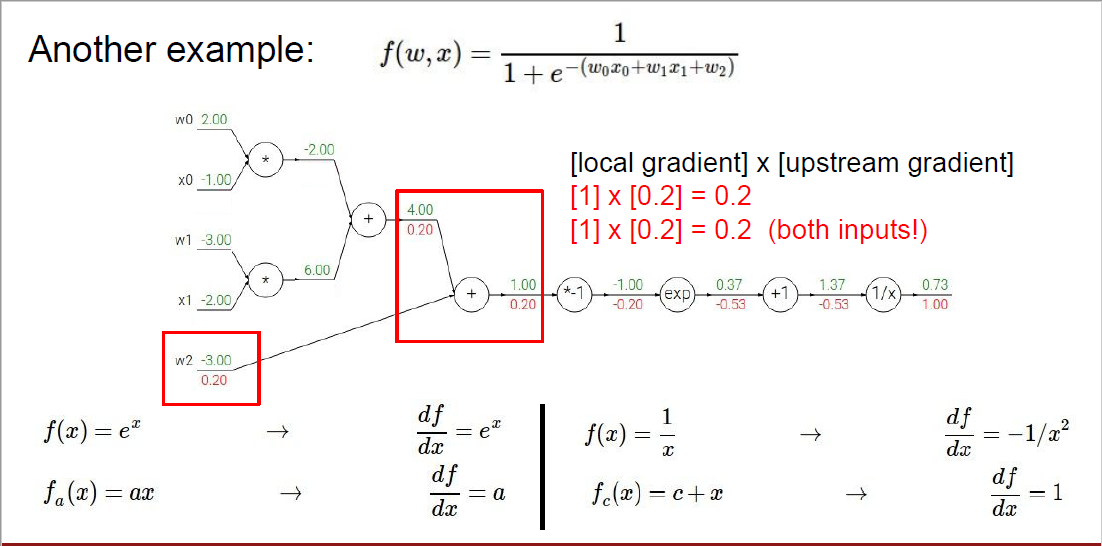
다음으로 구하는 부분은 바로 더하기 연산으로 연결된 부분입니다.
$c = a + b$라고 한다면, $c$를 $a$나 $b$로 편미분 했을 때 값은 항상 1이 되겠죠?
따라서 더하기 연산으로 연결되어 있는 경우는, local gradient는 항상 1이 됩니다.
또 이전 단계에서 넘어오는 gradient가 0.2이므로, 1 x 0.2 = 0.2로 구할 수 있습니다.

곱하기 연산이 포함된 부분도 한번 볼까요?
먼저 local gradient를 생각해 보겠습니다.
$c = a * b$라고 한다면, $c$를 $a$로 편미분 하면 $b$가 될 것이고 $c$를 $b$로 편미분 하면 $a$가 됩니다.
따라서 $w0$의 local gradient는 $x 0$의 값인 -1이 될 것이고, 이전에 넘어온 gradient가 그림에서 0.2가 되므로, 이를 곱해서 -0.2로 구할 수 있게 됩니다.
$x0$도 마찬가지로 local gradient는 $w0$의 값인 2.00이 될 것이고, 이전에 넘어온 gradient가 그림에서 0.2가 되므로, 이를 곱해서 0.4로 구할 수 있게 됩니다.

다음으로는 노드 하나하나 계산하는 것이 아니라, 여러 개의 노드를 하나의 큰 노드로 바꿀 수 있는 것을 보여주는 예시입니다.
강의자가 설명하기로는, 간결하고 간단한 그래프를 그리고 싶은지 아니면 더 디테일하게 그래프를 것인지에 따라 선택할 수 있다고 합니다. 즉 4개의 노드를 다 그릴 것인지, sigmoid 노드 1개로 표현할 것인지 선택의 문제라는 것이죠.
$\sigma(x)$를 $\frac{1}{1+e^{-x}}$인 sigmoid function으로 표현할 수 있기 때문에, *-1, exp, +1, 1/x의 4개 노드를 하나의 sigmoid라고 하는 노드로 바꿀 수 있게 됩니다.
그렇다면, input으로 $x$가 들어가서 output으로는 sigmoid값이 나오게 되는 것이죠.
sigmoid function을 $x$로 편미분 하면 $(1-\sigma(x))(\sigma(x))$가 되는데 현재 $\sigma(x)$의 값이 0.73이므로, (0.73)*(1-0.73) = 0.2로 gradient를 계산할 수 있습니다.

backpropagation을 진행할 때, 각 노드에서 나타나는 패턴을 정리해본 것입니다.
더하기 연산의 경우, 아까 언급했던 것처럼 local gradient가 항상 1이 됩니다.
따라서 이전 gradient의 값을 그대로 가지게 되는데요, 이를 distributor라고 표현했습니다.
max 연산의 경우, 그림을 참고해보시게 되면 $z$와 $w$ 중에 max를 취한 결과가 바로 $z$죠?
gradient를 계산하게 되면, $w$에는 gradient가 0이 되며, $z$에는 2로 계산된 것을 확인할 수 있습니다.
max는 여러 값 중에 가장 큰 값만 뽑아내는 연산이기 때문에, gradient를 계산할 때도 뽑아진 가장 큰 값만 gradient를 가지게 됩니다.
만약 max($x$, $y$, $z$) = $z$라면, $z$는 자신의 값을 그대로 output으로 내보내는 것이기 때문에 $z$의 local gradient는 1이 될 것입니다. 나머지 변수들은 애초에 연결된 것이 없기 때문에 local gradient가 0이 되죠.
따라서 위 슬라이드의 $z$ gradient의 경우, local gradient가 1이고, 이전에서 넘어오는 gradient 값이 2라서 gradient 값이 2로 계산되는 것을 볼 수 있습니다.
곱하기 연산의 경우, 아까 언급했던 것처럼 다른 변수의 값이 됩니다.
$c = x * y$라고 한다면 $c$를 $x$에 대해서 편미분 했을 때 $y$가 나오게 되겠죠?
이를 switcher라고 표현한 것을 볼 수 있습니다.

(실제 슬라이드에는 gradient 표기가 따로 되어있지 않아, 슬라이드를 수정하였습니다.)
다음으로 다뤄볼 내용은 한 노드가 여러 개의 노드와 연결되어 있는 경우입니다.
여러 개의 노드와 연결되면, gradient를 구할 때도 각 노드로부터 오는 gradient를 합쳐서 구하게 됩니다.
사실 반대로 생각해보면, $x$를 변화시켰을 때, $q_1$과 $q_2$에 영향을 준다는 사실을 생각해본다면 $x$의 gradient를 계산할 때 $q_1$과 $q_2$로부터 오는 gradient를 합친다는 것이 직관적으로 이해가 되실 겁니다.
이전에 gradient를 계산했던 대로, local gradient와 이전 단계에서 넘어오는 gradient를 곱해주는 개념은 그대로 적용되고, 그 대신 여러 branch로부터 gradient가 오는 것을 감안해 더해주는 것만 추가되었다고 보시면 됩니다.

지금까지는 gradient를 계산할 때, 값이 scalar일 때만 고려했습니다. 하지만 실제 데이터에는 vector 형태를 다뤄야 하죠.
따라서 vector 일 때도 다루 어보는 것입니다.
차이가 있다면, local gradient가 scalar 값이 아니라 Jacobian matrix라는 점입니다.
Jacobian matrix는 z의 각 element를 x의 각 element로 편미분 한 값으로 구성됩니다.
간단한 예시를 들자면, 만약 $x$ = [$x_1$, $x_2$, $x_3$] 이고, $z$ = [$z_1$, $z_2$, $z_3$] 라고 한다면
Jacobian matrix는 \begin{bmatrix}
\frac{\partial z_1}{\partial x_1} & \frac{\partial z_1}{\partial x_2} & \frac{\partial z_1}{\partial x_3}\\
\frac{\partial z_2}{\partial x_1} & \frac{\partial z_2}{\partial x_2} & \frac{\partial z_2}{\partial x_3}\\
\frac{\partial z_3}{\partial x_1} & \frac{\partial z_3}{\partial x_2} & \frac{\partial z_3}{\partial x_3}
\end{bmatrix}가 됩니다.

벡터화된 케이스에 대해서 한번 생각해보겠습니다.
input vector는 4096차원이고, $max(0, x)$의 연산을 거쳐 4096차원의 output vector를 만들어 냅니다.

따라서 Jacobian matrix의 사이즈는 4096 x 4096이 된다는 사실을 알 수 있습니다.
왜냐하면 Jacobian matrix는 output의 각 element를 input의 각 element로 편미분 한 값으로 구성되기 때문이죠.

실제로 우리가 연산할 때는 minibatch 단위로 진행되기 때문에, Jacobian은 실제로 더 큰 사이즈가 될 것입니다.
minibatch를 100으로 지정한다면, 100배 더 큰 matrix가 되겠죠.

그렇다면 Jacobian Matrix는 어떻게 생겼을까요?
input vector의 각 요소들은 output vector의 각 요소에만 영향을 줍니다. ($max(0, x)$ 이므로)
따라서 첫 번째 요소는 나머지 요소에 영향을 미치지 않죠. 그렇기 때문에, Jacobian matrix에서 대각선에 해당하는 값만 존재하게 됩니다. (첫 번째 요소는 나머지 2번째 ~ 4096번째 요소에 영향을 미치지 않으므로 Jacobian matrix의 값이 0이 됨)

세 번째로 다뤄볼 예시입니다. 벡터화된 경우에 어떤 식으로 계산되는지 살펴보겠습니다.

$x$와 $W$는 녹색으로 표시된 것처럼 다음과 같이 나타나고, 이들을 곱한 값을 $q$, 그리고 L2 distance를 사용해서 얻은 결괏값은 $f(q)$로 표기할 수 있습니다.
계산 자체는 단순하니 행렬 계산에 대한 설명은 생략하도록 하겠습니다.

이전에 했던 것과 마찬가지로 맨 마지막 노드부터 시작합니다. 가장 처음 노드는 항상 1로 시작하는 거 기억하시죠?

L2 distance의 경우, $q$를 제곱한 것과 동일하기 때문에 이를 $q$로 편미분 해주면 $2q_i$가 됩니다.
따라서, $\frac{\partial f}{\partial q}$는
\begin{bmatrix}
0.44 \\
0.52
\end{bmatrix} 로 표현할 수 있습니다.

언뜻 봤을 때 굉장히 복잡한 식이죠. 하나하나 살펴보겠습니다.
이번에 우리가 구해볼 것은 $\frac{\partial q}{\partial W}$인데요.
$\frac{\partial q_k}{\partial W_{i, j}}$ = $1_{k=i}x_j$로 표현되어 있습니다.
여기서 $1_{k=i}$는 indicator variable인데요. k와 i가 동일할 때는 1이고 그렇지 않으면 0을 나타냅니다.
이게 왜 이런 식으로 나타나는지는 $W \cdot x$를 생각해보시면 이해할 수 있습니다.
$q_1$에 해당하는 값은 $W_{11} \times x_1 + W_{12} \times x_2$로 구하게 됩니다. 즉, $k$와 $i$가 같을 때만 $W$의 성분이 $q$에게 영향을 줄 수 있다는 것입니다. 따라서 이렇게 indicator variable이 생겨난 것입니다.
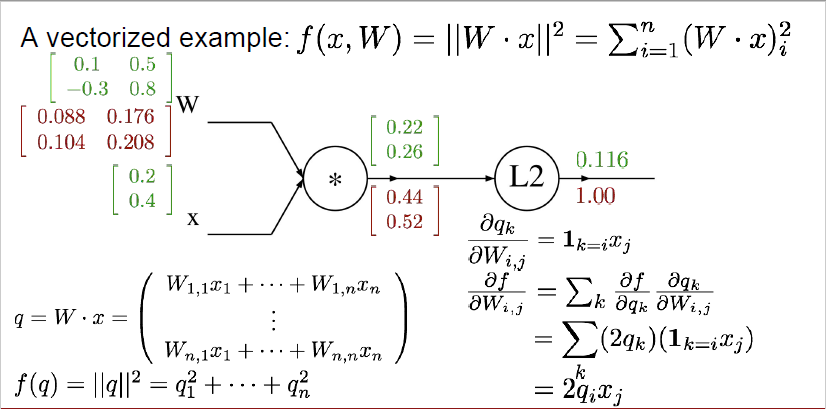
실제 값을 한번 계산해보겠습니다.
$\frac{\partial f}{\partial W_{11}}$ = $\frac{\partial f}{\partial q_1}$ $\frac{\partial q_1}{\partial w_{11}}$로 계산될 수 있습니다. 앞 부분은 $2q_1$이 되므로, 0.44가 될 것이며, 뒷부분은 $x_1$가 되므로 0.2가 되어 실제 값은 0.088입니다.
$\frac{\partial f}{\partial W_{12}}$ = $\frac{\partial f}{\partial q_1}$ $\frac{\partial q_1}{\partial w_{12}}$로 계산될 수 있습니다. 앞 부분은 $2q_1$이 되므로, 0.44가 될 것이며, 뒷 부분은 $x_2$가 되므로 0.4가 되어 실제 값은 0.176입니다.
$\frac{\partial f}{\partial W_{21}}$ = $\frac{\partial f}{\partial q_2}$ $\frac{\partial q_2}{\partial w_{21}}$로 계산될 수 있습니다. 앞 부분은 $2q_2$이 되므로, 0.52가 될 것이며, 뒷 부분은 $x_1$가 되므로 0.2가 되어 실제 값은 0.104입니다.
$\frac{\partial f}{\partial W_{22}}$ = $\frac{\partial f}{\partial q_2}$ $\frac{\partial q_2}{\partial w_{22}}$로 계산될 수 있습니다. 앞 부분은 $2q_2$이 되므로, 0.52가 될 것이며, 뒷 부분은 $x_2$가 되므로 0.4가 되어 실제 값은 0.208입니다.

$\frac{\partial f}{\partial W}$ 는 vectorized term으로 쓰자면 $2q \cdot x^T$로 표현될 수 있습니다.
이는 정답인 $\begin{bmatrix}
0.088 & 0.176\\
0.104 & 0.208
\end{bmatrix}$이 되려면
$\begin{bmatrix}
0.44\\
0.52
\end{bmatrix}$와 $\begin{bmatrix}
0.2 & 0.4
\end{bmatrix}$를 곱해야 나오기 때문입니다.
그리고 항상 체크해봐야 할 것은 변수의 shape와 gradient의 shape가 항상 같아야 한다는 것입니다.

다음으로는 $\frac{\partial f}{\partial x}$에 대해서 구해보도록 하겠습니다.
x의 local gradient인 $\frac{\partial q_k}{\partial x_i}$는 $W_{k, i}$로 표현되는데요, 이 또한 $q = W \cdot x$를 생각해보면 알 수 있습니다.
$W_{11}x_1 + W_{12}x_2 = q_1$이고, $W_{21}x_1 + W_{22}x_2 = q_2$이므로,
$\frac{\partial q_1}{\partial x_1} = W_{11}$가 됩니다.
또한, $\frac{\partial q_1}{\partial x_2} = W_{12}$, $\frac{\partial q_2}{\partial x_1} = W_{21}$, $\frac{\partial q_2}{\partial x_2} = W_{22}$이므로 $\frac{\partial q_k}{\partial x_i}$는 $W_{k, i}$가 되는 것을 알 수 있습니다.
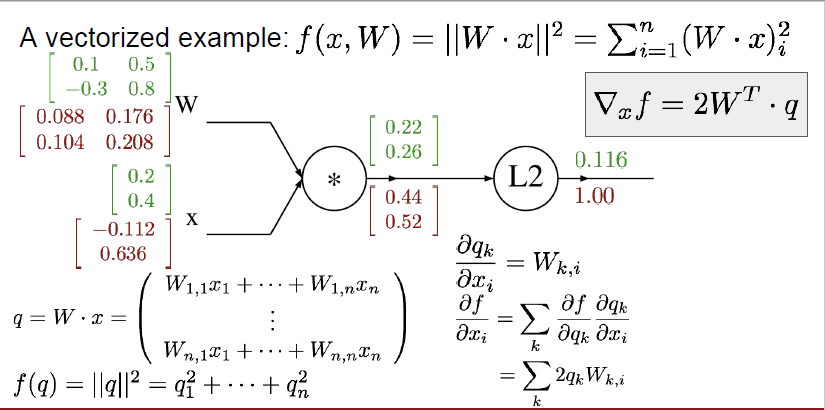
$\frac{\partial f}{\partial x}$를 실제로 구해보자면,
$\frac{\partial f}{\partial x_1} = \frac{\partial f}{\partial q_1} \frac{\partial q_1}{\partial x_1} + \frac{\partial f}{\partial q_2} \frac{\partial q_2}{\partial x_1}$가 될 것이며,
0.44 * 0.1 + 0.52 * -0.3 = -0.112가 됩니다.
$\frac{\partial f}{\partial x_2} = \frac{\partial f}{\partial q_1} \frac{\partial q_1}{\partial x_2} + \frac{\partial f}{\partial q_2} \frac{\partial q_2}{\partial x_2}$가 될 것이며,
0.44 * 0.5 + 0.52 * 0.8 = 0.636이 됩니다.
이를 vectorized term으로 표현하면, $\frac{\partial f}{\partial x} = 2W^T \cdot q$가 됩니다.

실제 Modularized implementation을 한다고 하면, 다음과 같은 코드로 진행됩니다.
먼저 forward pass를 진행합니다. 이를 통해서 각 node의 output을 계산해줍니다.
그러고 나서 backward pass를 진행합니다. 이때, 계산하는 node의 순서는 역순으로 진행하게 됩니다.
이를 통해서 gradient를 계산합니다.

다음과 같이 $x$, $y$를 input으로 받고 $z$를 output으로 할 때 다음과 같은 코드를 만들어볼 수 있습니다.
먼저 forward에서는, $x$, $y$를 input으로 받습니다.
그리고 이 둘을 곱해서 $z$라는 변수로 저장합니다.
Gradient를 계산할 때, $x$, $y$값들이 필요하기 때문에 self.x와 self.y로 저장해줘야 합니다.
그러고 나서 마지막으로는 output인 $z$를 return 해줍니다.
backward에서는 dz를 input으로 받는데, 이는 $\frac{\partial L}{\partial z}$를 의미합니다. 즉 이전 단계에서 넘어오는 gradient를 나타낸 것이죠.
dx는 self.y * dz로 표현되는데, 이는 x 입장에서 local gradient가($\frac{\partial z}{\partial x}$) y이므로 self.y * dz는 local gradient * 넘어오는 gradient(dz)을 표현한 것입니다.
dy도 마찬가지로 이해할 수 있습니다.
여기까지 backpropagation에 대한 설명이었고, 다음으로는 Neural Network에 대해서 정리해보겠습니다.

이전에는 linear score function을 이용하여 score를 얻을 수 있었습니다. 즉, $f = Wx$로 구할 수 있었죠.
이제는 layer를 하나 더 쌓아 2-layer Neural Network를 만들어보는 것입니다.
3072차원의 x에 $W_1$이라는 matrix를 곱해 100차원의 h를 만들고, 여기에 $max(0, W_1x)$를 취한 뒤, $W_2$라는 matrix를 곱해서 최종 10개 class에 대한 score를 내는 neural network입니다.
강의자가 설명하기를, Neural Network는 class of function으로 함수들을 서로의 끝에 쌓은 것이라고 이해하면 된다고 합니다.

우리가 처음 lecture 2에서 얘기했던 내용을 기억하시나요?
linear classifier에서 사용되는 weight matrix의 각 row가 class를 분류하기 위해 input의 어떤 부분을 살펴봐야 하는지에 대한 정보를 담은 template이라고 얘기했었습니다.
하지만, linear classifier에서의 한계점은 이러한 template을 class마다 단 한 개씩만 가질 수 있다는 점이었습니다. 따라서 class 내에서 다양한 형태를 가진다면(예를 들어 왼쪽을 향한 horse가 있고 오른쪽을 향한 horse가 있을 때), 예측력이 크게 감소하게 됩니다.
이러한 단점을 보완할 수 있는 게 바로 Neural Network입니다.
그렇다면 이러한 2-layer Neural Network에서는 어떠한 해석을 해볼 수 있을까요?
먼저 위 슬라이드의 예시는, 3072차원의 이미지를 input으로 받고, 10개의 class로 분류하는 예시입니다.
$x$는 [3072 x 1]의 shape를 가지고 있으며, $W1$은 [100 x 3072]의 shape를 가집니다.
이를 통해서 $W1x$ = [100 x 3072] x [3072 x 1] = [100 x 1]의 결과를 나타내겠죠.
$W1$에서 현재 100개의 row가 존재하는데, 각각의 row가 바로 template이 됩니다.
class의 수가 10개임을 감안하면, class의 수 보다 더 많은 template이 존재한다는 사실을 알 수 있습니다.
이를 통해 더 다양한 형태의 template을 학습할 수 있고 같은 class를 나타내는 이미지의 형태가 다르더라도 학습할 수 있게 됩니다.
우리가 구한 $W1x$에 $max(0, W1x)$를 적용하여 최종적으로 구한 결과가 바로 $h$가 됩니다.
다음으로는 $h$에 $W2$를 곱하게 될 텐데요, $h$는 [100 x 1]의 shape를 가지며 $W2$는 [10 x 100]의 shape를 가집니다.
$W2h$ = [10 x 100] x [100 x 1] = [10 x 1]의 결과를 나타내며, 이는 분류해야 하는 class들에 대한 각 class score를 나타냅니다.
$W2$를 살펴보자면, 각 class score를 구할 때 $h$의 요소들과의 가중치 합을 하게 됩니다.
예를 들면, $w1x1 + w2x2 + w3x3 + ..... w100x100$와 같은 방식이 되는 것이죠.
따라서, $W2$의 역할은 다양한 template들에 대해서 가중치 합을 해주는 것입니다. 이를 통해 다양한 templete의 점수들을 반영해서 class score를 더 잘 예측할 수 있게 됩니다.

실제로 2-layer Neural Network의 학습을 실행시키는데 20줄 정도면 가능하다는 것을 보여주고 있습니다.

다음으로는, 신경망을 실제 뇌에 있는 뉴런과의 유사함을 통해서 설명해주는 슬라이드입니다.
뉴런의 경우, 붙어있는 다른 뉴런으로부터 자극을 받게 되고(dendrite: 수상돌기) 이 자극들을 합쳐줍니다.(cell body)
그러고 나서 cell body로부터 다른 뉴런에게 자극을 보낼지, 아닐지, 혹은 자극의 정도를 더 높이거나 낮출지를 결정해서 자극을 보내는 것으로 결정된다면 axon을 거쳐 다른 뉴런으로 자극을 전달해주는 구조를 가지고 있습니다.
오른쪽 아래의 그림을 보게 되면, 우리가 사용하게 되는 신경망의 그림입니다.
dendrite를 통해서 다른 뉴런으로부터의 자극을 받아오게 되고, 이를 cell body에서 합칩니다.
실제 신경망에서는 $w_ix_i + b$ 형태로 계산을 하게 되죠.
이 값에 대해서 activation function을 거치고, 이 값을 다음 layer로 전달합니다.
강의자가 얘기하기로는, 다른 뉴런에게 자극을 보낼지, 아닐지를 결정하는 게 neural network에서의 activation function과 같으며, 실제 뉴런과 가장 비슷한 기능을 수행하는 것은 바로 ReLU라고 합니다.

하지만, 실제 뉴런 하고는 차이가 많이 존재하기 때문에 이러한 비유를 사용하는 것은 주의해야 한다고 말합니다.

neural network에서 주요하게 사용되는 activation function은 다음과 같습니다.
경험상 Sigmoid, tanh, ReLU 정도를 많이 사용하게 되는 것 같습니다.

일반적인 구조는 다음과 같습니다.
input layer에서 hidden layer를 거쳐 output layer로 연산이 진행됩니다.
보통 hidden layer와 output layer는 fully-connected layer로 구성됩니다.

다음과 같은 neural network의 예시를 살펴볼 수 있습니다.
activation function은 sigmoid를 사용하고, $x$는 [3x1] 형태로 input vector를 만들어줍니다.
hidden layer 1을 h1로 변수를 지정하고, [4x3]의 크기를 가진 $W1$을 이용해서 연산한 뒤, b1을 더해주고 여기에 activation function을 통과시켜 hidden layer 1을 구하게 됩니다.
hidden layer 2는 hidden layer 1와 마찬가지로 계산해줍니다.
마지막으로 output layer는 하나의 값을 가지므로, [1x4]의 크기를 가진 $W3$를 곱해서 output layer를 계산합니다.
여기까지 lecture 4의 모든 내용들을 정리해보았습니다.
아무래도 슬라이드가 많다 보니, 글이 굉장히 많이 길어졌네요.
이번에도 lecture 4를 정리할 수 있는 Quiz를 만들어보았습니다.
cs231n lecture 4 Quiz
Q1.

다음 연산에서, 각 노드들의 gradient($\frac{\partial f}{\partial x}$, $\frac{\partial f}{\partial y}$, $\frac{\partial f}{\partial z}$, $\frac{\partial f}{\partial q}$)를 구하세요.
Q2.

다음 연산에서 각 노드들의 gradient를 구하세요.
Q3.

다음 연산에서 각 노드들의 gradient를 구하세요.
Q4.

2-layer Neural Network에서 $W1$, $h$, $W2$에 대해서 template matching 관점에서 설명하고, 기존 linear classifier와의 차이점을 설명하세요.
'딥러닝 & 머신러닝 > cs231n' 카테고리의 다른 글
| cs231n - lecture 3: Loss Functions and Optimization (0) | 2020.08.17 |
|---|---|
| cs231n - lecture 2: Image Classification pipeline (0) | 2020.08.15 |