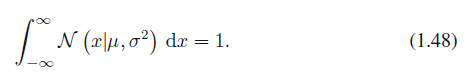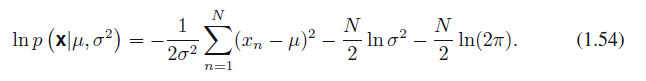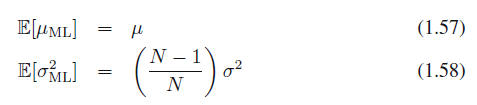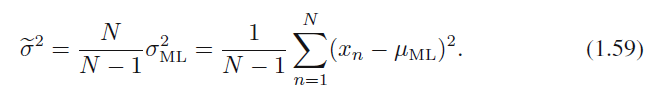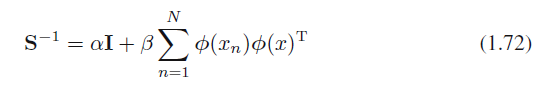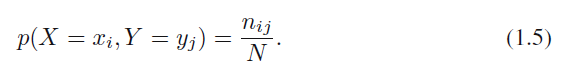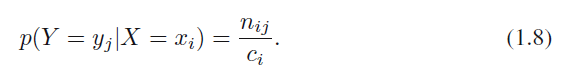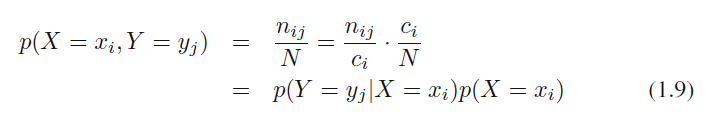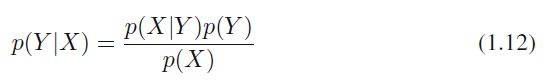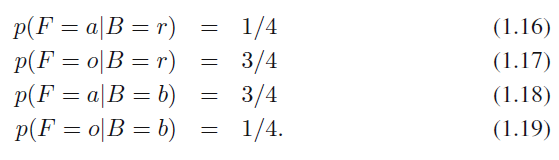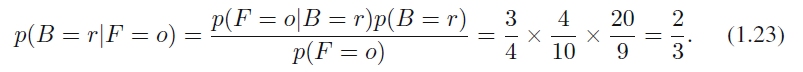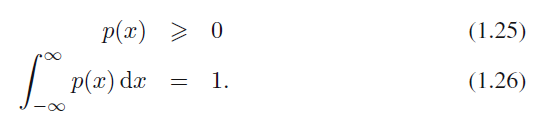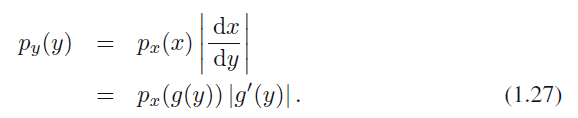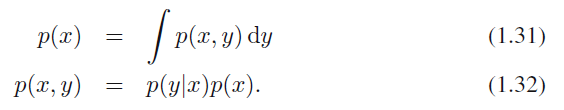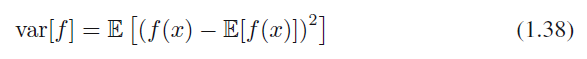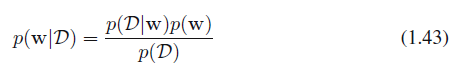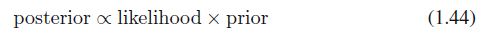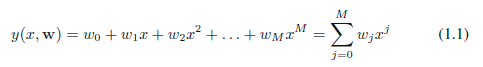앞에서 다룬 다항식 곡선 피팅 예시에서 가장 좋은 일반화 능력을 가지는 최적의 다항식 차수가 있다는 것을 확인할 수 있었습니다.
다항식의 차수에 따라서 모델의 자유 매개변수의 수가 결정되며, 이에 의해서 모델의 복잡도가 결정되게 됩니다.
또한, 정규화된 최소 제곱법의 경우에는 정규화 계수 $\lambda$도 모델의 실제적인 복잡도에 영향을 미쳤습니다.
혼합 분포나 신경망 등의 더 복잡한 모델의 경우 복잡도를 통제하는 매개변수가 더 많을 수도 있습니다.
실제 응용 사례에서는 이러한 매개변수들의 값을 결정해야하며, 이때의 목표는 새로운 데이터에 대한 예측 성능을 최적화하는 것입니다.
주어진 한 모델의 매개변수의 값을 결정하는 것뿐만이 아니라 다양한 여러 모델들을 고려하여 해당 응용 사례에 가장 적합한 모델을 선택해야 할 경우도 있습니다.
최대 가능도 접근법에서 이미 확인한 것과 같이, 훈련 집합에서의 좋은 성능이 반드시 좋은 예측 성능을 보장해 주지는 못합니다. 이는 과적합 문제 때문입니다. 이를 해결할 한 가지 방법은 데이터가 충분할 경우 일부의 데이터만 사용하여 다양한 모델과 모델의 매개변수들을 훈련시키고 독립적인 데이터 집합인 검증 집합(Validation set)에서 이 모델들과 매개변수들을 비교 / 선택하는 것입니다.
만약 한정된 크기의 데이터 집합을 바탕으로 반복적으로 모델 디자인을 시행한다면, 검증 집합에 대해서도 과적합 문제가 발생할 수 있습니다. 이런 상황을 방지하기 위해 시험 집합(Test set)을 따로 분리해 두고 이 집합을 통해서 선택된 모델의 최종 성능을 판단하는 것이 좋을 수도 있습니다.
하지만 대부분의 실제 경우에는 데이터의 공급이 제한적이므로, 시험 집합을 별도로 분리해서 사용하는 것이 부담스러울 수 있습니다.
그리고 검증 집합의 크기가 작을 경우는 예측 성능에 대한 추정값이 정확하지 않을 수도 있습니다.
이러한 딜레마를 해결할 수 있는 한 가지 방법은 바로 교차 검증법(Cross validation)입니다.
그림 1.18
그림 1.18은 교차 검증법을 설명하는 그림입니다.
교차 검증법은 전체 데이터(S) 중 데이터의 (S-1) / S비율만큼 훈련에 사용하고, 모든 데이터를 다 활용하여 성능을 추정할 수 있습니다.
특히 데이터가 부족할 경우에는 S = N의 교차 검증법을 고려할 수도 있습니다. 여기서 N은 전체 데이터 포인트의 숫자입니다.
따라서, S = N 교차 검증법은 데이터 포인트 하나만 남겨두고(leave-one-out) 모델을 훈련시키는 테크닉입니다.
그림에서 빨간색 블록으로 표시되어 있는 것이 남겨 두는 집합이 되며, 이를 이용해서 검증을 진행합니다.
그리고 최종 성능 점수를 도출할 때는 S번의 실행에서의 성능 점수를 평균 내어서 도출하게 됩니다.
교차 검증법의 주요 단점 중 하나는 S의 수가 늘어남에 따라서 모델 훈련의 시행 횟수가 함께 늘어난다는 점입니다. 이는 훈련 자체가 계산적으로 복잡할 경우에 문제가 될 수 있습니다.
분리된 데이터를 활용하여 성능을 측정하는 교차 검증법의 또 다른 문제점은, 한 가지 모델에 여러 가지 복잡도 매개변수가 있을 경우(예를 들면 여러 종류의 정규화 매개변수)에 발생합니다. 여러 매개변수들의 조합들을 확인해 보기 위해서는 최악의 경우 매개변수 숫자에 대해 기하급수적인 수의 훈련 실행이 필요할 수 있습니다.
따라서 이를 통해, 이보다 더 나은 방식이 필요하다는 것을 알 수 있습니다. 이상적인 방식에서는 훈련 집합만을 활용하여 여러 종류의 hyperparameter와 각 모델 종류에 대한 비교를 한 번의 훈련 과정동안 시행할 수 있어야 합니다.
이를 위해서는 오직 훈련 집합만을 활용하는 성능 척도가 필요합니다. 또한, 이 척도는 과적합으로 인한 편향으로부터 자유로워야 합니다.
역사적으로 다양한 '정보 기준(information criteria)'들이 최대 가능도 방법의 편향 문제에 대한 대안으로 제시되어 왔으며, 이는 더 복잡한 모델에서 과적합이 일어나지 않도록 하는 페널티항을 추가하는 방식이였습니다.
예를 들어, 아카이케 정보량 기준(akaike information criterion, AIC)는 다음의 식 1.73의 값이 가장 큰 모델을 선택하는 방식입니다.
식 1.73
여기서 $p(D|\bf{w_{ML}}$$)$은 가장 잘 피팅된 로그 가능도이며, $M$은 모델의 수정 가능한 매개변수의 수 입니다.
베이지안 정보 기준(Bayeseian information criterion, BIC)은 AIC의 약간 변형된 버전인데 이에 대해서는 4.4.1절에서 논의할 예정입니다.
이러한 기준들은 모델 매개변수들의 불확실성을 고려하지 않으며, 또한 실제 적용에서 간단한 모델을 선택하는 경향이 있습니다.
해당 글에서는 Chapter 1. (2)인 확률론에서 1.2.4인 가우시안 분포부터를 다루고 있습니다.
1.2.4 가우시안 분포
이번 장에서는 정규 분포(normal distribution)라고도 불리는 가우시안 분포(Gaussian distribution)에 대해 살펴봅니다.
단일 실수 변수 $x$에 대해서 가우시안 분포는 다음과 같이 정의됩니다.
식 1.46
식 1.46은 두 개의 매개변수 $\mu$와 $\sigma^2$에 의해 통제됩니다. $\mu$는 평균(mean), $\sigma^2$는 분산(variance)입니다.
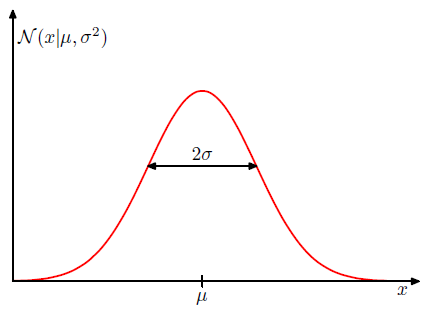
분산의 제곱근 값인 $\sigma$는 표준 편차(standard deviation)이라고 불립니다. 또한, 분산의 역수에 해당하는 $\beta$ = $1/\sigma^2$는 정밀도(precision)이라고도 합니다. 매개변수들이 왜 이런 이름을 가지는지에 대해서 곧 살펴봅니다. 가우시안 분포를 그리면 그림 1.13처럼 나타납니다.
그림 1.13
종 모양의 그림이 되고, 중심이 $\mu$이며 폭이 $2\sigma$인 그래프가 됩니다.
식 1.46으로부터, 가우시안 분포가 다음의 성질을 만족함을 확인할 수 있습니다.
식 1.47
또한, 다음의 성질도 만족합니다.
식 1.48
따라서, 식 1.46은 확률 밀도의 두 가지 조건을 만족시킵니다.
가우시안 분포를 따르는 임의의 $x$에 대한 함수의 기댓값을 구할 수 있습니다. 특히 $x$의 평균값은 다음과 같습니다.
식 1.49
이를 통해 평균값 매개변수 $\mu$가 $x$의 기댓값과 동일함을 확인할 수 있습니다. 이와 비슷하게 $x$에 대한 이차 모멘트는 다음과 같습니다.
식 1.50
식 1.49와 식 1.50으로부터 $x$의 분산을 다음과 같이 계산할 수 있습니다.
식 1.51
$\sigma^2$가 분산임을 확인할 수 있습니다. 분포의 최댓값을 최빈값(mode)이라 하는데, 가우시안 분포의 경우에는 최빈값과 평균값이 동일합니다.
관측된 데이터 $\bf{x}$ = ($x_1$, ... $x_N$)$^T$를 살펴봅니다. 이는 관측된 $N$개의 스칼라 변수 $x$를 지칭합니다. 평균값 $\mu$와 분산 $\sigma^2$를 가지는 가우시안 분포에서 관측값들을 독립적으로 추출한다고 가정합니다.
데이터 집합으로부터 이 매개변수들을 결정하는 것이 우리의 현재 목표입니다.
같은 분포에서 독립적으로 추출된 데이터 포인트들을 독립적이고 동일하게 분포(independent and identically distributed, i.i.d)되었다고 한다. 앞에서 두 독립 사건의 결합 확률은 각 사건의 주변 확률의 곱이라고 하였으므로, i.i.d인 우리의 데이터 집합 $\bf{x}$은 $\mu$와 $\sigma^2$가 주어졌을 때의 조건부 확률을 다음과 같이 적을 수 있습니다.
식 1.53
$\mu$와 $\sigma^2$의 함수로 보면 이 식은 가우시안 분포의 가능도 함수에 해당합니다. 이전에 우리가 가능도 함수를 $p(D|\bf{w}$$)$로 표현했던 것을 생각해보면, 여기서 $\bf{w}$는 매개변수들의 집합이었으며 가우시안 분포에서는 이것이 바로 $\mu$와 $\sigma^2$가 됩니다.
식 1.53를 그림으로 표현한 것이 바로 그림 1.14 입니다.
그림 1.14
그림 1.14에서 빨간색 곡선이 바로 가능도 함수입니다. 여기서 $x$축에 있는 검은색 포인트는 ${x_n}$을 값으로 가지는 데이터 집합을 지칭하며, 식 1.53으로 주어진 가능도 함수는 파란색 포인트의 값들의 곱에 해당합니다. 평균값과 분산을 조정하여 해당 곱을 최대화함으로써 가능도를 최대화할 수 있습니다.
관측된 데이터 집합을 바탕으로 확률 분포의 매개변수를 결정하는 표준적인 방법 중 하나는 가능도 함수를 최대화하는 매개변수를 찾는 것입니다. 가능도 함수를 그냥 사용하지 않고 여기에 로그를 취해서 사용하게 되는데, 로그 함수는 변수에 대해 단조 증가하는 함수이므로 로그를 취한 후 최댓값을 찾는 것이 결국 원래 함수의 최댓값을 찾는 것과 동일하기 때문입니다. 로그를 취함으로써 추후 수학적 분석이 간단해지고, 컴퓨터 계산의 수치적인 측면에서도 도움이 된다고 합니다.
식 1.46과 식 1.53에 따라 로그 가능도 함수를 다음과 같이 적을 수 있습니다.
식 1.54
이에 대해서 $\mu$로 미분했을 때 0이 나오는 최댓값을 찾게 되면 다음의 최대 가능도 해 $\mu_{ML}$를 찾을 수 있습니다.
식 1.55
이는 관찰된 값 {$x_n$}들의 평균인 표본 평균(sample mean)입니다. 이와 비슷한 방식으로 식 1.54의 최댓값을 $\sigma^2$에 대해서 찾으면 분산에 대한 최대 가능도 해를 다음과 같이 찾을 수 있습니다.
식 1.56
이는 표본 평균에 대해 계산된 표본 분산(sample variance)입니다. 가우시안 분포의 경우는 $\mu$에 대한 해가 $\sigma^2$에 대한 해와 연관되어 있지 않습니다. 따라서 식 1.55를 먼저 계산하고 이 결과를 사용해서 식 1.56를 계산할 수 있습니다.
이 장의 뒷부분과 책의 나머지 부분에서 최대 가능도 방법의 한계점에 관해 더 자세히 이야기할 것이지만, 여기서는 우리가 현재 다루고 있는 단변량 가우시안 분포를 기준으로 최대 가능도 방법을 통해 계산한 매개변수값이 어떤 문제를 가지고 있는지 살펴보겠습니다.
최대 가능도 방법은 구조적으로 분포의 분산을 과소평가하게 되는데, 이는 편향(bias)이라고 불리는 현상의 예시로써 다항식 곡선 피팅에서 살펴본 과적합 문제와 연관되어 있습니다.
통계에서 편향이란, 추정량과 모수의 차이를 의미합니다. 예를 들어서, 실제로 평균이 1이고 분산이 0인 가우시안 분포에서 샘플을 뽑는다고 가정합니다. 이때, 샘플을 여러 번 뽑는 과정을 통해서 평균이 1이고 분산이 1이라고 추정했습니다. 이렇게 된다면, 분산에 편향이 발생한 것이다 라고 생각하시면 됩니다.
최대 가능도 해인 $\mu_{ML}$과 $\sigma^2_{ML}$는 데이터 집합인 $x_1, ...x_N$의 함수입니다. $\mu$와 $\sigma^2$를 모수로 하는 가우시안 분포에서 추출된 각 데이터 집합의 값에 대해 이들의 기댓값을 고려해봅시다.
식 1.57, 식 1.58
책에는 너무 당연하다는 식으로 써있지만, 갑자기 왜 이들의 기댓값을 고려해보는지에 대해서 생각해보았습니다.
우리가 표본추출을 통해서 모집단의 평균을 구할 때, 표본평균의 평균을 구하게 됩니다.
또, 표본추출을 통해서 모집단의 분산을 구할 때, 표본분산의 평균을 구하게 됩니다.
따라서, 이와 같은 원리로 식 1.57은 표본평균($\mu_{ML}$)의 평균을 구해서 모집단의 평균을 추정한 것이고
따라서 평균적으로 최대 가능도 추정을 이용하면 평균은 올바르게 구할 수 있지만, 분산은 ($N$ - 1)/$N$만큼 과소평가하게 됩니다. 이 결과에 대한 직관적인 설명은 그림 1.15에서 확인할 수 있습니다.
그림 1.15
그림 1.15를 보면, 최대 가능도 방법을 이용해서 가우시안 분포의 분산을 구하고자 할 때 어떻게 편향이 생기는지를 확인할 수 있습니다. 녹색 곡선은 데이터가 만들어진 실제 가우시안 분포를 나타내며, 세 개의 빨간색 곡선은 세 개의 데이터 집합에 대해 식 1.55와 식 1.56의 최대 가능도 방법을 이용해서 피팅한 가우시안 분포를 나타냅니다.
각각의 데이터 집합은 두 개의 데이터 포인트를 포함하고 있으며, 파란색 원으로 표시되어 있습니다. 세 개의 데이터 집합에 대해 평균을 내면 평균값은 올바르게 계산되지만, 분산 값은 실제 평균값이 아닌 표본 평균값을 기준으로 분산을 계산하기 때문에 구조적으로 과소평가될 수밖에 없습니다.
즉, 분산 값을 계산할 때 실제 평균값(해당 그림에서 가장 중앙에 뾰족 튀어나온 지점)을 기준으로 해서 분산을 계산하는 것이 아닌, 표본 평균값(해당 빨간색 그래프의 평균값)을 기준으로 분산을 계산하므로 실제 분산 값에 비해서 더 적은 값으로 계산된다는 것입니다.
직접 손으로 계산해보지 않더라도, 중앙에 뾰족 튀어나온 지점을 기준으로 분산을 계산하는 것과, 해당 빨간색 그래프의 평균값을 기준으로 분산을 계산하는 것에는 차이가 있다는 것이 느껴지실 것입니다.
식 1.58로부터 다음 식 1.59에서 보이는 분산 추정치는 비편향임을 알 수 있습니다.
식 1.59
데이터 포인트의 개수인 $N$이 커질수록 최대 가능도 해에서의 편향치는 점점 줄어들게 됩니다. 만약 $N$이 무한대로 갈 경우에는 최대 가능도 해의 분산과 데이터가 추출된 원 분포의 분산이 같아짐을 확인할 수 있습니다. 실제 적용 사례에서는 $N$이 아주 작은 경우가 아니면 이 편향은 그렇게까지 큰 문제는 되지 않습니다.
하지만 이 책 전반에 걸쳐 많은 매개변수를 포함한 복잡한 모델에 대해 살펴볼 것인데, 이 경우 최대 가능도 방법과 연관된 편향 문제는 더욱 심각해집니다. 최대 가능도 방법의 편향 문제는 우리가 앞에서 살펴본 다항식 곡선 피팅에서의 과적합 문제의 근본적인 원인에 해당합니다.
1.2.5 곡선 피팅
앞에서는 다항식 곡선 피팅 문제를 오차 최소화의 측면에서 살펴보았습니다. 여기서는 같은 곡선 피팅 문제를 확률적 측면에서 살펴봄으로써 오차 함수와 정규화에 대한 통찰을 얻어봅니다. 또한, 완전한 베이지안 해결법을 도출하는 데 도움이 될 것입니다.
곡선 피팅 문제의 목표는 $N$개의 입력값 $\bf{x}$ = ($x_1, ... x_N$)$^T$과 해당 표적 값 $\bf{t}$ = ($t_1, ... t_N$)$^T$가 주어진 상황에서 새로운 입력 변수 $x$가 주어졌을 때 그에 대한 타깃 변수 $t$를 예측해 내는 것입니다.
확률 분포를 이용해서 타깃 변수의 값에 대한 불확실성을 표현할 수 있습니다. 이를 위해서 주어진 $x$값에 대한 $t$값이 $y(x, \bf{w}$$)$를 평균으로 가지는 가우시안 분포를 가진다고 가정합니다. 여기서 $y(x, \bf{w}$$)$는 앞의 식 1.1에서 주어졌던 다항식 곡선입니다. 이를 바탕으로 다음의 조건부 분포를 적을 수 있습니다.
식 1.60
여기서 사용한 $\beta$는 정밀도 매개변수로 분포의 분산의 역수에 해당합니다. 이 식을 도식화해 놓은 것이 바로 그림 1.16입니다.
그림 1.16
해당 그림에서 파란색 점과 빨간색 점은 설명을 위해 제가 그린 점입니다.
일단 빨간색 곡선으로 그려진 것은 우리가 데이터를 통해서 학습시킨 다항식 곡선이라고 보시면 됩니다. 그림에서는 $y(x, \bf{w}$$)$라고 표현되어 있습니다.
그리고 그림에서 $y(x_0, w)$라고 표시된 것은, $x$의 값이 $x_0$일 때, 다항식 곡선을 이용해서 예측된 prediction 값이라고 보시면 되겠습니다.
우리는 현재 주어진 $x$ 값에 대한 $t$값이 이 예측된 값을 평균으로 가지는 가우시안 분포를 가진다고 가정하기 때문에, 그림이 현재 형광 녹색으로 표시된 지점을 기준으로 파란색으로 그려진 가우시안 분포가 그려진 것입니다.
그렇다면, 해당 그림에서 특정 지점(데이터 포인트)에 대해서 조건부 확률 값을 어떻게 구할까요?
예를 들어서, 데이터가 $x$ 값이 $x_0$일 때, 파란색 점이 타깃 변수(정답 값) $t$의 위치라고 하겠습니다.
그렇다면 해당 타깃 변수의 값에 대한 조건부 확률 값은, 파란색 가우시안 곡선으로 그려진 $p(t|x_0, w, \beta)$로 계산되는 값이 될 것이며, 그림 상에서 빨간색 점이 됩니다.
가우시안 분포의 특성상, 타깃 변수의 값이 가우시안 분포의 평균과 동일할 때, 조건부 확률 값이 가장 커질 것이며 타깃 변수의 값과 가우시안 분포의 평균이 멀어질수록 조건부 확률 값이 작아질 것입니다.
이제 훈련 집합 {$\bf{x}, \bf{t}$}를 바탕으로 최대 가능도 방법을 이용해 알려지지 않은 매개변수 $\bf{w}$와 $\beta$를 구해보도록 합시다. 만약 데이터가 식 1.60의 분포에서 독립적으로 추출되었다고 가정하면, 가능도 함수는 다음과 같이 주어집니다.
식 1.61
앞에서와 마찬가지로 가능도 함수에 로그를 취해 그 최댓값을 구하는 것이 편리합니다. 식 1.46의 가우시안 분포를 대입해 넣으면 다음과 같은 형태의 로그 가능도 함수를 얻게 됩니다.
식 1.62
첫 번째로 다항식 계수 $\bf{w_{ML}}$의 최대 가능도 해를 구해봅니다.
$\bf{w}$에 대해 식 1.62를 최대로 만드는 값을 구하면 됩니다. 이 과정에서 식 1.62의 오른쪽 변의 마지막 두 항은 관련이 없으므로 제외합니다. 또한, 로그 가능도에 양의 상수를 곱해도 상관없으므로, 맨 앞의 계수를 1/2로 바꿔줍니다. 마지막으로 로그 가능도를 최대화하는 대신에 로그 가능도의 음의 값을 취한 후, 이를 최소화할 수 있습니다. 이를 식으로 표현하자면 $min \frac{1}{2} \sum_{n=1}^N\left\{y(x_n, w)-t_n\right\}^2$이 됩니다.
결과적으로 $\bf{w}$를 구하는 경우에 가능도 함수를 최대화하는 것은 식 1.2에서 나왔던 제곱합 오차 함수를 최소화하는 것과 같다는 것을 알 수 있습니다. 노이즈가 가우시안 분포를 가진다는 가정하에 가능도 함수를 최대화하는 시도의 결과로 제곱합 오차 함수를 유도할 수 있는 것입니다.
마찬가지로 가우시안 조건부 분포의 정밀도 매개변수 $\beta$를 결정하는 데도 최대 가능도 방법을 사용할 수 있으며, 식 1.62를 $\beta$에 대해 최대화하면 다음의 식이 도출됩니다.
식 1.63
단순 가우시안 분포의 경우와 마찬가지로 평균값에 해당하는 매개변수 벡터 $\bf{w_{ML}}$을 먼저 구한 후에 이를 사용하여 정밀도 $\beta_{ML}$를 구할 수 있습니다.
매개변수 $\bf{w}$와 $\beta$를 구했으니 이제 이를 바탕으로 새로운 변수 $x$에 대해 예측값을 구할 수 있습니다. 이제 우리는 확률 모델을 사용하고 있으므로 예측값은 전과 같은 하나의 점 추정값이 아닌 $t$에 대한 예측 분포(predictive distribution)으로 표현될 것입니다. 최대 가능도 매개변수들을 식 1.60에 대입하면 다음을 얻을 수 있습니다.
식 1.64
이를 설명해보자면 다음과 같이 설명할 수 있을 것 같습니다.
input value $x$에 대해서, 피팅된 곡선(곡선의 가중치 $\bf{w_{ML}}$)를 이용하면 예측값을 구할 수 있습니다.
이 예측값을 평균으로, $\beta^{-1}_{ML}$를 분산으로 하는 가우시안 분포를 t가 따른다는 것입니다. 그래서 예측 분포라는 용어를 사용하여 식 1.64를 설명한 것이라고 이해를 해볼 수 있을 것 같습니다.
베이지안 방식을 향해 한 걸음 더 나아가 보겠습니다. 이를 위해 다항 계수 $\bf{w}$에 대한 사전 분포를 도입할 것입니다. 문제의 단순화를 위해 다음 형태를 지닌 가우시안 분포를 사용해봅니다.
식 1.65
여기서 $\alpha$는 분포의 정밀도이며, $M + 1$은 $M$차수 다항식 벡터 $\bf{w}$의 원소의 개수입니다. ($M$차수 이면 마지막 상수항 $w_0$가 존재하므로 $M +1$개가 되는 것으로 생각이 됩니다.) $\alpha$와 같이 모델 매개변수의 분포를 제어하는 변수들을 초매개변수(hyperparameter)라 합니다. 베이지안 정리에 따라서 $\bf{w}$의 사후 분포는 사전 분포와 가능도 함수의 곱에 비례합니다.
식 1.66
이제 주어진 데이터에 대해 가장 가능성이 높은 $\bf{w}$를 찾는 방식으로 $\bf{w}$를 결정할 수 있습니다. 바꿔 말하면 사후 분포를 최대화하는 방식으로 $\bf{w}$를 결정할 수 있다는 것입니다. 이 테크닉을 최대 사후 분포(maximum posterior, MAP)라고 합니다. 식 1.66에 대해 음의 로그를 취한 식 1.62, 식 1.65와 결합하면 사후 확률의 최댓값을 찾는 것이 다음 식 값의 최솟값을 찾는 것과 동일함을 알 수 있습니다.
식 1.67
식 1.66에 음의 로그를 취하면
식 1.62와 식 1.65의 합으로 구성됩니다. 여기서 우리는 적절한 $\bf{w}$를 구하는 것이 목표이므로, $\frac{N}{2}ln\beta$ 등의 상수항들을 제외해줍니다.
그러고 나서 -를 곱해줘서 최소화 문제로 바꿔주면, 식 1.67을 최소화하는 문제로 바뀌게 됩니다.
이처럼 사후 분포를 최대화하는 것이 정규화 매개변수가 $\lambda = \alpha/\beta$로 주어진 식 1.4의 정규화된 제곱합 오차 함수를 최소화하는 것과 동일함을 확인할 수 있습니다.
1.2.6 베이지안 곡선 피팅
비록 사전 분포 $p(\bf{w}$|$\alpha$)를 포함시키긴 했지만, 여전히 $\bf{w}$에 대해서 점 추정을 하고 있기 때문에 아직은 완벽한 베이지안 방법론을 구사한다고 말할 수 없습니다. 완전한 베이지안적 접근을 위해서는 확률의 합의 법칙과 곱의 법칙을 일관적으로 적용해야 합니다. 이를 위해서는 모든 $\bf{w}$ 값에 대해서 적분을 시행해야 합니다. 이러한 주변화(marginalization)가 패턴 인식에서의 베이지안 방법론의 핵심입니다.
곡선 피팅 문제의 목표는 훈련 집합 데이터 $\bf{x}$와 $\bf{t}$가 주어진 상황에서 새로운 변수 $x$에 대한 타깃 값 $t$를 예측하는 것입니다. 이 목표를 위해서 예측 분포 $p(t|x, \bf{x}, \bf{t}$$)$를 구해봅시다. 여기서는 매개변수 $\alpha$와 $\beta$는 고정되어 있으며, 미리 알려졌다고 가정합니다.
단순히 말하자면 베이지안 방법은 단지 확률의 합과 곱의 법칙을 계속적으로 적용하는 것입니다. 이를 통해 예측 분포를 다음과 같은 형태로 적을 수 있습니다.
식 1.68
여기서 $p(t|x, \bf{w}$$)$는 식 1.60에서 주어진 것입니다. 간략한 표기를 위해 $\alpha$와 $\beta$에 대한 종속성은 생략했습니다.
$p(w|\bf{x}, \bf{t}$$)$는 매개변수들에 대한 사후 분포이며, 식 1.66의 오른쪽 변을 정규화함으로써 구할 수 있습니다.
3.3절에서는 곡선 피팅 예시와 같은 문제의 경우 사후 분포가 가우시안이며, 해석적으로 계산할 수 있다는 것에 대해서 살펴봅니다. 이와 비슷하게 식 1.68의 적분을 시행하면 예측 분포가 다음의 식 1.69와 같이 가우시안 분포로 주어진다는 것을 알 수 있습니다.
식 1.69
여기서 평균과 분산은 다음과 같습니다.
식 1.70, 식 1.71
행렬 $\bf{S}$는 다음처럼 주어집니다.
식 1.72
$\bf{I}$는 단위 행렬이며, $\phi(x)$는 각각의 원소가 $i = 0, ..., M$에 대해 $\phi_i(x) = x^i$인 벡터입니다.
아마 이거 읽는 분들도 이게 왜 나왔을까... 궁금하시겠지만 따로 뭐 도출 과정이나 이런 게 책에 없어서 왜 이렇게 계산되었는지는 알 수가 없었네요 ㅠㅠ
식 1.69를 살펴보면, 예측 분포의 평균과 분산이 $x$에 종속되어 있음을 알 수 있습니다. 타깃 변수의 노이즈로 인한 예측값 $t$의 불확실성이 식 1.71의 첫 번째 항에 표현되어 있습니다. 이 불확실성은 식 1.64의 최대 가능도 예측 분포에서 $\beta^-1_{ML}$로 이미 표현되었습니다. 하지만 식 1.71의 두 번째 항은 $\bf{w}$의 불확실성으로부터 기인한 것이며, 베이지안 접근법을 통해 구해진 것입니다.
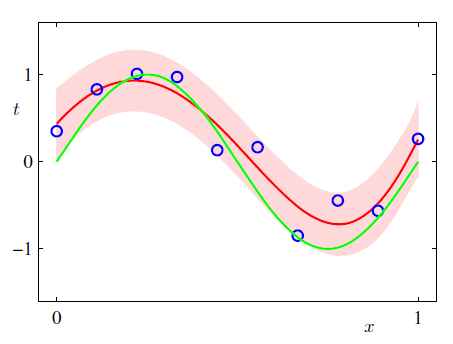
그림 1.17
그림 1.17은 베이지안적 방법을 통해 구한 $M= 9$ 다항식 곡선 피팅 문제의 예측 분포를 나타내는 그림입니다.
$\alpha = 5 \times 10^{-3}$, $\beta = 11.1$을 사용하였습니다. 빨간색 선은 예측 분포의 평균값을, 그리고 빨간색 영역은 평균값으로부터 $\pm1$ 표준 편찻값을 가지는 부분을 표현한 것입니다. 녹색선은 해당 데이터를 만들 때 사용되었던 $sin(2\pi x)$를 나타낸 그림입니다. 파란색 동그라미인 데이터 포인트는 녹색선을 기준으로 약간의 노이즈를 포함시켜서 만들어낸 데이터라고 보시면 되겠습니다.
최대한 이해해보려고 노력하면서 읽긴 하지만, 역시나 쉽진 않은 책이라는 게 느껴집니다.
특히 조금 간단한 예시를 들었으면 좋았을 텐데... 너무 자명하다는 식으로 쓴 내용들이 많아 이해가 쉽진 않군요 ㅠㅠ
패턴 인식 분야에서 주요한 콘셉트 중 하나는 바로 불확실성입니다. 불확실성은 측정할 때의 노이즈를 통해서도 발생하고, 데이터 집합 수가 제한되어 있다는 한계점 때문에도 발생합니다. 확률론은 불확실성을 계량화하고 조작하기 위한 이론적인 토대를 마련해 주며, 패턴 인식 분야의 중요한 기반이기도 합니다. 1.5절에서 논의할 의사 결정 이론과 이번 절의 확률론을 함께 활용하면, 주어진 정보가 불확실하거나 완전하지 않은 제약 조건하에서도 최적의 예측을 시행할 수 있게 됩니다.
하나의 예시를 들어보겠습니다.
그림 1.9
한 개의 빨간색 상자와 한 개의 파란색 상자가 있고, 빨간색 상자에는 두 개의 사과와 여섯 개의 오렌지, 파란색 상자에는 한 개의 오렌지와 세 개의 사과가 있습니다. 랜덤 하게 상자 하나를 골라 임의로 과일 하나를 꺼내고, 어떤 과일인지 확인한 후 꺼냈던 상자에다 도로 집어넣는 상황을 생각해봅니다. 빨간색 상자를 고를 확률은 40%, 파란색 상자를 고를 확률은 60%라고 합니다. 상자 안에서 각각의 과일을 고를 확률은 동일하다고 가정합니다.
이 예시에서 상자는 확률 변수이며, 확률 변수 $B$라고 지칭합니다. 확률 변수 B는 $r$(빨간색 상자)와 $b$(파란색 상자) 두 개의 값을 가질 수 있습니다.
과일 또한 확률 변수이며, 여기서는 $F$로 지칭합니다. 확률 변수 F는 $a$(사과) 또는 $o$(오렌지)를 값으로 가질 수 있습니다.
어떤 사건의 '확률'을 무한 번 시도한다고 가정했을 때 어떤 특정 사건이 일어나는 횟수를 전체 시도의 횟수로 나눈 것으로 정의해본다면, $p(B=r)$ = 4/10이고, $p(B=b)$ = 6/10 입니다.
이러한 확률 말고, 조금 더 복잡한 확률에 대해서 알아보기 위해 먼저 확률의 두 가지 기본 법칙인 합의 법칙(sum rule)과 곱의 법칙(product rule)에 대해서 먼저 살펴봅니다.
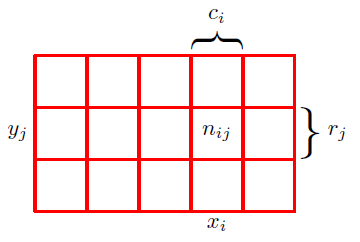
확률의 법칙을 설명하기 위해, 그림 1.10의 예시를 고려해보겠습니다.
그림 1.10
해당 예시에서는 $X$와 $Y$라는 두 가지 확률 변수를 생각합니다. $X$는 $x_i(i = 1, ..,M)$ 중 아무 값이나 취할 수 있고, $Y$는 $y_j(j = 1, ... L)$ 중 아무 값이나 취할 수 있다고 가정합니다. 여기서 $M$ = 5이고, $L$ = 3입니다.
또한, $X$와 $Y$ 각각에서 표본을 추출하는 시도를 $N$번 한다고 합니다. 그리고 $X = x_i, Y = y_j$인 시도의 개수를 $n_{ij}$로 표현합니다. 그리고 $Y$의 값과는 상관없이 $X = x_i$인 시도의 숫자를 $c_i$로, $X$의 값과는 상관없이 $Y = y_j$인 시도의 숫자를 $r_j$로 표현할 것입니다.
$X$가 $x_i$, $Y$가 $y_j$일 확률을 $p(X = x_i, Y = y_j)$로 적고, 이를 $X = x_i, Y = y_j$일 결합 확률(joint probability)이라고 칭합니다. 이는 $i, j$ 칸에 있는 포인트의 숫자를 전체 포인트들의 숫자로 나눠서 구할 수 있는데요, 따라서 다음 식 1.5와 같이 표현할 수 있습니다.
식 1.5
여기서는 $lim N -> \infty$를 가정합니다. 비슷하게 $Y$ 값과 무관하게 $X$가 $x_i$값을 가질 확률을 $p(X = x_i)$로 적을 수 있으며, 이는 $i$열에 있는 포인트들의 숫자를 전체 포인트들의 숫자로 나눔으로써 구할 수 있습니다. 이를 식으로 표현하면 식 1.6로 표현할 수 있습니다.
식 1.6
그림 1.10에서 $i$열에 있는 사례의 숫자는 해당 열의 각 칸에 있는 사례의 숫자 합입니다. 이는 $c_i = \sum_j n_{ij}$로 표현 가능합니다. 따라서, 식 1.5와 식 1.6을 바탕으로 식 1.7을 도출해 낼 수 있습니다.
식 1.7
이것이 바로 확률의 합의 법칙(sum rule)입니다. 때때로 $p(X= x_i)$는 주변 확률(marginal probability)이라고 불립니다.
합의 법칙을 말로 좀 풀어서 생각해보자면, 어떤 주변 확률을 구하려면 결합 확률을 이용해서 구할 수 있는데 결합 확률에 포함된 다른 확률 변수들의 모든 경우를 다 더했을 때 구할 수 있다 정도로 이해해볼 수 있겠습니다.
훨씬 단순한 예시를 하나 들자면... 상의 2가지 하의 3가지가 있으면 우리가 입을 수 있는 모든 옷의 경우의 수는 6가지가 될 것인데요. 여기서 1번 상의를 입게 될 확률은 결국 1번 상의 + 1번 하의 / 1번 상의 + 2번 하의 / 1번 상의 + 3번 하의를 입을 확률을 더해야 된다는 것이죠. 즉, 내가 어떤 확률 변수에 대한 주변 확률을 구하려면, 결합 확률에 포함된 다른 확률 변수들의 모든 케이스를 다 더했을 때 구할 수 있다는 것입니다.
$X = x_i$인 사례들만 고려해 봅시다. 그들 중에서 $Y = y_j$인 사례들의 비율을 생각해 볼 수 있고, 이를 확률 $p(Y = y_j | X = x_i)$로 적을 수 있습니다. 이를 조건부 확률(conditional probability)이라고 부릅니다. 이 경우엔 $X = x_i$가 주어졌을 경우 $Y = y_j$일 조건부 확률을 의미합니다. 이는 $i$행에 있는 전체 포인트 수와 $i, j$칸에 있는 포인트 수의 비율을 통해서 계산할 수 있습니다.
수식 1.8
일반 확률과 조건부 확률의 차이라고 한다면, 일반 확률은 시행 횟수 N으로 나누지만 조건부 확률은 시행 횟수 모두를 고려하는 것이 아닌, 조건에 해당하는 경우(위 수식 1.8에서는 $X = x_i$인 경우)만 고려하기 때문에 확률을 구할 때 분모의 값이 달라지게 됩니다. 이 부분이 가장 핵심이라고 생각합니다.
식 1.5, 식 1.6, 식 1.8에서 다음의 관계를 도출해 낼 수 있습니다.
식 1.9
이것이 바로 확률의 곱의 법칙(product rule)입니다.
이를 말로 풀어서 설명하자면, A와 B의 결합 확률은 A를 선택할 확률과 A를 선택했다고 생각했을 때 B를 선택할 확률의 곱이 된다는 것입니다.
제가 앞에 들었던 상의 2가지, 하의 3가지의 간단한 예시로 생각해보겠습니다. 1번 상의와 1번 하의를 입는 확률을 생각해본다면, 확률은 1/6이 됩니다. 전체 경우의 수 6가지 중 1가지가 되니까요.
$p(Y = y_j | X = x_i)$를 생각해보겠습니다. $X$를 상의, $Y$를 하의라고 생각하면 이는 1번 상의를 입는다는 가정 하에 1번 하의를 입을 확률입니다. 1번 상의를 입는다고 가정하면, 하의는 1번 2번 3번 총 3가지밖에 없으므로 이는 1/3이 됩니다.
$p(X = x_i)$를 생각해보겠습니다. 상의는 2가지가 있으므로, 1번 상의를 입을 확률은 1/2가 됩니다.
따라서 식 1.9에서 정의한 것처럼, 1/6 = 1/3 * 1/2 가 성립함을 확인할 수 있습니다.
지금까지 얘기한 확률의 두 법칙을 조금 더 간단한 표현법을 사용해 표현하면 다음과 같습니다.
식 1.10, 식 1.11
곱의 법칙과 대칭성 $p(X, Y) = p(Y, X)$로부터 조건부 확률 간의 관계인 다음 식을 도출해낼 수 있습니다.
식 1.12
식 1.12는 머신 러닝과 패턴 인식 전반에 걸쳐서 아주 중요한 역할을 차지하고 있는 베이즈 정리(Bayes' theorem)입니다. 위에서 언급한 합의 법칙을 사용하면 베이지안 정리의 분모를 분자에 있는 항들로 표현할 수 있습니다.
식 1.13
베이지안 정리의 분모는 정규화 상수로 볼 수 있습니다. 즉, 식 1.12의 왼쪽 항을 모든 $Y$값에 대하여 합했을 때 1이 되도록 하는 역할인 것이죠.
이제 원래 논의했던 과일 상자 예시로 돌아가 봅시다. 빨간색 상자를 선택하거나 파란색 상자를 선택하는 확률은 다음과 같습니다.
수식 1.14, 수식 1.15
위의 식 1.14와 식 1.15의 합이 1을 만족시킨다는 것을 확인할 수 있습니다.
상자가 주어졌을 때 사과 또는 오렌지를 선택할 확률 네 가지를 다음과 같이 적을 수 있습니다.
수식 1.16 ~ 수식 1.19
마찬가지로, 이 확률들은 정규화되어 있기 때문에 다음 식 1.20과 식 1.21을 만족시킵니다.
식 1.20, 식 1.21
이제 확률의 합의 법칙과 곱의 법칙을 적용하여 사과를 고를 전체 확률을 계산할 수 있습니다.
수식 1.22
여기에 다시 합의 법칙을 적용하면 $p(F = 0)$ = 1 - 11/20 = 9/20입니다.
어떤 한 종류의 과일을 선택했는데 그것이 오렌지고, 이 오렌지가 어떤 상자에서 나왔는지를 알고 싶다고 가정해봅니다. 이는 베이지안 정리를 적용해서 구할 수 있습니다.
수식 1.23
합의 법칙에 따라 $p(B = b | F = o)$ = 1 - 2/3 = 1/3이 됩니다.
베이지안 정리를 다음과 같이 해석할 수 있습니다.
만약 어떤 과일이 선택되었는지를 알기 전에 어떤 박스를 선택했냐고 묻는다면 그 확률은 $p(B)$일 것입니다. 이를 사전 확률(prior probability)이라고 부릅니다. 왜냐하면 어떤 과일이 선택되었는지 관찰하기 '전'의 확률이기 때문이죠. 선택된 과일이 오렌지라는 것을 알게 된다면 베이지안 정리를 활용하여 $p(B|F)$를 구할 수 있습니다. 이는 사후 확률(posterior probability)이라고 부를 수 있는데, 이는 사건 $F$를 관측한 '후'의 확률이기 때문입니다.
이 예시에서 빨간색 상자를 고를 사전 확률은 4/10이므로, 파란색 상자를 고를 확률이 더 높습니다. 하지만, 선택된 과일이 오렌지라는 것을 확인하고 난 후엔 빨간색 상자를 고를 사후 확률이 2/3입니다. 따라서 이제는 우리가 고른 상자가 빨간색이었을 확률이 더 높게 됩니다. 이는 빨간색 상자 안의 오렌지의 비율이 파란색 상자 안의 오렌지의 비율보다 높기 때문이죠. 오렌지를 골랐다는 증거가 충분히 강력하기 때문에 사전 지식을 뒤엎고 빨간색 상자를 골랐을 확률을 파란색 상자를 골랐을 확률보다 더 높게 만들어주는 것입니다.
$p(X, Y) = p(X)p(Y)$인 경우를 고려해 봅시다. 이처럼 각각의 주변 확률을 곱한 것이 결합 확률과 같을 경우 두 확률 변수를 독립적(independent)이라고 합니다. 곱의 법칙에 따라 $p(Y|X) = p(Y)$임을 알 수 있고, 이는 $X$가 주어졌을 때 $Y$의 조건부 확률은 실제로 $X$의 값과 독립적임을 확인할 수 있습니다.
1.2.1 확률 밀도
지금까지는 이산적인 사건들을 바탕으로 확률을 알아보았는데, 이번에는 연속적인 변수에서의 확률에 대해 알아봅니다.
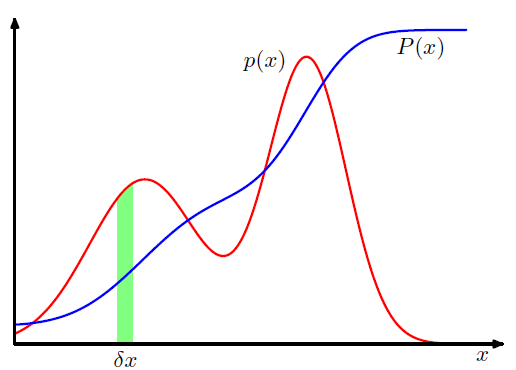
만약 실수 변수 $x$가 ($x$, $x+\delta x$) 구간 안의 값을 가지고 그 변수의 확률이 $p(x) \delta x$($\delta x$ -> 0 일 경우)로 주어진다면, $p(x)$를 $x$의 확률 밀도(probability density)라고 부릅니다. 이는 그림 1.12로 표현될 수 있습니다.
그림 1.12 p(x) => 확률 밀도, P(x) => 누적 분포 함수
이때 $x$가 (a, b) 구간 사이의 값을 가질 확률은 다음과 같이 주어집니다.
식 1.24
단순하게, 확률 밀도 함수를 x = a부터 x = b까지 적분을 해주면 확률을 구할 수 있습니다.
확률은 양의 값을 가지고 $x$의 값은 실수축상에 존재해야 하므로, 다음 두 조건을 만족시켜야 합니다.
식 1.25, 식 1.26
확률 분포 함수는 야코비안 인자로 인해 비선형 변수 변환 시에 일반적인 단순 함수와는 다른 방식으로 변화하게 됩니다. 예를 들어, $x = g(y)$의 변수 변환을 고려해 봅시다. 그러면 함수 $f(x)$는 $\tilde{f}(y)$ = $f(g(y))$가 됩니다. $x$의 확률 밀도 함수 $p_x(x)$와 새로운 변수 $y$의 확률 밀도 함수 $p_y(y)$를 살펴보면 둘이 다른 확률 밀도를 가진다는 것이 자명합니다. ($x$, $x + \delta x$) 범위에 속하는 관찰 값은 범위 ($y$, $y + \delta y$)로 변환될 것입니다. 이때 $p_x(x) \delta x $ $\simeq$ $p_y(y) \delta y $입니다. 따라서 다음과 같습니다.
식 1.27
이로부터, 확률 밀도의 최댓값은 어떤 변수를 선택하는지에 따라 달라짐을 알 수 있습니다.
책에는 식 1.27가 어떤 식으로 도출되는지에 대한 내용이 전혀 없어서, 왜 갑자기 저런 식이 나오는지 알 수 없었습니다. 이에 저는 관련된 내용을 찾아서 나름대로 정리를 해 보았는데요.
식 1.27가 나오는 과정이 궁금하시다면, 아래에 있는 더보기 부분을 누르셔서 확인하실 수 있습니다.
따라서, Y의 확률 밀도 함수는 $f_Y(y) = f_X(g(y)) \left| \frac{dx}{dy} \right|$ 입니다.
이 확률 밀도 함수를 이용하면, 식 1.27처럼 $p_y(y) = p_x(x) \left| \frac{dx}{dy} \right| = p_x(g(y))|g'(y)|$가 됩니다.
$x$가 ($-\infty, z$) 범위에 속할 확률은 누적 분포 함수(cumulative distribution function)로 표현될 수 있습니다.
식 1.28
누적 분포 함수는 곧 $-\infty$부터 $z$까지 확률밀도함수를 적분한 것을 의미합니다.
또, 그림 1.12에서 보인 것처럼 $P'(x) = p(x)$ 입니다.
만약 여러 개의 연속적인 변수 $x_1, ... x_D$가 주어지고 이 변수들이 벡터 $\bf{x}$로 표현될 경우에 결합 확률 밀도 $p(\bf{x}$$)$ = $p(x_1, .. x_D)$를 정의할 수 있습니다. 이 확률 밀도에서 $\bf{x}$가 포인트 $\bf{x}$를 포함한 극솟값 $\delta \bf{x}$에 포함될 확률은 $p(\bf{x}$$)$$\delta \bf{x}$로 주어집니다. 이 다변량 확률 밀도는 다음 조건을 만족해야 합니다.
식 1.29, 식 1.30
식 1.30에서의 적분은 전체 $x$ 공간에 대해서 시행하는 것이며, 이산형 변수와 연속형 변수가 조합된 경우에 대해서도 결합 확률 분포를 고려하는 것이 가능합니다.
만약 $x$가 이산 변수일 경우 $p(x)$를 때때로 확률 질량 함수(probability mass function)라고 부르기도 합니다.
연속 변수의 확률 밀도와 이산형 변수/연속형 변수가 조합된 경우의 확률 밀도에서도 합의 법칙, 곱의 법칙, 베이지안 정리를 적용할 수 있습니다. 예를 들어 $x, y$가 실수 변수인 경우, 합과 곱의 법칙은 다음과 같이 표현할 수 있습니다.
식 1.31, 식 1.32
1.2.2 기댓값과 공분산
확률 밀도 $p(x)$ 하에서 어떤 함수 $f(x)$의 평균값은 기댓값(expectation)이라 하며, $E[f]$라 적습니다.
이산 분포의 경우 기댓값은 다음과 같이 주어집니다.
식 1.33
쉽게 생각하면, 각 $x$ 값에 대해 해당 확률을 가중치로 사용해서 가중치 x 값을 이용해서 가중 평균을 구하는 것입니다.
연속 변수의 경우에는 확률 밀도에 대해 적분을 해서 기댓값을 구합니다.
식 1.34
만약 유한한 $N$개의 포인트를 확률 분포 또는 확률 밀도에서 추출했다면, 포인트들의 합으로 기댓값을 근사할 수 있습니다.
식 1.35
다변수 함수의 기댓값을 구할 경우에는 어떤 변수에 대해 평균을 내는지를 지정해서 계산할 수 있습니다.
식 1.36
식 1.36은 함수 $f(x, y)$의 평균값을 $x$의 분포에 대해 구하라는 의미입니다. 이는 $y$에 대한 함수가 될 것입니다. ($x$에 대해서 계산한 것이므로)
또한, 조건부 분포에 해당하는 조건부 기댓값(conditional expectation)도 생각해 볼 수 있습니다.
식 1.37
$f(x)$의 분산(variance)은 다음과 같이 정의됩니다.
식 1.38
분산은 $f(x)$가 평균값으로부터 전반적으로 얼마나 멀리 분포되어 있는지를 나타내는 값입니다. 위 식을 전개하면 다음과 같이 표현할 수 있습니다.
식 1.39
고등학교 수학에서는 보통 제곱의 평균 - 평균의 제곱으로 많이 외우곤 합니다.
두 개의 확률 변수 $x$와 $y$에 대해서 공분산(covariance)은 다음과 같이 정의됩니다.
식 1.41
공분산은 $x$ 값과 $y$ 값이 얼마나 함께 같이 변동하는가에 대한 지표이며, 서로 독립이면 공분산은 0입니다.
두 확률 변수 $x$와 $y$가 벡터일 경우에는 공분산은 행렬이 됩니다.
식 1.42
1.2.3. 베이지안 확률
지금까지 우리는 확률을 '반복 가능한 임의의 사건의 빈도수'라는 측면에서 살펴보았습니다. 이러한 해석을 고전적(classical) 또는 빈도적(frequentist) 관점이라고 일컫는데요. 이보다 더 포괄적인 베이지안(Bayesian) 관점에 대해서 살펴봅니다. 베이지안 관점을 이용하면 확률을 이용해 불확실성을 정량화하는 것이 가능합니다.
어떤 불확실한 사건에 대해서 생각해보겠습니다. 예를 들어 '북극의 빙하가 이번 세기까지 다 녹아 없어진다'는 사건을 생각해보면, 이런 사건들은 여러 번 반복할 수 없습니다. 따라서 빈도적 관점에서 확률을 정의하는 것이 불가능합니다. 물론, 우리는 이러한 사건들에 대해 어떤 견해를 가지고 있긴 할 텐데요. 예를 들면 '북극의 얼음이 이 정도 속도로 녹는다'와 같은 의견이 될 수 있습니다.
만약 우리가 새로운 증거를 추가할 수 있다면 얼음이 녹는 속도에 대한 우리의 의견을 수정할 수 있을 것입니다. 이런 증거가 강력하다면 우리의 판단에 따라 취할 행동이 바뀔 수도 있죠. 예를 들어서, 얼음이 녹는 속도가 빠르다는 증거를 관측했다면 기후 변화를 늦추기 위해 노력할 수 있습니다. 이런 상황들에서 주어진 불확실성을 정량화하고, 새로운 증거가 주어질 때마다 불확실성을 수정하고 그 결과에 따라 최적의 선택을 내리고 싶을 때, 이것이 가능하게 해주는 방법론이 바로 확률의 베이지안 해석입니다. 즉 확률을 불확실성을 나타내는 도구로 활용하는 것이죠.
확률에 대한 개념을 더 일반적으로 확장하는 것은 패턴 인식 분야에서도 큰 도움이 됩니다. 1.1절의 다항 곡선 피팅 예시를 다시 생각해보겠습니다. 적합한 모델 매개변수 $\bf{w}$를 정하는 데 있어서 불확실성을 수치화하고 표현하려면 어떻게 해야 할까요? 이때 베이지안 관점을 사용하면 확률론의 다양한 장치들을 활용하여 $\bf{w}$와 같은 모델 매개변수의 불확실성을 설명할 수 있습니다. 더 나아가, 베이지안 관점은 모델 그 자체를 선택하는 데 있어서도 유용합니다.
앞의 과일 상자 예시에서 어떤 과일이 선택되었는지에 대한 관측 결과가 선택된 상자가 어떤 것이었을지에 대한 확률을 바꾸었던 것을 기억해 봅시다. 해당 예시에서 베이지안 정리는 관측값들을 이용하여 사전 확률을 사후 확률로 바꾸는 역할을 했습니다. 다항 곡선 피팅 예시의 매개변수 $\bf{w}$와 같은 값들을 추론해 내는 데 있어서도 비슷한 방식을 사용할 수 있습니다.
일단, 첫 번째로 데이터를 관측하기 전의 $\bf{w}$에 대한 우리의 가정을 사전 확률 분포 $p(\bf{w})$로 표현할 수 있습니다. 관측된 데이터 $D$ = {${t_1, ... t_N}$}은 조건부 확률 $p(D|\bf{w})$로써 작용하게 됩니다. 이 경우 베이지안 정리는 다음의 형태를 띱니다.
식 1.43
$D$를 관측한 후의 $\bf{w}$에 대한 불확실성을 사후 확률 $p(\bf{w}$$|D)$로 표현한 것입니다.
베이지안 정리의 오른쪽에 있는 값 $p(D|\bf{w})$은 관측 데이터 집합 $D$를 바탕으로 계산됩니다. 이 값은 매개변수 벡터 $\bf{w}$의 함수로 볼 수 있으며, 가능도 함수(likelihood function)라고 불립니다. 가능도 함수는 각각의 다른 매개변수 벡터 $\bf{w}$에 대해 관측된 데이터 집합이 얼마나 '그렇게 나타날 가능성이 있었는지'를 표현합니다. 가능도 함수는 $\bf{w}$에 대한 확률 분포가 아니며, 따라서 $\bf{w}$에 대해 가능도 함수를 적분하여도 1이 될 필요가 없습니다.
가능도 함수에 대한 정의를 바탕으로 베이지안 정리를 다음처럼 적을 수 있습니다.
식 1.44
posterior = 사후 확률, likelihood = 가능도, prior = 사전 확률입니다.
식 1.44의 각 값은 전부 $\bf{w}$에 대한 함수입니다.
식 1.43 오른쪽 변의 분모는 식 왼쪽 변의 사후 분포가 적절한 확률 분포가 되고 적분 값이 1이 되도록 하기 위한 정규화 상수입니다. 식 1.43 오른쪽 변의 분모는 다음과 같이 구할 수 있습니다.
식 1.45
가능도 함수 $p(D|\bf{w})$는 베이지안 확률 관점과 빈도적 확률 관점 모두에게 굉장히 중요한 역할을 합니다. 하지만 가능도 함수가 사용되는 방식은 양 접근법에서 근본적으로 다릅니다.
먼저, 빈도적 확률 관점에서는 $\bf{w}$가 고정된 매개변수로 여겨지며, 그 값은 어떤 형태의 '추정 값'을 통해서 결정됩니다. 그리고 추정에서의 오류는 가능한 데이터 집합들 $D$의 분포를 고려함으로써 구할 수 있습니다.
이와는 대조적으로 베이지안 확률 관점에서는 오직 하나의 데이터 집합 $D$만이 존재하고 매개변수의 불확실성은 $\bf{w}$의 확률 분포를 통해 표현됩니다.
빈도적 확률 관점에서 널리 사용되는 추정 값 중 하나는 바로 최대 가능도(maximum likelihood)입니다. 최대 가능도를 사용할 경우에 $\bf{w}$는 가능도 함수 $p(D|\bf{w})$를 최대화하는 값으로 선택됩니다. 머신러닝 문헌에서는 종종 음의 로그 가능도 함숫값을 오차 함수(error function)이라고 합니다. 음의 로그 함수는 단조 감소하는 함수이기 때문에 가능도의 최댓값을 찾는 것이 오차를 최소화하는 것과 동일하기 때문입니다.
빈도적 확률론자들이 오차를 측정하는 방법 중 하나가 바로 부트스트랩(bootstrap) 방법입니다. 원 데이터 집합이 $N$개의 데이터 포인트 $X$ = {$\bf{x_1}, ..., \bf{x_N}$}이라고 가정해봅니다. $\bf{X}$에서 $N$개의 데이터 포인트를 임의로 추출하여 데이터 집합 $\bf{X_B}$를 만드는데, 이때 한번 추출된 값도 다시 추출 대상으로 고려될 수 있도록 하는 방식을 사용합니다. 즉 어떤 값은 중복될 수도 있고, 아예 포함되지 않을 수도 있습니다. 이 과정을 $L$번 반복하면 원래 데이터 집합의 표본에 해당하는 크기 $N$의 데이터 집합을 $L$개 만들 수 있습니다. 각각의 부트스트랩 데이터 집합에서의 예측치와 실제 매개변수 값과의 차이를 바탕으로 매개변수 추정 값의 통계적 정확도를 판단할 수 있습니다.
베이지안 관점의 장점 중 하나는 사전 지식을 추론 과정에 자연스럽게 포함시킬 수 있다는 점입니다. 예를 들어 멀쩡하게 생긴 동전 하나를 세 번 던졌는데, 세 번 다 앞면이 나왔다고 해봅시다. 고전적인 최대 가능도 추정을 통해 추론한다면 앞으로는 앞면이 나올 확률이 1일 것입니다. 미래의 모든 동전 던지기에서 앞면만 나올 것이라고 예측한다는 말입니다. 대조적으로 베이지안적으로 접근할 경우 적당히 합리적인 사전 확률을 사용한다면 이렇게까지 과도한 결론이 나오지는 않을 것입니다.
빈도적 확률 관점과 베이지안 확률 관점 중 어떤 것이 더 상대적으로 우수한지에 대해서는 끊임없는 논쟁이 있습니다. 베이지안 접근법에 대한 비판 중 하나는 사전 분포가 실제 사전의 믿음을 반영하기보다는 수학적인 편리성을 위해서 선택된다는 것입니다. 베이지안 관점에서는 사전 확률의 선택에 따라 결론이 나기 때문에 추론 과정에 주관이 포함될 수밖에 없습니다. 이 때문에 적절한 사전 확률을 선택하는 것이 어려운 경우도 있습니다. 사전 분포에 대한 의존도를 낮추기 위해 무정보적(noninformative) 사전 분포를 사용하는 경우도 있지만, 이는 서로 다른 모델을 비교하기 어렵게 만듭니다. 그리고 실제로 좋지 않은 사전 분포를 바탕으로 한 베이지안 방법은 부족한 결과물을 높은 확신으로 내놓기도 합니다.
1.2 확률론 내용이 많아서, 여기서 끊고 1.2.4 가우시안 분포부터 다음 글에서 다루도록 하겠습니다.
이번 내용은 다항 곡선 피팅에 대한 내용입니다. 즉, 데이터가 주어졌을 때 이를 잘 표현할 수 있는 다항 곡선을 만들어내는 것입니다.
실숫값의 입력 변수인 $x$를 관찰한 후 이 값을 바탕으로 실숫값인 타깃 변수 $t$를 예측하려 한다고 가정합니다.
예시에서 사용된 데이터는 $sin(2\pi{x})$ 함수를 사용하여 만들었으며, 타깃 변수에는 약간의 랜덤 노이즈를 포함했는데 이는 가우시안 분포 기반으로 표준편차 0.3을 사용하여 만들었습니다.
$N$개의 관찰값 $x$로 이루어진 훈련 집합 $\bf{x} \equiv$ $(x_1, ... x_N)^T$와 그에 해당하는 타깃 값 $\bf{t} \equiv$ $(t_1, ... t_N)^T$가 주어졌다고 생각해봅니다. 만약 N = 10이라면 다음과 같은 그림으로 표현할 수 있습니다.
그림 1.2 N = 10일 때 데이터 그림
입력 데이터 집합 $\bf{x}$는 서로 간에 같은 거리를 가지도록 균등하게 $x_n$값들을 선택해서 만들었다고 합니다.
우리가 패턴 인식 알고리즘을 통해 알아내고 싶은 실제 데이터 집합은 어떤 특정한 규칙성을 가지지만, 각각의 관찰 값들은 보통 랜덤한 노이즈에 의해 변질되곤 합니다. 이러한 노이즈는 본질적으로 확률적인 과정을 통해서 발생할 수 있으나, 더 많은 경우에는 관찰되지 않은 변수의 가변성에 기인한다고 합니다.
우리의 목표는 훈련 집합들을 통해 어떤 새로운 입력값 $\hat{x}$가 주어졌을 때 타깃 변수 $\hat{t}$를 예측하는 것입니다. 결국에는 기저에 있는 함수인 $sin(2\pi{x})$를 찾아내는 것이 예측 과정에 포함된다고 생각할 수 있습니다. 이는 한정적인 데이터 집합으로부터 일반화를 하는 과정이니 본질적으로 어려운 문제이며, 관측된 값이 노이즈에 의해 변질되어 있어서 더더욱 어려운 상황입니다.
곡선을 피팅하는데 있어서 다음과 같은 형태의 다항식을 활용합니다.
(식 1.1)
$M$은 다항식의 차수(order), 다항식의 계수인 $w_0, ... w_M$을 함께 모아서 벡터 $\bf{w}$로 표현할 수 있습니다. 다항 함수 $y(x, \bf{w}$$)$는 $x$에 대해서는 비선형이지만, 계수 $\bf{w}$에 대해서는 선형입니다. (선형이냐 아니냐는 1차 함수인지 아닌지를 생각해보시면 쉽습니다. 즉, $x$에 대해서는 2차, 3차... M차로 구성되지만, 계수인 $w_0$ 등은 차수가 1이기 때문에 선형이라고 부르는 것입니다. 계수를 기준으로 볼 때는 $x$는 실수 값처럼 생각해주시면 됩니다.)
우리가 식 1.1에서 정의한 다항식을 훈련 집합 데이터에 fitting해서 계수의 값들을 정할 수 있습니다. 훈련 집합의 타깃 값과 함숫값(다항식을 이용해서 예측한 값) $y(x, \bf{w}$$)$와의 오차를 측정하는 오차 함수(error function)를 정의하고 이 함수의 값을 최소화하는 방식으로 fitting 할 수 있습니다. 즉, 최대한 예측값이 실제 타깃 값과 가까워지게끔 하겠다는 것입니다. 가장 널리 쓰이는 간단한 오차 함수 중 하나는 식 1.2에서 보이는 것처럼 타깃 값과 함숫값 사이의 오차를 제곱해서 합산하는 함수를 사용합니다.
(식 1.2)
식 1.2의 함수에서 왜 갑자기 1/2이 추가되었나 라고 한다면, 추후 이 함수를 미분해야 하기 때문에 계산상으로 조금 더 편하게 하기 위해서 곱했다 정도로 생각해주시면 됩니다.(제곱 형태기 때문에, 미분 하면 2가 앞으로 나오게 되어 1/2를 상쇄하게 됩니다.) 해당 오차 함수는 결괏값이 0보다 크거나 같은 값이 나오게 되며, 오직 함수 $y(x, \bf{w}$$)$가 정확히 데이터 포인트들을 지날 때만 값이 0이 된다는 사실을 알 수 있습니다.
$E(\bf{w}$$)$를 최소화하는 $\bf{w}$를 선택함으로써 이 곡선 피팅 문제를 해결할 수 있으며, 식 1.2에서 주어진 오차 함수가 이차 다항식의 형태를 지니고 있으므로 이를 계수에 대해서 미분하면 $\bf{w}$에 대해 선형인 식이 나오게 됩니다. 이를 통해 오차 함수를 최소화하는 유일한 값인 $\bf{w}^*$를 찾아낼 수 있습니다.
아직 우리가 고려하지 않은 사항이 있습니다. 바로 다항식의 차수 $M$을 결정해야 합니다. 이 문제는 모델 비교(model comparison) 혹은 모델 결정(model selection)이라 불리는 중요한 내용입니다. 그림 1.4에서는 $M$ = 0, 1, 3, 9인 네 가지 경우에 대해 앞에서 언급한 데이터를 바탕으로 다항식을 피팅하는 예시를 보여줍니다.
그림 1.4 다양한 차수 M에 따른 곡선 피팅
우리가 피팅한 다항식은 빨간색으로, 실제 데이터에 사용된 기저 함수인 $sin(2\pi{x})$은 연두색으로, 데이터 포인트는 파란색 원으로 표시되어 있습니다.
여기서는 우리가 다항식의 차수를 어떻게 결정하는지에 따라 피팅된 곡선이 어떤 모습을 하게 되는지를 보시면 됩니다.
먼저 상수($M$ = 0)일 때와 1차($M$ = 1) 다항식을 사용할 때는 피팅이 잘 되지 않고 있는 모습을 확인할 수 있습니다. 이는 우리가 사용하려는 다항식이 너무 단순해서, 데이터 포인트를 충분히 표현하기에 어렵다는 것을 의미합니다. 책에는 이렇게 쓰여있지는 않지만, 모델의 복잡도가 낮다 라는 용어로도 표현합니다. 복잡도는 보통 영어로 complexity라고 표현하니 이 용어를 알아두시면 좋습니다.
3차($M$ = 3) 다항식의 경우는, 기저 함수를 잘 표현하고 있음을 확인할 수 있습니다.
차수를 더 높여 9차($M$ = 9) 다항식을 사용할 경우, 훈련 집합에 대한 완벽한 피팅이 가능합니다. 이 경우 피팅된 곡선이 모든 데이터 포인트를 지나가며 앞에서 정의한 오차 함수 기준으로 $E(\bf{w^*}$$) = 0$입니다. 하지만 피팅된 곡선은 심하게 진동하고 있고, 함수 $sin(2\pi{x})$를 적절하게 표현하지 못하고 있습니다. 이것이 바로 과적합(over-fitting)의 예시입니다.
앞에서 언급했듯이, 우리의 목표는 새로운 데이터가 주어졌을 때, 정확한 결괏값을 예측할 수 있는 좋은 일반화를 달성하는 것입니다. 따라서, 이러한 과적합을 피해야 합니다.
앞과 같은 과정을 사용하되, 랜덤한 노이즈 값만 다르게 적용해 100개의 새 데이터 포인트로 이루어진 시험 집합을 만들어 봅니다. 이 시험 집합에서의 성능을 확인해 보면 $M$의 값에 따라 일반화의 성능이 어떻게 변화하는지 정량적으로 살펴볼 수 있습니다.
훈련 집합과 시험 집합 각각에 대해서 평균 제곱근 오차(root mean square error, RMSE)를 이용해 일반화의 성능을 확인해봅시다. RMSE는 다음과 같이 정의됩니다.
(수식 1.3)
$N$으로 나눠 데이터 사이즈가 다른 경우에도 비교할 수 있으며, 제곱근을 취해 RMSE가 정답 값 $t$와 같은 크기를 가지게 됩니다.
각각의 $M$ 값에 대한 훈련 집합과 시험 집합의 RMSE를 그림 1.5에서 확인할 수 있습니다.
그림 1.5
$M$ 값이 작은 경우는 시험 오차가 상대적으로 큽니다. 즉 낮은 차수의 다항식은 비교적 융통성이 없어 피팅된 다항식이 기저인 함수를 충분히 표현할 수 없습니다.
$3 \leq M \leq 8$의 경우, 시험 집합의 오차가 작고 피팅된 해당 다항식이 기저인 함수를 충분히 잘 표현하고 있습니다.
$M = 9$일 경우는 훈련 집합의 오차가 0이지만, 시험 집합의 오차가 굉장히 큽니다.
차수 $M$에 따른 피팅 함수의 계수 $\bf{w}^*$의 값들을 적은 표 1.1도 한번 봅시다.
표 1.1
$M$이 커짐에 따라 계숫값의 단위 역시 커지는 것을 확인할 수 있습니다. 특히, $M = 9$ 다항식의 경우는 상당히 큰 양숫값의 계수와 음숫값의 계수가 번갈아 나타나는 것을 볼 수 있습니다. 이는 각각의 데이터 포인트에 정확하게 맞도록 피팅한 결과죠.
사용되는 데이터 집합의 크기가 달라지는 경우에는 어떤 일이 일어나는지 확인해 봅시다. 그림 1.6를 보면 이에 대해 생각해볼 수 있습니다.
그림 1.6
모델의 복잡도를 일정하게 유지시킬 때는 사용하는 데이터 집합의 수가 늘어날수록 과적합 문제가 완화되는 것을 확인할 수 있습니다. 이를 다르게 표현하면 데이터 집합의 수가 클수록 더 복잡한 모델을 활용하여 피팅할 수 있다는 의미도 됩니다.
비교적 복잡하고 유연한 모델을 제한적인 숫자의 데이터 집합을 활용하여 피팅하려면 어떻게 하는게 좋을까요?
과적합 문제를 해결하기 위해 자주 사용되는 기법 중 하나가 바로 정규화(regularization) 입니다. 기존의 오차 함수에 피팅 함수의 계수 크기가 커지는 것을 막기 위해 페널티항을 추가하는 것입니다. 이러한 페널티항 중 가장 단순한 형태는 각각의 계수들을 제곱하여 합하는 것이며, 이는 다음 식 1.4처럼 표현할 수 있습니다.
식 1.4
여기서 패널티항은 $\parallel w \parallel^2$ $\equiv$ $\bf{w}^T{w}$ = $w^2_0 + w^2_1 + .... w^2_M$이며, 여기서 사용된 계수 $\lambda$는 제곱합 오류항에 대한 상대적인 중요도를 결정합니다.
통계학 문헌들에서는 이 방법을 수축법(shrinkage method)라고 합니다. 방법 자체가 계수의 크기를 수축시키는 방식을 이용하기 때문이죠. 이차 형식(quadratic) 정규화는 리지 회귀(ridge regression)이라고 부릅니다. 딥러닝에서는 이를 가중치 감쇠(weight decay)라고 합니다.
그림 1.7을 보면 계수 $\lambda$의 값에 따른 $M = 9$ 다항식을 피팅한 결과를 확인할 수 있습니다.
그림 1.7
$ln\lambda$ = -18의 경우 과적합이 많이 줄어들었고, 그 결과 다항식이 기저 함수에 훨씬 더 가까워진 것을 확인할 수 있습니다. 하지만, 너무 큰 $\lambda$ 값을 사용하면 좋지 않은 피팅 결과를 가져옵니다. 이는 그림 1.7의 오른쪽 그림을 통해서 확인할 수 있습니다.
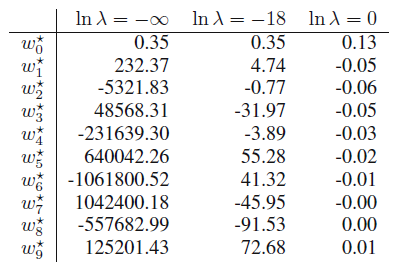
표 1.2에는 해당 피팅 다항식의 계숫값들이 나타나 있습니다.
표 1.2
$ln\lambda$ = $- \infty$ 인 경우는 $\lambda$ = 0인 경우이고, $ln\lambda$ = 0인 경우는 $\lambda$ = $e$인 경우입니다. 즉, 왼쪽에서 오른쪽으로 갈수록 $\lambda$가 더 커지는 것으로 이해할 수 있습니다.
확실히 $\lambda$가 커질수록, 정규화의 효과가 나타나는 것을 확인할 수 있습니다. 계수가 엄청나게 줄어들었죠.
그림 1.8에는 서로 다른 $ln\lambda$ 값에 따라서 훈련 집합과 시험 집합의 RMSE의 변화를 확인할 수 있습니다. $\lambda$가 모델의 복잡도를 조절해서 과적합 정도를 통제하는 것을 확인할 수 있습니다.
그림 1.8
지금까지의 내용을 정리해보면, 결국 오차 함수를 줄이는 방식으로 다항식을 피팅하는 경우에는 과적합 문제를 해결하기 위해서는 적합한 정도의 모델 복잡도를 선택하는 방법을 잘 활용해야 한다는 것입니다.
지금까지의 결과를 바탕으로 모델 복잡도를 잘 선택하는 단순한 방법 하나를 생각해 볼 수 있는데, 이는 바로 데이터 집합을 훈련 집합(training set)과 검증 집합(validation set, hold-out set)으로 나누는 것입니다.
훈련 지합은 계수 $\bf{w}$를 결정하는 데 활용하고, 검증 집합은 모델 복잡도($M$나 $\lambda$)를 최적화하는 데 활용하는 방식입니다. 하지만 많은 경우에 이 방식은 소중한 훈련 집합 데이터를 낭비하게 됩니다. 따라서 더 좋은 방법을 고려할 필요가 있습니다.
지금까지 다항 곡선을 피팅하는 문제에 대해서 논의해보았으며, 다음 절에서는 확률론에 대해서 살펴보도록 합니다.
1.1절 간단하게 정리
- 데이터를 잘 표현하기 위해서, 오차 함수를 정의하고 오차 함수가 최소가 되는 가중치 $\bf{w}$를 결정합니다.
- 이 때, 적절하게 다항 함수의 차수와 가중치의 크기를 조절해야만 과적합이 일어나지 않습니다. 주로 정규화를 이용해서 이를 조절할 수 있습니다.
Pattern Recognition and Machine Learning(a.k.a PRML)에 도전하고자 합니다.
하다가 너무 바빠지면 또 뒷전이 될 것 같지만....(그냥 혼자 읽는 것에 비해 글을 작성하려면 시간이 배로 들기 때문에 바빠지면 손을 놓게 되는 것 같습니다...)
예전에 자연어 처리 책 정리했듯이 내용을 정리하면서, 최대한 읽으시는 분들에게 도움이 되는 방향으로 작성하려고 합니다.
이번 글은 PRML의 Chapter 1의 Prologue를 정리해볼까 합니다.
내용도 짧고 어려운 건 없지만, 처음 글인 만큼 가볍게 작성하면서 시작해보겠습니다.
PRML - Chapter 1. (0) Prologue
주어진 데이터에서 어떤 특정한 패턴을 찾아내는 것은 아주 중요한 문제로, 이 문제에 대해서 인류는 오랜 시간 동안 답을 찾아왔습니다. 이에 대한 예시로는 케플러의 행성 운동 법칙이나, 원자 스펙트럼의 규칙성 같은 것들이 있죠.
이처럼 패턴 인식은 컴퓨터 알고리즘을 통해 데이터의 규칙성을 자동적으로 찾아내고, 이 규칙성을 이용해 데이터를 각각의 카테고리로 분류하는 등의 일을 하는 분야입니다.
그림 1. MNIST Data
그림 1은 MNIST Data의 일부를 나타내고 있는데요. (아마 딥러닝이나 머신러닝을 조금이라도 해보셨다면 MNIST가 무엇인지는 아실 것이라고 생각합니다.) 28 x 28 픽셀 이미지로 구성되어 있고, 이런 이미지 1개를 입력받았을 때 숫자 0부터 9 중에서 어떤 값을 나타내는지를 출력하는 모델을 만드는 것이 패턴 인식의 예시라고 볼 수 있습니다.
데이터를 바탕으로 Rule을 만들어 문제를 해결할 수도 있지만 그렇게 하려면 수많은 규칙이 필요해지고 예외 사항도 필요하며 이렇게 하려고 했을 때는 결과적으로 좋지 못한 성능을 내게 됩니다.
이럴 때 머신 러닝은 훨씬 더 좋은 결과를 낼 수 있습니다. 이는 N개의 숫자들 {$x_1, x_2, ... x_N$}을 훈련 집합(Training set)으로 활용해 변경 가능한 모델의 매개변수(Parameter)를 조절하는 방법입니다. 훈련 집합에 있는 숫자들의 카테고리(정답, Label)는 미리 주어지게 되며 이를 표적 벡터(target vector) $t$로 표현할 수 있습니다. 각각의 숫자 이미지 $x$에 대한 표적 벡터 $t$는 하나입니다.
머신러닝 알고리즘의 결과물은 함수 $y(x)$로 표현할 수 있으며, 이는 새로운 숫자의 이미지 $x$를 입력값으로 받았을 때 해당 이미지의 정답인 $y$를 출력하는 함수입니다. 함수 $y(x)$의 정확한 형태는 훈련 단계(training phase)에서 훈련 집합을 바탕으로 결정되며, 훈련이 되고 나서 내가 알고 싶은 새로운 숫자 이미지들의 집합(시험 집합 - test set)의 정답을 찾아내는 데 활용할 수 있습니다. 훈련 단계에서 사용되지 않았던 새로운 예시들을 올바르게 분류하는 능력을 일반화(Generalization) 성능이라고 합니다. 실제 application에서는 입력 벡터의 변동이 커 훈련 데이터는 가능한 모든 케이스들 중에서 일부분만 커버할 수 있기 때문에, 패턴 인식에서의 가장 중요한 목표는 바로 일반화입니다. 즉, 학습 단계에서 본 적 없는 데이터에 대해서도 정답을 잘 맞춰야 한다는 얘기입니다.
많은 application에서 입력 변수들을 전처리(Preprocessing)하여 새로운 변수 공간으로 전환하게 되는데, 이를 통해 패턴 인식 문제를 더 쉽게 해결할 수 있습니다. 이를 통해 입력의 가변성을 상당히 줄여 패턴 인식 알고리즘이 각 클래스를 구별해 내기 더 쉽게 만들 수 있습니다. 이러한 전처리 과정은 특징 추출(feature extraction) 이라고도 불리며, 훈련 집합에서 전처리 과정을 적용했다면 시험 데이터에도 동일하게 적용해야 합니다.
혹은 계산 속도를 높이기 위해서 전처리 과정을 활용하기도 합니다. 예를 들면 데이터가 높은 해상도의 비디오 데이터를 실시간으로 처리해야 하는 경우라면 굉장히 연산량이 많을 것입니다. 따라서 모든 데이터를 다 사용하는 것 대신, 차별적인 정보(discriminatory information)를 가지고 있으면서 동시에 빠르게 계산하는 것이 가능한 유용한 특징(useful feature)들을 찾아내어 사용할 수도 있을 것입니다. 이러한 특징들은 기존 데이터보다 픽셀 수가 적기 때문에, 이러한 종류의 전처리를 차원 감소(dimensionality reduction) 이라고 하기도 합니다. 하지만, 전처리 과정에서는 주의를 기울여야 합니다. 왜냐하면 많은 전처리 과정에서 정보들을 버리게 되는데, 만약 버려진 정보가 문제 해결에 중요한 특징이었을 경우는 성능면에서 큰 타격을 받을 수 있기 때문입니다.
주어진 훈련 데이터가 입력 벡터와 그에 해당하는 표적 벡터로 이루어지는 문제를 지도 학습(supervised learning) 문제 라고 합니다. MNIST 예시처럼, 각 입력 벡터를 제한된 숫자의 카테고리 중 하나에 할당하는 종류의 문제는 분류(classification) 문제라고 하고, 출력 값이 하나 또는 그 이상의 연속된 값을 경우에는 회귀(Regression) 문제라고 합니다. 예를 들어서 반응 물질의 농도, 온도, 압력이 주어졌을 때 화학반응을 통해 얼마나 산출될 것인지를 예측하는 것이 회귀 문제의 예시가 됩니다.
훈련 데이터가 표적 벡터 없이 오직 입력 벡터 $x$로만 주어지는 경우의 패턴 인식 문제는 비지도 학습(unsupervised learning) 문제라고 합니다. 데이터 내에서 비슷한 예시들의 집단을 찾는 집단화(Clustering) 문제, 입력 공간에서의 데이터 분포를 찾는 밀도 추정(Density estimation), 높은 차원의 데이터를 2차원 또는 3차원에 투영하여 이해하기 쉽게 만들어 보여 주는 시각화(Visualization) 등이 비지도 학습 문제의 예시입니다.
마지막으로, 강화 학습(Reinforcement learning)이라는 테크닉도 있습니다. 강화 학습은 지도 학습, 비지도 학습과는 살짝 다른데, 주어진 상황에서 보상을 최대화하기 위한 행동을 찾는 문제를 푸는 방법입니다. 강화 학습은 지도 학습의 경우와 달리 학습 알고리즘에 입력값과 정답 값을 주지 않습니다. 강화 학습은 시행착오를 통해서 보상을 최대화하기 위한 행동을 찾게 되며, 알고리즘이 주변 환경과 상호 작용할 때 일어나는 일들을 표현한 연속된 상태(State)와 행동(Action)들이 문제의 일부로 주어지게 됩니다. 강화 학습의 적절한 예시로는 게임을 생각할 수 있는데, 다음과 같은 게임을 생각해보도록 하겠습니다.
그림 2. Breakout
위 그림은 Breakout 이라고 하는 게임의 화면을 나타내고 있습니다. 게임의 이름은 처음 들어보실 수 있지만 아마 어떤 게임인지는 짐작이 가실 것입니다. 밑에 있는 막대기를 왼쪽에서 오른쪽으로 옮기면서 떨어지는 공을 받고, 공은 막대기에 튕기면서 위에 있는 색깔이 있는 벽돌을 부수는 그런 게임입니다. 벽돌을 부수게 되면 보상(Reward) - 아마 해당 게임에서는 점수를 받게 될 것이고, 결국 이 게임의 목표는 최대의 보상을 받을 수 있는 막대기의 움직임을 결정하는 것입니다. 즉, 공이 위에 있는 벽돌을 부수고 아래로 떨어질 때, 플레이어는 적절하게 노란색 막대기를 이동시켜 바닥으로 떨어지지 않도록 해야 합니다. 이는 수백만, 수천만 번 이상의 게임을 수행하면서 강화 학습 알고리즘이 어떤 상황에서는 어떤 행동을 취하는 것이 최적 일지를 학습하게 됩니다. 이 게임에서 State는 게임 화면이 될 것이고, Action은 노란색 막대기를 어떻게 이동할 것인지(왼쪽으로 혹은 오른쪽으로 얼마큼 이동할 것인지, 혹은 가만히 있을 것인지)를 결정하는 것이며, Reward는 벽돌을 깨서 얻게 되는 점수가 될 것입니다.
그리고 강화 학습에는 탐사(exploration)와이용(exploitation) 간의 trade-off가 있습니다. Exploitation은 강화 학습 알고리즘이 높은 보상을 주는 것으로 판단한 행동을 시행하게 되는 것을 의미하며, Exploration은 이 행동을 하는 것이 아닌 새로운 종류의 행동을 시도해보는 것을 말합니다. Exploitation만 하게 되면 많은 상황을 경험하지 못하게 되어 더 좋은 행동을 취할 가능성을 잃게 되며, Exploration만 하는 것은 최적의 행동을 취하지 않는 것이므로 좋지 않은 결과를 가져오게 됨을 예상할 수 있습니다. 따라서, 강화 학습은 exploration과 exploitation을 적절하게 잘 섞어서 학습을 진행하게 됩니다. 이 책에서도 강화 학습을 자세히 다루지는 않기 때문에 이 정도로만 적으면 될 것 같습니다.
지금까지 소개한 각각의 알고리즘을 해결하는 데는 서로 다른 방법과 기술이 필요하지만, 핵심에 속하는 중요 아이디어는 서로 겹칩니다. Chapter 1의 주요 목표 중 하나는 예시를 통해 이 중요 아이디어에 대해 비교적 간단하게 설명해 보는 것입니다. 해당 Chaper에서는 앞으로의 내용들을 다루는데 필요한 세 가지 중요한 도구인 확률론, 의사 결정 이론, 정보 이론에 대해서 설명합니다.
사실 Chapter 1.3까지는 본 상황인데, 역시 책의 난이도가 쉽지는 않습니다. 그래도 확실히 책을 읽으면서 느낀 점은, 사람들이 추천하는 데는 이유가 있다는 점입니다. 적은 내용을 봤음에도 내용 자체가 워낙 탄탄하고 알차서 좋다고 느껴집니다. 아무튼, 이어서 계속 가보도록 하겠습니다. 다음 Chapter 1.1 파트에서 뵙겠습니다.