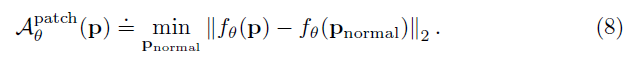안녕하세요.
오늘은 Anomaly Detection and Segmentation(Localization)에서 MVTec AD dataset 기준 얼마 전까지 SOTA였던 모델인 PaDiM을 소개해볼까 합니다.
원래는 SOTA였지만, 현재는 PatchCore라는 모델이 SOTA를 찍으면서 현재는 성능 기준 2위인 모델입니다.(2021/07/11 기준)
논문의 주소는 다음과 같습니다.
https://arxiv.org/abs/2011.08785
PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization
We present a new framework for Patch Distribution Modeling, PaDiM, to concurrently detect and localize anomalies in images in a one-class learning setting. PaDiM makes use of a pretrained convolutional neural network (CNN) for patch embedding, and of multi
arxiv.org
그럼 시작해보겠습니다.
Abstract
저자들은 본 논문에서 one-class learning setting일 때 이미지 내에서 anomaly를 검출하면서 동시에 위치를 찾아내고자 Patch Distribution Modeling을 위한 새로운 framework를 제시합니다.
PaDiM은 patch embedding을 위해서 pretrained convolutional neural network를 사용하고, normal class의 확률적 representation을 얻고자 multivariate Gaussian distribution을 활용합니다.
이는 anomaly의 위치를 더 잘 찾기 위해 CNN의 다양한 semantic level 사이의 correlation 또한 사용할 수 있게 해 줍니다.
PaDiM은 MVTec AD와 STC dataset에 대해서 anomaly detection과 localization 모두 현재 SOTA보다 더 나은 성능을 나타냅니다.
실제 산업 현장에서 이루어지는 inspection과 유사한 환경을 만들기 위해, 저자들은 anomaly localization algorithm의 성능을 평가하는 evaluation protocol을 non-aligned data로 확장하는 결과도 보여줍니다.
1. Introduction
사람은 동질의 자연스러운 이미지의 집합에서 이질적이거나 예상하지 못한 패턴을 검출할 수 있는데, 이러한 task는 anomaly detection 혹은 novelty detection이라고 알려져 있습니다.
하지만 제조 공정에서 anomaly는 매우 드물게 발생하며, 이를 수동으로 검출하는 것은 힘든 일입니다.
그러므로, anomaly detection automation은 사람 작업자의 작업을 촉진함으로써 지속적인 품질 관리를 가능하게 해 줍니다.
본 논문에서 저자들은 주로 산업 검사 상황에서의 anomaly detection과 anomaly localization에 초점을 둡니다.
Computer vision에서, anomaly detection은 이미지에 anomaly score를 매기는 것으로 이루어져 있습니다.
Anomaly localization은 각 픽셀이나, 혹은 픽셀들의 각 패치에 anomaly score를 assign 해서 anomaly map을 산출하는 더욱 복잡한 task입니다.
따라서, anomaly localization은 더욱 정확하고 해석 가능한 결과를 만들어내게 됩니다.
저자들의 방법론을 통해 만들어진 anomaly map의 MVTec Anomaly Detection (MVTec AD) dataset에서의 예시는 Figure 1에서 확인할 수 있습니다.

Anomaly detection은 normal class와 anomalous class 사이의 binary classification입니다.
하지만, anomalous examples가 자주 부족하고, 더욱이 anomalies는 예기치 않은 패턴을 가질 수 있기 때문에 anomaly detection을 위한 모델을 full supervision으로 학습시킬 수 없습니다. (supervised learning이 불가능하다 정도로 이해하시면 됩니다. 상대적으로 anomaly image를 구하기 어렵기 때문이죠.)
그러므로, anomaly detection model들은 one-class learning setting에서 추정됩니다.
즉, 학습하는 동안 anomalous examples는 사용할 수 없으며 training dataset은 오직 normal class에서 나온 이미지만 포함합니다.
Test time일 때, normal training dataset과는 다른 examples이 anomalous로 분류됩니다.
최근에, one-class learning setting에서 anomaly localization과 detection task를 결합하기 위해 여러 방법론들이 제안되어 왔습니다.
하지만, 이러한 방법론들은 다루기 힘든 deep neural network training을 필요로 하거나, test time에서 전체 training dataset에 대해 K-nearest-neighbor (KNN) algorithm을 사용합니다.
KNN algorithm의 시간 복잡도와 공간 복잡도는 training dataset의 크기가 증가함에 따라 증가하게 됩니다.
이러한 두 확장성 문제(1. 다루기 힘든 DNN 학습을 필요로 함, 2. KNN algorithm의 사용)는 산업 현장에서 anomaly localization algorithm을 사용되는 것을 어렵게 만듭니다.
앞에서 언급된 문제들을 완화하고자, 저자들은 PaDiM이라고 부르는 새로운 anomaly detection and localization approach를 제안합니다.
이는 pretrained convolutional neural network (CNN)을 embedding extraction에 사용하고, 다음 두 가지 특성을 가집니다.
- 각 patch position은 multivariate Gaussian distribution으로 표현됩니다.
- PaDiM은 pretrained CNN의 다른 semantic level 간의 correlation을 고려합니다.
이러한 새롭고 효율적인 접근법을 이용해, PaDiM은 MVTec AD와 ShanghaiTech Campus (STC) dataset에 대해서 anomaly localization과 detection의 현재 SOTA method보다 더 좋은 성능을 냅니다.
게다가, test time에서 PaDiM은 낮은 시간 복잡도와 공간 복잡도를 가지며 training dataset size와 독립적입니다.
저자들은 또한 non-aligned dataset과 같은 보다 현실적인 조건에서의 model performance를 평가하기 위해 evaluation protocol을 확장하였습니다.
2. Related work
Anomaly detection과 localization methods는 reconstruction-based나 embedding similarity-based methods로 분류될 수 있습니다.
2.1 Reconstruction-based methods
Reconstruction-based methods는 anomaly detection과 localization에서 널리 사용되는데요.
Autoencoder (AE)와 같은 Neural network architectures, variational autoencoders (VAE), 혹은 generative adversarial networks (GAN)는 오직 normal training image만 복원하도록 학습됩니다.
그러므로, anomalous image는 잘 복원되지 않기 때문에 검출될 수 있습니다.
Image level에서, 가장 간단한 접근법은 reconstructed error를 anomaly score로 사용하는 것이나, latent space나 intermediate activation, 혹은 discriminator로부터 얻을 수 있는 추가적인 정보는 anomalous image를 더 잘 파악하는데 도움을 줄 수 있습니다.
Anomalies의 위치를 파악하기 위해서, reconstruction-based methods는 pixel-wise reconstruction error나 structural similarity를 anomaly score로 사용할 수 있습니다.
비록 reconstruction-based methods가 매우 직관적으로 해석 가능하지만, AE가 때때로 anomalous image에 대해서도 좋은 reconstruction results를 만들어낼 수 있다는 사실에 의해 이들의 성능은 제한적입니다.
2.2 Embedding similarity-based methods
Embedding similarity-based methods는 anomaly detection을 위한 전체 이미지나 anomaly localization을 위한 이미지 패치를 묘사하는 meaningful vector를 추출하는 deep neural network를 사용하게 됩니다.
Anomaly detection만을 수행하는 embedding similarity-based methods는 유망한 결과를 내고 있으나 anomalous image의 어떤 부분이 높은 anomaly score에 대해 기여하고 있는지를 아는 것이 불가능하므로 해석 가능성이 부족한 경우들이 있습니다.
이러한 경우에 anomaly score는 training dataset으로부터 얻어지는 reference vector와 test image의 embedding vector 사이의 distance가 됩니다.
Normal reference는 normal image로부터의 embeddings, Gaussian distribution의 parameters, 혹은 normal embedding vector의 전체 집합을 포함하는 n-sphere의 중심이 될 수 있습니다.
마지막 option은 anomaly localization에서 가장 좋은 성능을 낸 SPADE에서 사용되었습니다.
하지만, 이는 test time에서 normal embedding vector의 집합에 K-NN algorithm을 실행하게 되며 이는 training dataset size에 따라 선형적으로 inference 복잡도를 증가하게 만듭니다.
이는 해당 방법을 산업 현장에서 사용하기 어렵게 만듭니다.
저자들의 방법론인 PaDiM은 앞에서 언급된 접근법들과 유사하게 anomaly localization을 위한 patch embedding을 만들어냅니다.
하지만, PaDiM에서 normal class는 pretrained CNN model의 semantic level 간 correlation을 모델링하는 일련의 Gaussian distribution을 통해 묘사됩니다.
이전 연구에서 영감을 받아, 저자들은 ResNet, Wide-ResNet, EfficientNet과 같은 pretrained networks를 선택하였습니다.
PaDiM은 현재 SOTA method보다 더 좋은 성능을 내며, 시간 복잡도는 낮고 예측 단계에서 training dataset size와 독립적입니다.
3. Patch Distribution Modeling
3.1 Embedding extraction
Pretrained CNN은 anomaly detection을 위해 관련 있는 특징들을 뽑아낼 수 있습니다.
그러므로, 저자들은 patch embedding vector를 만들기 위해서 오직 pretrained CNN을 사용함으로써 다루기 힘든 neural network optimization을 회피하는 것을 선택하였습니다.
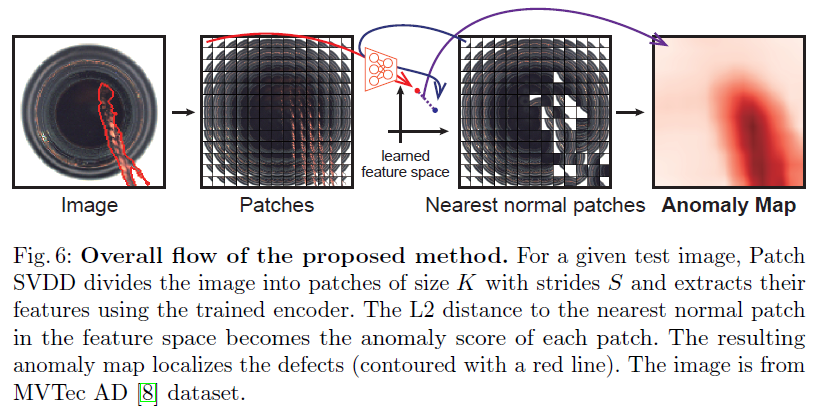
PaDiM에서의 patch embedding process는 SPADE에서와 유사하며, Figure 2에서 확인할 수 있습니다.
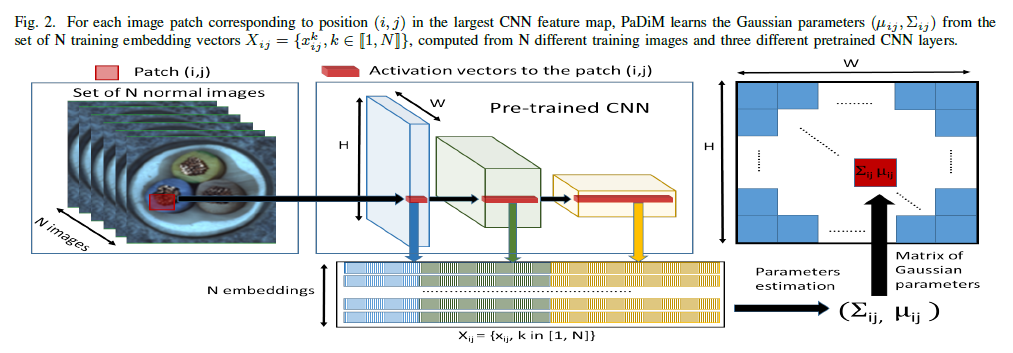
학습 phase 동안에, normal image의 각 patch는 pretrained CNN activation map에서 공간적으로 대응되는 activation vector와 연관됩니다. (예를 들어서, 원래 이미지는 224x224이고 위 그림에서 Pre-trained CNN의 맨 왼쪽 파란색 activation vector는 ResNet18 기준으로 56x56가 되는데요. 이는 원래 이미지의 4x4 만큼의 Patch가 activation vector에서 1x1이 된다고 생각할 수 있습니다.)
Fine-grained and global context를 encoding 하기 위해서, 다른 semantic level과 resolution으로부터의 정보를 가지고 있는 embedding vector를 얻고자 다른 layers로부터의 activation vector는 concatenated 됩니다.(위 Figure 2에서 파란색 embedding과 녹색 embedding, 노란색 embedding을 모두 합친다는 의미라고 이해해주시면 됩니다.)
Activation maps가 input image보다 더 낮은 resoltuion을 가지기 때문에 많은 pixel들은 동일한 embeddings를 가지게 되며, original image resolution에서 어떠한 overlap도 없는 pixel patch를 형성하게 됩니다. (앞에서 설명드린 224x224가 56x56이 되는 것을 생각해보시면 별도로 overlap 되는 것 없이 작업이 된다는 것을 이해하실 수 있을 것이라고 생각합니다.)
그러므로, input image는 $(i, j) \in [1, W] \times [1, H]$의 grid로 분할될 수 있으며, $W \times H$는 embeddings를 만들어낼 때 사용된 가장 큰 activation map의 resolution을 나타냅니다.
마지막으로, 이러한 grid에서의 각 patch position $(i, j)$는 위에서 묘사된 것처럼 계산된 embedding vector $x_{ij}$와 관련이 있습니다.
생성된 patch embedding vector가 중복된 정보를 가질 수 있기 때문에, 저자들은 이들의 사이즈를 줄이기 위한 가능성을 실험적으로 연구했는데요.
저자들은 고전적인 PCA를 통해 임의로 몇몇 차원만을 선택하는 것이 더욱 효율적이라는 것을 알게 되었습니다.
이러한 단순한 random dimensionality reduction은 SOTA performance를 유지하면서도 training and testing time 둘 다에서의 model의 복잡도를 상당히 감소시키게 됩니다.
마지막으로, test image에서의 patch embedding vector는 다음 subsection에서 설명하는 대로 normal class의 학습된 parametric representation을 가지고 anomaly map을 만들어내는 데 사용됩니다.
3.2 Learning of the normality
위치 $(i, j)$에서의 normal image 특성을 학습하기 위해, 저자들은 첫 번째로 N개의 normal training image로부터 $(i, j)$에서의 patch embedding vector의 집합 $X_{ij} = \left\{x^k_{ij}, k \in [1, N]\right\}$를 계산합니다.
이 집합으로부터 얻어지는 정보를 요약하기 위해, 저자들은 $X_{ij}$가 multivariate Gaussian distribution $\mathcal{N}(\mu_{ij}, \Sigma_{ij})$에 의해서 생성되었다는 가정을 만들었으며, $\mu_{ij}$는 $X_{ij}$의 sample mean이고, sample covariance $\Sigma_{ij}$는 다음과 같이 추정됩니다.

Regularization term인 $\epsilon I$는 sample covariance matrix $\Sigma_{ij}$가 full rank이고 invertible 하게 만들어줍니다.
마지막으로, 각각의 가능한 patch position은 Gaussian parameter의 matrix에 의해서 Figure 2에서 나타나듯이 multivariate Gaussian distribution과 관련됩니다.
저자들의 patch embedding vector는 다른 semantic level로부터의 information을 포함하고 있습니다.
(이미 알려져 있는 것처럼, CNN의 각 layer는 각자 다른 수준의 특징을 잡아내게 됩니다. 해당 모델에서는 3개의 layer에서 embedding vector를 뽑아내므로, 각 embedding vector는 각자 다른 수준의 특징을 잡아낸다고 볼 수 있습니다.)
그러므로, 추정된 multivariate Gaussian distribution $\mathcal{N}(\mu_{ij}, \Sigma_{ij})$ 각각은 다른 level로부터의 information을 포착하고 있으며 $\Sigma_{ij}$는 inter-level correlation을 포함하게 됩니다.
저자들은 pretrained CNN의 다른 semantic level 사이의 관계를 모델링하는 것이 anomaly localization performance를 증가시키는데 도움이 준다는 사실을 실험적으로 보였습니다.
3.3 Inference: computation of the anomaly map
다른 논문들에서 영감을 받아, 저자들은 test image의 $(i, j)$에 있는 patch에 대해서 anomaly score를 만들어내고자 Mahalanobis distance $\mathcal{M}(x_{ij})$를 사용하였습니다.
$\mathcal{M}(x_{ij})$는 test patch embedding $x_{ij}$와 학습된 distribution $\mathcal{N}(\mu_{ij}, \Sigma_{ij})$간 거리로 해석될 수 있으며, $\mathcal{M}(x_{ij})$는 다음과 같이 계산됩니다.

따라서, Mahalanobis distance의 matrix인 $\mathcal{M} = (\mathcal{M}(x_{ij}))_{1<i<W, 1<j<H}$는 계산되는 anomaly map을 형성하게 됩니다.
(동일한 좌표 $(i, j)$에 대해서, 학습된 평균과 공분산을 통해 각 test image의 $(i, j)$위치에 대해 계산하게 되면 해당 test image의 각 좌표 $(i, j)$가 normal distribution과 비교했을 때 얼마나 차이가 많이 나는지를 계산할 수 있게 됩니다.)
이 map에서 높은 점수는 anomalous areas를 나타내게 됩니다.
전체 이미지의 최종 anomaly score는 anomaly map $\mathcal{M}$의 maximum 값이 됩니다.
마지막으로, test를 진행할 때, 저자들의 방법론은 patch의 anomaly score를 얻기 위해서 많은 양의 distance value를 계산하고 정렬할 필요가 없으므로 K-NN 기반의 방법론의 확장성 이슈를 가지고 있지 않습니다.
4. Experiments
4.1 Datasets and metrics
저자들은 첫 번째로 모델을 one-class learning setting에서 industrial quality control을 위한 anomaly localization algorithm을 테스트하기 위해 설계된 MVTec AD dataset에 평가하였습니다.
이는 대략 240개의 이미지로 구성된 15개의 클래스를 포함하며, 이미지의 resolution은 700x700부터 1024x1024로 다양하게 존재합니다.
여기에는 10 object class와 5 texture class가 있습니다.
Objects는 항상 well-centered이며, Transistor와 Capsule 클래스를 묘사한 Figure 1에서 볼 수 있듯이 dataset 전반에 걸쳐 동일한 방식으로 정렬되어 있습니다.
원래 dataset에 추가해서, 더 현실적인 상황에서의 anomaly localization model의 성능을 평가하고자, 저자들은 MVTec AD의 modified version인 Rd-MVTec AD라는 것을 만들었습니다.
이는 train과 test dataset 모두 (-10, +10)의 random rotation을 적용하였고, 256x256에서 224x224로 random crop을 진행하였습니다.
MVTec AD의 수정된 버전은 이미지 내에서 관심 있는 사물이 항상 중심에 있지 않고 정렬되어 있지 않은 상황에서의 quality control의 anomaly localization의 케이스를 더욱 잘 묘사할 것입니다.
Localization performance를 평가하기 위해, 저자들은 두 가지 threshold와 독립적인 metrics를 사용하였습니다.
저자들은 Area Under the Receiver Operating Characteristic curve (AUROC)를 사용하였는데, 여기서 true positive rate는 이상이 이상으로 올바르게 분류된 pixel의 비율을 나타냅니다.
AUROC가 large anomalies에 편향되기 때문에, 저자들은 per-region-overlap score (PRO-score) 또한 사용하였습니다.
(논문에는 PRO score에 대한 정보가 없어서, 다른 논문에서 발췌하여 추가합니다.)

(출처: Image Anomaly Detection Using Normal Data Only by Latent Space Resampling)
(Ground truth map과 비교했을 때 predicted segmentation map이 얼마나 많이 맞췄는지를 나타내는 것 같습니다. )
추가적인 평가를 위해서 PaDiM을 영상 데이터셋인 Shanghai Tech Campus (STC) Dataset에도 테스트를 진행했습니다.
이는 13개의 장면으로 나눠진 274,515 training frame과 42,883 test frame으로 구성되어 있고, 이미지 resolution은 856x480로 구성됩니다.
Training video는 normal sequence로만 구성되어 있고, test video에는 사람이 싸우거나 보행자 지역에서 vehicle이 등장하는 anomaly가 포함되어 있습니다.
4.2 Experimental setups
저자들은 PaDiM을 ResNet18(R18), Wide ResNet-50-2 (WR50), EfficientNet-B5의 다른 backbone을 사용하여 학습시켰으며, 모두 ImageNet에 pretrained 되었습니다.
다른 논문처럼, patch embedding vector는 ResNet backbone인 경우에 localization task를 위해 충분히 큰 resolution을 유지하면서 다른 semantic level로부터의 정보를 결합하고자 첫 번째 3개의 layer로부터 추출하였습니다.
이러한 아이디어를 유지하면서, EfficientNet-B5를 사용한 경우에 patch embedding vector를 layers 7(level 2), 20 (level 4), 26 (level 5)로부터 추출하였습니다.
저자들은 또한 random dimensionality reduction (Rd)을 적용하였습니다.
그리고 Equation 1에서 사용된 $\epsilon$에는 0.01의 값을 사용하였습니다.
MVTec AD에 있는 이미지들은 256x256로 resize 한 후, 224x224로 center crop을 진행하였습니다.
저자들은 localization map을 bicubic interpolation을 사용해서 만들어냈으며, anomaly map에 대해서 parameter $\sigma = 4$를 적용하는 Gaussian filter를 사용하였습니다.
5. Results
5.1 Ablative studies
첫 번째로, 저자들은 PaDiM에서의 semantic levels 간의 correlation을 모델링하는 것의 영향을 평가하였고, dimensionality reduction을 통해 본 논문에서 제안하는 방법론을 더욱 단순화시킬 가능성을 연구하였습니다.
Inter-layer correlation.
Gaussian modeling과 Mahalanobis distance의 결합은 이미 image level에서의 anomaly detection과 adversarial attack을 탐지하기 위한 이전 연구들에서 사용되어 왔습니다.
하지만, 이러한 방법론들은 PaDiM에서 한 것처럼 다른 CNN의 semantic levels 간의 correlation을 모델링하지는 않았습니다.
Table I에서, 저자들은 ResNet18 backbone을 사용하는 PaDiM의 MVTec AD에서의 anomaly localization performance를 보여주는데, 첫 번째 3개의 layer (Layer 1, Layer 2, Layer 3) 중에서 하나만 사용했을 때와 이러한 세 개의 model의 output을 가지고 첫 번째 3개의 layer를 고려하지만 이들 간 correlation은 고려하지 않는 ensemble method를 형성하고자 더했을 때의 결과를 보여줍니다.

Table I의 마지막 행은 ResNet18의 처음 3개의 layer와 이들 간 correlation을 고려하는 하나의 Gaussian distribution에 의해 각 patch location이 묘사되는 PaDiM을 나타냅니다.
단일 Layer만 사용하는 결과 중에서는, Layer 3을 사용하는 것이 3개의 레이어 중에서 AUROC 기준으로 가장 좋은 결과를 만들어낸다는 사실을 확인할 수 있습니다.
이는 정상성을 더 잘 묘사하는데 도움을 줄 수 있는 높은 수준의 semantic level information을 Layer 3이 포함하고 있다는 사실 때문으로 보입니다.
Output을 단순히 더한 model인 Layer 1+2+3와는 다르게, 저자들이 제안하는 PaDiM-R18은 semantic level 간 correlation을 고려하게 되는데요.
그 결과로, 이는 Layer 1+2+3에 비해서 더 좋은 결과를 나타내는 것을 확인할 수 있습니다.
이는 semantic level 간 correlation을 모델링하는 것의 적절성을 보여줍니다.
Dimensionality reduction
PaDiM-R18은 448차원의 patch embedding의 집합에서 multivariate Gaussian distribution을 추정하게 됩니다.
Embedding vector size를 감소시키는 것은 모델의 공간 복잡도와 계산 복잡도를 줄일 수 있기 때문에, 저자들은 두 가지의 다른 dimensionality reduction method를 연구하였습니다.
첫 번째로는 Principal Component Analysis (PCA) algorithm을 사용해서 vector size를 100차원이나 200차원으로 줄이는 것이고, 두 번째는 학습하는 동안에 임의로 선택된 feature를 가지고 random feature selection을 진행하는 것입니다.
이 경우에, 저자들은 10개의 다른 모델을 학습시키고, 평균 점수를 취하는 방식으로 실험을 진행하였습니다.

Table II를 살펴보면, 같은 수의 차원에 대해서 random dimensionality reduction (Rd) 방식이 PCA에 비해서 모든 클래스에 대해 더 좋은 성능을 내는 것을 확인할 수 있었습니다.
이는 PCA가 anomalous class로부터 normal class를 분류하는데 도움이 되지 않을 수 있는 가장 높은 분산을 가지는 dimension을 선택한다는 사실로 설명될 수 있습니다.
그리고 임의로 embedding vector size를 100차원으로 줄였을 때도 anomaly localization performance에는 매우 작은 영향을 준다는 사실을 확인할 수 있습니다.
이렇게 간단하면서도 효율적인 dimensionality reduction method는 PaDiM의 시간 복잡도와 공간 복잡도를 상당히 줄여줄 수 있습니다.
5.2 Comparison with the state-of-the-art

anomaly localization 기준으로는, PaDiM-WR50-Rd550가 가장 좋은 성능을 내는 것을 확인할 수 있습니다.

anomaly detection 기준으로는, PaDiM EfficientNet-B5가 가장 좋은 성능을 내는 것을 확인할 수 있습니다.
5.3 Anomaly localization on a non-aligned dataset

앞에서 소개한 non-aligned Rd-MVTec AD dataset에 대해서도 역시 PaDiM-WR50-Rd550가 anomaly localization 기준으로 가장 우수한 성능을 나타낸다는 사실을 확인할 수 있습니다.
5.4 Scalability gain
Time complexity

anomaly localization inference time을 비교했을 때, VAE가 가장 낮지만 PaDiM-R18-Rd100은 비슷한 시간이 걸림에도 불구하고 VAE보다 훨씬 더 좋은 성능을 낸다라는 사실을 확인할 수 있습니다.
Memory complexity

MVTec AD와 같은 작은 dataset에 대해서는 SPADE가 더 작은 memory를 요구하지만, STC와 같은 큰 데이터셋에 대해서는 SPADE가 훨씬 더 많은 공간 복잡도를 가짐을 확인할 수 있습니다. 따라서, 더 큰 데이터셋에 대해서는 PaDiM이 훨씬 더 적은 공간 복잡도를 가짐을 확인할 수 있습니다.
6. Conclusion
저자들은 본 논문에서 one-class learning setting에서 distribution modeling에 기반해 anomaly detection과 localization을 수행하는 framework인 PaDiM을 제시합니다.
이는 MVTec AD와 STC dataset에 대해서 SOTA performance를 달성하였습니다.
추가로, 저자들은 evaluation protocol을 non-aligned data으로 확장하여, PaDiM이 더욱 현실적인 데이터에 강건할 수 있음을 보였습니다.
PaDiM은 낮은 메모리와 시간 복잡도를 가지며, 산업 현장과 같은 다양한 application에서 사용하기에 적합합니다.
여기까지 PaDiM 논문에 대한 paper review를 진행해보았습니다.
기존에는 신경망을 별도로 학습했어야 하지만, PaDiM 방법론은 pretrained CNN을 사용하므로 별도로 신경망을 학습할 필요가 없다는 장점을 가지고 있습니다.
또한 normal data에 대해서 Gaussian parameter만 가지고 있으면 이를 통해 distance 계산만 하면 되기 때문에 빠르게 test가 가능하며, 이는 기존에 K-NN algorithm을 필요로 하는 방법론에 비해서 training dataset이 커졌을 때 더욱 시간 복잡도의 큰 감소 효과를 볼 수 있습니다.
이전에 리뷰했었던 Patch SVDD의 경우에 제가 가지고 있는 training dataset이 3천 장이 넘는 상황이라 이를 절반만 이용하여서 실험을 진행하는데도 불구하고 test를 진행하는데 엄청난 시간이 걸린다는 문제점이 있었습니다.
해당 PaDiM을 사용한다면 훨씬 더 빠른 시간 내에 test가 가능하겠네요!
다음 포스팅에서는 PaDiM에 대한 code review를 진행해보도록 하겠습니다.
감사합니다.