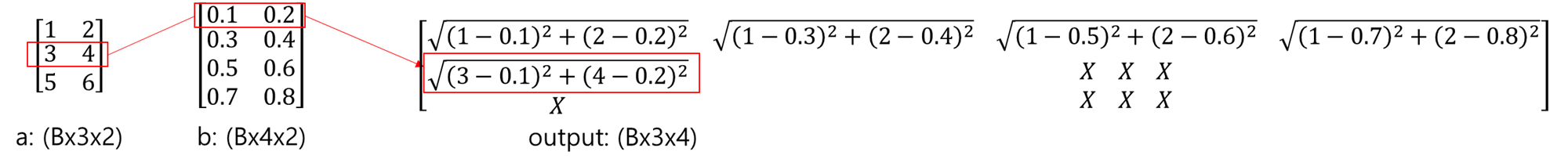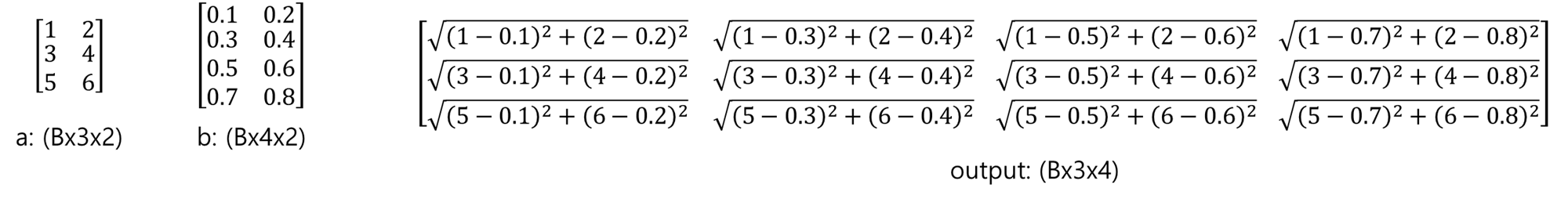cv2.error:OpenCV(3.4.2) /tmp/build/80754af9/opencv-suite_1535558553474/work/modules/core/src/arithm.cpp:223:error:(-209:sizes of input arguments do not match) The operation is neither 'array op array' (where arrays have the same size and type), nor 'array op scalar' nor 'scalar op array' in function 'binary_op'
Python의 OpenCV(cv2)에서 cv2.bitwise_and()를 사용할 때 발생했던 에러입니다.
해당 오류가 발생하는 이유는 굉장히 다양해서, 해당 에러에 대한 해결방안을 적은 블로그 글에서 조차 다양한 해결방안을 제시하고 있습니다.
해당 에러에서의 핵심은 'where arrays have the same size and type'이라고 보여지며, 말 그대로 opencv 연산을 하고자 하는 array의 size와 type이 같아야 한다는 점입니다.
제 케이스에서는 size가 같았으나 에러가 나서, 변수의 .dtype을 찍어보니 하나는 float32였고, 다른 하나는 float64이였습니다.
이에 대응하고자 float64인 이미지를 .astype(np.float32)로 처리하여 float32로 맞춰주었더니 해결되었습니다.
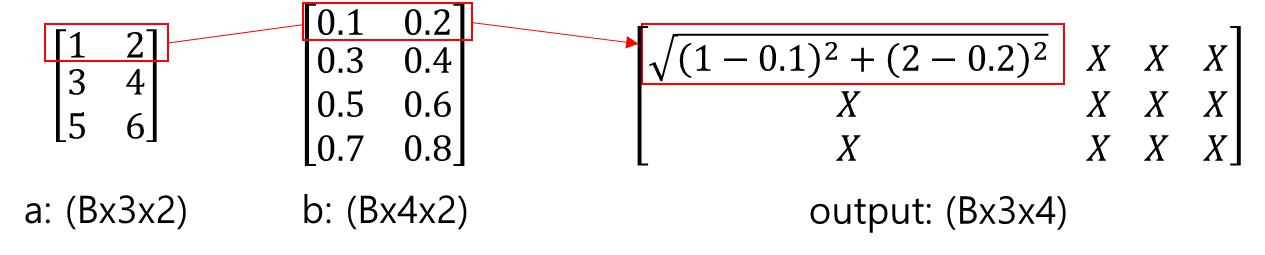
굳이 4차원으로 만드는 이유는, pytorch에서는 기본적으로 4차원 input만을 지원하기 때문입니다.
따라서, 실제로 값이 있는 것은 1부터 6까지로 해서 2 x 3 형태이지만, shape를 맞추기 위해 4차원으로 구성되었다고 보시면 될 것 같습니다.
# sample model. It has nn.ConvTranspose2d(1, 3, 4, 1, 0, bias = False)
# First parameter = Channels of input (=1)
# Second parameter = Channels of output (=3)
# Third parameter = Kernel size (=4)
# Fourth parameter = stride (=1)
# fifth parameter = padding (=0)
class sample(nn.Module):
def __init__(self):
super(sample, self).__init__()
self.main = nn.ConvTranspose2d(1, 3, 4, 1, 0, bias = False)
def forward(self, input):
return self.main(input)
다음으로는 우리가 오늘 살펴보려고 하는 메인인 nn.ConvTranspose2d를 가지고 있는 모델을 하나 만들어줍니다.
위에 주석에 달려있듯이, 첫 번째 파라미터는 input의 채널수이고 두 번째 파라미터는 output의 채널 수이며
세 번째 파라미터는 kernel size, 네 번째 파라미터는 stride, 다섯 번째 파라미터는 padding입니다.
계산을 조금 더 간단하게 하기 위해 bias= False로 놓고 실험해보겠습니다.
별도의 신경망 연산이 필요 없으므로, 매우 간단하게 layer 딱 1개만 있는 모델을 만들었습니다.
Model = sample()
# Print model's original parameters.
for name, param in Model.state_dict().items():
print("name: ", name)
print("Param: ", param)
print("Param shape: ", param.shape)
만들어진 모델의 기본 weight를 살펴보겠습니다.
pytorch가 기본적으로 지원하는 초기화 방법에 따라, weight 값이 결정된 것을 확인할 수 있습니다.
그리고 shape는 [1, 3, 4, 4]를 가지게 됩니다.
이는 kernel size를 4로 지정했기 때문에, filter의 사이즈가 4x4 형태가 되어서 그렇고 output의 channel을 3으로 지정하였으므로 결괏값이 3개의 채널로 나와야 해서 3이 생겼다고 보시면 되겠습니다.
쉽게 해당 convolution 필터를 가로가 4, 세로가 3, 높이가 4인 직육면체로 생각하시면 편합니다.
그림으로 표현해보자면 다음과 같은 것이죠.
다음으로는 결과를 조금 더 쉽게 보기 위해서, model의 파라미터를 manually 하게 바꿔보겠습니다.
지금은 weight가 소수점으로 되어 있고 매우 복잡하기 때문에, 결과를 직관적으로 이해해볼 수 있기 위한 작업입니다.
# I makes 48 values from 0.1 to 4.8 and make (1, 3, 4, 4) shape
np_sam = np.linspace(0.1, 4.8, num = 48)
np_sam_torch = torch.Tensor(np_sam)
sam_tor = np_sam_torch.view(1, 3, 4, 4)
# Modify model's parameters using 4 for loops.
with torch.no_grad():
batch, channel, width, height = Model.main.weight.shape
for b in range(batch):
for c in range(channel):
for w in range(width):
for h in range(height):
Model.main.weight[b][c][w][h] = sam_tor[b][c][w][h]
# Check parameter modification.
print("Model weight: ", Model.main.weight)
먼저, np_sam이라는 변수로 np.linspace를 이용해 0.1부터 4.8까지 48개의 값을 만들어줍니다. 이렇게 하면 0.1, 0.2, 0.3 .... 4.8까지 0.1을 간격으로 하는 숫자 48개를 만들 수 있습니다.
그리고 이를 torch.Tensor로 바꿔주고, shape를 맞추기 위해 (1, 3, 4, 4)의 형태로 맞춰줍니다.
다음으로는 model의 파라미터를 수동으로 바꿔주는 코드입니다.
먼저 batch, channel, width, height라는 변수로 model의 weight의 shape를 받습니다.
그리고 이를 4중 for문을 이용해서 바꿔줍니다.
Model.main.weight[b][c][w][h]의 값을 해당하는 인덱스와 동일한 sam_tor의 위치의 값으로 바꾸는 것이죠.
물론 일반적으로 computational cost 때문에 4중 for문을 사용하는 것은 비효율적이긴 하지만, 어쨌든 이번 상황에서는 각 차원별로 값이 작기 때문에 연산 자체가 오래 걸리진 않아 이렇게 코드를 짜보았습니다.
그리고 마지막으로는 model의 weight들을 print 해봅니다. 실제로 우리가 원하는 대로 잘 바뀌었는지 봐야겠죠.
역시나 원하는 대로 잘 바뀌었네요.
이렇게 값들이 simple해야 우리가 결과를 찍었을 때 해석도 쉬울 것입니다.
이것도 아까와 마찬가지로 shape가 (1, 3, 4, 4)가 될 텐데요, 이 또한 직육면체 형태로 이해해 볼 수 있습니다.
모든 원소의 값이 다 보이시도록 최대한 길게 그렸는데요. 이처럼 가로가 4, 세로가 3, 높이가 4를 만족하는 직육면체를 생각하시면 됩니다.
result = Model(test_input)
print("Result shape: ", result.shape)
print("Result: ", result)
다음으로는, 아까 만들어뒀던 (1, 1, 2, 3) 짜리 input을 위에서 보여드린 weight을 이용해서 nn.ConvTranspose2d를 사용해 연산한 결과를 출력합니다.
결과가 어떻게 나오는지 보겠습니다.
뭔가 어떤 결과가 나왔는데, 이것만 봐서는 아직 어떤 식으로 연산이 이루어지는지 알 수 없겠죠?
그래서 제가 하나하나 한번 뜯어서 분석해보았습니다.
실제 구동 방법 분석
이해를 조금 쉽게 하기 위해서, 파라미터와 결과 모두 channel을 1차원으로 가정하고 살펴보겠습니다.
먼저, 우리의 input은 다음과 같은 2 x 3 형태의 tensor가 됩니다.
이를 우리가 설정한 parameter를 이용해서 단순히 곱해줍니다.
따라서 다음과 같은 결과를 볼 수 있습니다.
다음으로는 다른 input 요소들도 어떻게 계산되는지 보겠습니다.
자 그러면 input 1부터 6까지 연산을 완료했다면, 결과가 총 6개가 나오게 되겠죠?
나온 6개의 결과를 element-wise addition을 통해서 최종 결과를 뽑아냅니다.
이것이 아까 프로그램을 돌려서 나온 결과와 일치함을 확인할 수 있습니다.
따라서, nn.ConvTranspose2d의 연산 과정을 다음과 같이 정리해볼 수 있습니다.
1. nn.ConvTranspose2d를 만들 때 input값의 channel 수와 설정한 output channel 수, kernel size를 고려하여 weight를 만들어낸다.
우리의 경우에는 output channel을 3으로 지정하였고, kernel size를 4로 지정하였으므로
weight의 크기가 (1, 3, 4, 4)가 됩니다.
만약에 input의 channel 수가 3이고, output channel 수가 7이며 kernel size가 4였다면
weight의 크기가 (3, 7, 4, 4)가 될 것입니다.
즉, weight의 크기는 (input channel, output channel, kernel size, kernel size)가 됩니다.
2. input의 각 element 별로 weight와 곱해줍니다. 만약 stride가 1보다 크다면, 그 값만큼 이동하면서 만들어줍니다.
위에서의 예시는 stride 1인 경우를 봤었죠. input의 각 element 별로 weight와 곱해준 결과를 stride 1로 이동하면서 만들어냈습니다.
3. 나온 모든 결괏값을 element-wise 하게 더해서 최종 결과를 냅니다.
stride가 kernel size보다 작게 되면 서로 겹치는 부분들이 존재합니다. 그럴 때는 단순히 element-wise하게 더해서 결과를 내주면 됩니다.
마지막으로, batch size가 1보다 클 때의 결과도 한번 정리해보면서 마무리 짓겠습니다.
만약 input이 (4, 3, 4, 4)의 사이즈를 가지고 있고, 모델이 nn.ConvTranspose2d(3, 7, 4, 1, 0, biase = False)인 layer를 가지고 있다고 가정한다면 어떻게 될까요?
받으려고 하는 데이터셋 파일이 .mat(매트랩) 형식으로 되어 있어서, 이를 scipy.io.loadmat을 이용해서 받았다.
(아래에 stackoverflow 출처를 올리겠지만, 질문을 올리신 분과 정확히 똑같은 상황에 처해있었다.)
받은 파일은 dictionary 형식이였고... bounding box 좌표가 들어있는 key를 찾아서 출력해보았더니
사이즈가 (70, ) 였다. 그래서 이걸 보고 아 ~ 70장 사진에 대한 bbox 좌표인가 보다 하고 [0]을 출력해보았다.
처음 봤을때는 뭔가 숫자가 엄청 많아서 이게 뭐지? 하고 .shape로 찍어봤는데 출력 값이 () 이였다.
분명 데이터 값이 저렇게 많은데 shape를 찍었을 때 ()으로 나오는 것을 보니 심상치 않았다.
그래서 이게 뭐지???? 하고 type()으로 출력해보았더니 결과값이 <class 'numpy.void'> 이였다.
numpy.ndarray나 많이 봤지, void는 처음이라....... 많이 당황했다.
처음에는 이름만 보고 데이터가 비어있다는 의미인가? 했는데 비어있다면 실제로 데이터 값이 없어야 하니 그건 또 말이 안 되는 것 같았다.
따라서 numpy.void가 무엇이고, 이를 어떻게 활용할 수 있는지에 대해서 알아볼 필요성이 생겨 검색을 하다보니 적합한 글을 찾아 이를 정리해보려고 한다.
What is numpy.void?
numpy documentation에 따르면(http://docs.scipy.org/doc/numpy/reference/arrays.dtypes.html), numpy.void type은 flexible data type으로 정의된다. 기본적으로, numpy.void type은 변수와 관련해서 이미 정의된 type이 없는 데이터 타입이다. 이미 정의된 type이란, float, uint8, bool, string 등등의 data type을 말하는 것이다.
void는 더 포괄적이고 융통성 있는 type을 수용하며, void는 이미 정의된 데이터 타입 중 하나로 반드시 결정되지 않는 데이터 타입을 위해 존재한다. 이러한 상황은 대개 struct에서 loading 할 때 마주하게 되는데, 각 element가 다양한 field와 관련 있는 다양한 데이터 타입을 가지고 있는 경우이다. 각 structure element는 다른 데이터 타입의 조합을 가질 수 있으며, 이러한 structure element를 가진 instance를 나타내기 위해 numpy.void를 사용한다.
documentation에 따르면, 우리가 다른 데이터 타입들에 적용하던 operation을 동일하게 적용할 수 있다.
In the context of deep learning, what is an ablation study?
(딥러닝에서, ablation study는 무엇인가?)
의학이나 심리학 연구에서, Ablation Study는 장기, 조직, 혹은 살아있는 유기체의 어떤 부분을 수술적인 제거 후에 이것이 없을때 해당 유기체의 행동을 관찰하는 것을 통해서 장기, 조직, 혹은 살아있는 유기체의 어떤 부분의 역할이나 기능을 실험해보는 방법을 말한다. 이 방법은, experimental ablation이라고도 알려져 있는데, 프랑스의 생리학자 Maria Jean Pierre Flourens이 19세기 초에 개척했다. Flourens은 동물들에게 뇌 제거 수술을 시행하여 신경계의 다른 부분을 제거하고 그들의 행동에 미치는 영향을 관찰했다. 이러한 방법은 다양한 학문에서 사용되어왔으며, 의학이나 심리학, 신경과학의 연구에서 가장 두드러지게 사용되었다.
Machine learning에서, ablation study는 "machine learning system의 building blocks을 제거해서 전체 성능에 미치는 효과에 대한 insight를 얻기 위한 과학적 실험"으로 정의할 수 있다. Dataset의 feature나 model components가 building blocks에 해당한다. (따라서 ablation study라는 용어를 feature ablation이나 model ablation 이라는 용어로도 사용할 수 있다.) 하지만 어떠한 design choice나 system의 module도 ablation study에 포함될 수 있다.
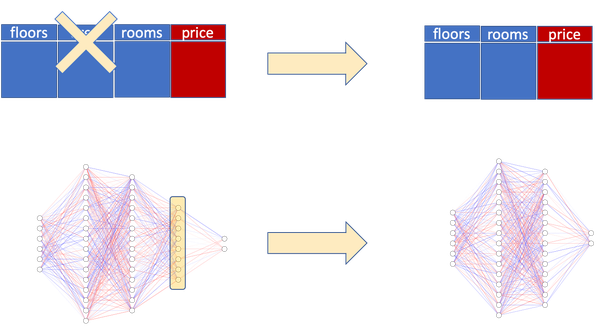
그림 1. Illustration of ablation study
우리는 ablation study가 여러 시도로 구성된 실험이라고 생각할 수 있다. 예를 들어, 각 model ablation trial은 한개 혹은 그 이상의 components가 제거된 모델을 학습하는 것을 포함한다. 유사하게, feature ablation trial은 dataset feature 들의 다른 집합을 사용하여 모델을 학습하는 것을 포함하며, 결과를 확인한다.
그림 1에서, 위에 나타난 표 그림은 feature ablation trial을 나타내고 있으며, 아래 나타난 layer 그림은 layer ablation trial을 나타낸다. 예를 들어, layer ablation trial에서, 우리는 base model의 마지막 hidden layer를 제거하고, 결과 모델을 학습시키고, 이것의 성능을 확인하게 된다.