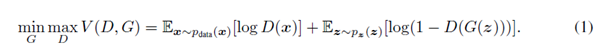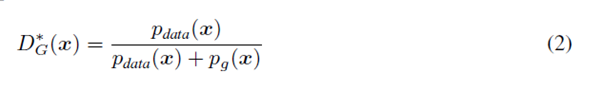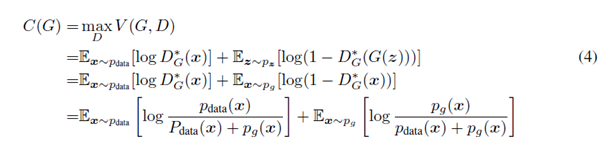오늘은 Generative Adversarial networks에 Convolutional neural network를 섞은 모델인 DCGAN에 대해서 리뷰를 해보겠습니다.
original paper : arxiv.org/abs/1511.06434
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
In recent years, supervised learning with convolutional networks (CNNs) has seen huge adoption in computer vision applications. Comparatively, unsupervised learning with CNNs has received less attention. In this work we hope to help bridge the gap between
arxiv.org
사실 GAN에 CNN을 섞은 것 자체에 대한 내용은 알고 있었는데, 논문을 읽으면서 단순히 그냥 CNN을 섞은 것이 끝이 아니라 GAN이 학습한 representation에 대해서 탐구해봤다는 점에서도 의미가 있는 논문이라고 생각했습니다.
시작해보겠습니다.
Abstract
최근에, CNN을 활용한 지도 학습은 computer vision applications에서 많이 채택되고 있다. 하지만, 비교적 CNN을 활용한 비지도 학습은 적은 관심을 받고 있다.
본 연구에서 우리는 지도 학습에 대한 CNN의 성공과 비지도 학습 사이의 격차를 해소하는데 도움이 되길 바란다.
우리는 아키텍처의 제약을 가지고 있는 deep convolutional generative adversarial networks (DCGANs)라고 불리는 CNN의 일종을 도입하며, 이것이 비지도 학습을 위한 강력한 후보 모델임을 검증했다.
다양한 이미지 데이터셋에 학습해서, 우리의 deep convolutional adversarial pair가 generator와 discriminator 모두에서 object 부분부터 장면까지 representation의 계층을 학습한다는 확실한 증거를 보여준다.
추가적으로, 새로운 task를 위해 학습된 feature를 사용하였으며, 이를 통해 general image representation으로써의 이들의 적용 가능성을 검증하였다.
1. Introduction
많은 양의 unlabeled dataset으로부터 재사용할 수 있는 feature representation을 학습하는 것은 활발하게 연구가 이뤄지고 있는 분야이다.
Computer Vision의 맥락에서, 이는 good intermediate representation을 학습하기 위해서 사실상 무제한의 unlabeled image와 video를 활용할 수 있게 해 주며, good intermediate representation은 image classification과 같은 다양한 지도 학습 task에 사용될 수 있다.
우리는 GAN을 학습시키는 것을 통해 good image representation을 만드는 방법을 제안하며, 후에 지도 학습 task를 위한 feature extractor로써 generator network와 discriminator network의 일부분을 재사용할 수 있다.
GANs은 maximum likelihood techniques에 대한 매력적인 대안을 제공한다.
추가적으로 그들의 학습 과정과 heuristic cost function (pixel-wise independent mean-square error와 같은)이 없다는 점에서 representation learning에 매력적이라고 주장할 수 있다.
GANs는 학습하는 것이 불안정하다고 알려져 있으며 종종 generator에서 터무니없는 output을 생산해내기도 한다.
GNA이 학습하는 것, 그리고 multi-layer GANS의 중간 representation에 대해서 이해하고 시각화하려는 시도에 대해서는 매우 제한적인 연구만 존재한다.
본 연구에서는 다음과 같은 contribution이 있다.
- 대부분의 환경에서 학습이 안정적이게 만들어주는 Convolutional GANs의 architectural topology에 대한 일련의 제약을 제안하고, 평가한다. (아키텍처를 만들 때 어떤 걸 해도 되는지, 안되는지에 대해서 앞으로 나오게 되는데 이를 의미합니다.)
- GANs에 의해서 학습된 filter를 시각화하고 특정 필터가 특정 object를 그리는 방법을 학습했음을 경험적으로 보여준다.
- 우리는 generator가 생성된 샘플의 많은 의미적 특징을 쉽게 조작할 수 있는 흥미로운 벡터 연산 특성을 가지고 있음을 보여준다.
2. Related work
2.1 Representation learning from unlabeled data
unsupervised representation learning은 이미지의 맥락에서, 그리고 일반적인 컴퓨터 비전 연구에서 잘 연구된 문제이다.
Unsupervised representation learning에 대한 전통적인 접근법은 데이터에 대해서 clustering을 하고(예를 들면, K-means와 같은 방법을 사용해서), classification score를 향상하기 위해 이 cluster를 사용하는 것이다.
이미지의 맥락에서, 강력한 image representation을 학습하기 위해서 image patch들의 계층적 클러스터링을 할 수 있다.
또 다른 일반적인 방법은 코드의 구성 요소인 이미지를 compact 코드로 인코딩하는 래더 구조를 분리하여 autoencoder를 학습시키는 것이며, 가능한 정확히 이미지를 복원하기 위해서 코드를 decode 한다. (사실 이걸 읽고 명확하게 이해는 안 되지만, 선행 연구 쪽이라서 그냥 넘어갔습니다..)
이러한 방법들은 또한 이미지 픽셀로부터 good feature representation을 학습할 수 있다고 알려져 있다.
Deep belief networks는 또한 계층적 표현을 학습하는데 있어서 잘 작동한다고 알려져 왔다.
2.2 Generating natural images
이미지 생성 모델은 잘 연구되어 왔으며 parametric과 non-parametric의 두 가지 범주로 나뉜다.
먼저, non-parametric model은 종종 존재하는 이미지 혹은 이미지의 패치를 데이터베이스로부터 matching을 하며
texture synthesis, super-resolution, in-painting과 같은 분야에서 사용되어 왔다.
이미지를 생성하기 위한 parametric model은 MNIST나 texture synthesis를 위해 광범위하게 연구되어 왔다.
하지만, 현실 세계의 자연스러운 이미지를 만들어내는 것은 최근까지 큰 성공을 거두지 못했다.
이미지를 생성하기 위한 variational sampling approach는 어느 정도의 성공을 거두었으나, 샘플들이 종종 흐릿해지는 현상이 나타난다. (VAE를 생각하시면 됩니다..! VAE에 대한 설명과 코드는 이전에 다루었기 때문에, 궁금하신 분들은 찾아보시면 될 것 같아요!)
다른 접근법은 iterative forward diffusion process를 사용하여 이미지를 만들어낸다.
Generative Adversarial Networks가 생성한 이미지도 noisy 하고 이해할 수 없는 현상이 나타난다.
parametric 접근법에 대한 laplacian pyramid extension은 더 높은 퀄리티의 이미지를 보여주지만, 여전히 여러 모델의 chaining에 의해 유입된 noise에 의해서 물체가 흔들리게 보이는 현상이 나타난다.
Recurrent network approach와 deconvolution network approach는 최근에 자연스러운 이미지를 만드는 것에 있어서 어느 정도의 성공을 거두었으나, 그들은 supervised tasks를 위해 generator를 활용하지 않았다. (deconvolution network approach에서 generator를 사용하지 않았기 때문에 해당 연구와의 차별점?으로 적은 게 아닐까 싶네요.)
2.3 Visualizing the internal of CNNs
신경망을 사용하는 것에 있어서 끊임없는 비평 중 하나는 신경망이 black-box 방법이라는 것이며 인간이 사용할 수 있는 간단한 알고리즘의 형태로 네트워크가 무엇을 하는지에 대해 거의 이해하지 못하고 있다는 것이다.
CNN의 맥락에서, Zeiler et. al.은 deconvolution과 filtering the maximal activation을 사용하여 네트워크에서 각 convolution filer의 대략적인 목적을 확인할 수 있었다.
마찬가지로, 입력에 gradient descent를 사용하여 필터의 특정한 subset을 활성화하는 이상적인 이미지를 확인할 수 있다.
3. Approach and model architecture
CNN을 사용해서 이미지를 모델링하기 위해 GANs를 확장하려는 과거의 시도는 성공적이지 못했다.
이는 LAPGAN의 저자들이 보다 신뢰성 있게 모델링할 수 있는 저해상도 생성 이미지를 반복적으로 상향 조정하는 alternative approach를 개발하도록 동기 부여했다.
또한 우리는 supervised literature에서 흔하게 사용되는 CNN 아키텍처를 사용해 GAN을 스케일링하려는 시도에서 어려움들을 마주했다.
하지만, 광범위한 모델 탐구 후에 우리는 많은 데이터셋에 대해서 안정적인 학습을 가져오는 아키텍처의 family를 확인하였으며 이는 더 높은 해상도와 더 깊은 생성 모델이 가능하도록 만들었다. (family를 어떻게 번역해야 할지 애매해서 그냥 뒀습니다. 사실상 다양한 모델 아키텍처를 시도해보면서 가장 적합한 형태의 모델 아키텍처를 찾았다는 의미인 것 같네요.)
우리 접근법의 핵심은 CNN 아키텍처에 대한 3개의 최근 검증된 변화를 채택하고 수정하는 것이다.
첫 번째는 max-pooling과 같은 deterministic spatial pooling functions를 stride convolution으로 대체하는 모든 convolutional net은 네트워크가 이것 자체의 spatial downsampling을 학습하도록 허용한다는 것이다.
우리는 이 접근법을 generator에서 사용하였으며, 이는 우리의 spatial upsampling을 학습하도록 만들어줬고 discriminator에서도 사용한다.
(max pooling은 deterministic 하게, 즉 결정론적으로 공간적인 풀링을 진행하지만, convolution에 stride를 하도록 만들면 자연스럽게 공간적인 정보를 down sampling 하도록 학습을 할 수 있기 때문에 이렇게 하겠다는 의미입니다. 뒤에서 나오겠지만, DCGAN은 max pooling을 사용하지 않고 stride를 통해서 해상도를 줄이는 제약을 가지고 있습니다.)
두 번째는 마지막 convolutional features에서 fully connected layer를 제거하는 쪽으로의 트렌드이다.
이것에 대한 가장 강력한 예시는 State of The Art (성능이 가장 좋다는 말) 이미지 분류 모델에서 활용되어 온 global average pooling이다.
우리는 global average pooling이 모델의 안정성을 증가시키지만 수렴 속도를 해친다는 사실을 알게 되었다.
가장 높은 convolutional feature를 generator와 discriminator의 input와 output 각각에 직접적으로 연결하는 타협안은 잘 작동했다. (직접적으로 연결한다는 의미가, pooling을 쓰지 않고 convolution 연산 만으로 input부터 output까지 연결한다는 의미인 것 같습니다.)
Uniform noise distribution $Z$를 input으로 받는 GAN의 첫 번째 layer는 단순히 행렬 곱이기 때문에 fully connected라고 불릴 수 있지만, 결과는 4차원 tensor로 reshape 되고 convolution stack의 출발지점으로 사용된다.

(해당 내용은 모델 아키텍처에서 이 부분을 이야기하는 것으로 보입니다.)
Discriminator에서는, 마지막 conv layer는 flatten 되고 하나의 sigmoid output으로 들어간다. 모델 아키텍처의 한 예시를 시각화한 것이 Fig. 1에 나와있다.

세 번째는 각 unit에 들어가는 input이 평균이 0이고 분산이 1이 되도록 normalize 해주는 것을 통해 학습을 안정적으로 만들어주는 Batch Normalization이다.
이는 안 좋은 초기화 때문에 발생하는 학습 문제를 해결하고 더 깊은 모델에서 gradient 흐름을 도와준다.
이는 deep generator가 학습을 시작할 때 모든 샘플들이 GANs에서 발견되는 일반적인 failure mode인 하나의 point로 collapse 되는 것을 방지한다. (GAN의 학습 초기에 같은 모양만 생성하는 현상을 이야기하는 것 같습니다.)
하지만, 모든 layer에 직접적으로 batch norm을 적용하는 것은 sample oscillation과 모델 불안정성을 야기한다.
이는 generator의 output layer와 discriminator의 input layer에 batchnorm을 적용하지 않는 것을 통해 피할 수 있다.
ReLU activation은 Tanh function을 사용하는 output layer만 빼고 generator의 모든 layer에서 사용된다.
우리는 bounded activation을 사용하는 것이 모델로 하여금 더 빠르게 saturate 하도록 학습시키고 학습 분포의 color space를 포괄하도록 학습함을 발견했다.
우리는 Discriminator 내에서 leaky rectified activation이 잘 작동함을 확인하였고, 특히 높은 resolution modeling에서 그러하다. (leaky rectified activation은 보통 LeakyReLU라고 부르는 활성화 함수인데, ReLU는 $x < 0$ 구간에서는 0이고 $x >=0$에서는 $x$의 값을 가지지만, LeakyReLU는 $x < 0$ 구간에서는 $ax$이고, $x >= 0$ 구간에서는 $x$입니다.)
이는 maxout activation을 사용한 original GAN paper와는 대조적이다.
안정적인 DCGAN을 위한 아키텍처 가이드라인
- Pooling layer를 strided convolution (discriminator)와 fractional-strided convolution (generator)로 교체한다.
- Generator와 discriminator 모두에서 Batch Norm을 사용한다.
- 더 깊은 아키텍처를 위해 fully connected hidden layer를 제거한다.
- Generator에서 Tanh를 사용하는 output layer를 제외한 모든 layer에서 ReLU activation을 사용한다.
- Discriminator의 모든 layer에서 LeakyReLU activation을 사용한다.
4. Details of adversarial training
우리는 DCGANs를 Large-scale Scene Understanding (LSUN), Imagenet-1k, 새롭게 모은 Face dataset의 총 3개의 데이터셋에 학습했다. 각 데이터셋의 사용에 대한 세부사항은 아래에 나와있다.
학습 이미지에 대해서는 tanh activation function의 범위인 [-1, 1]에 맞추기 위한 스케일링을 제외하고는 어떤 전처리도 적용되지 않았다.
모든 모델은 mini-batch stochastic gradient descent (SGD)를 이용해서 학습되었으며, 128 사이즈의 mini-batch를 사용했다.
모든 weight는 standard deviation 0.02를 가지는 zero-centered normal distribution을 이용하여 초기화되었다.
LeakyReLU에서는, leak의 slope는 모든 모델에서 0.2로 고정한다.
이전 GAN 연구들은 학습을 가속화하기 위해서 momentum을 사용하였으나, 우리는 튜닝된 hyperparameters를 가지고 Adam optimizer를 사용했다.
우리는 0.001의 learning rate가 너무 높다고 판단해 0.0002를 사용했다.
추가적으로, momentum term $\beta_1$을 제안된 값 0.9가 training oscillation과 불안정을 야기하여 학습을 안정화시키고자 0.5로 줄였다.
4.1부터 4.3 까지는 개별 데이터셋의 적용 내용이므로, 생략합니다.
5. Empirical validation of DCGANs capabilities
5.1 Classifying CIFAR-10 using GANs as a feature extractor
unsupervised representation learning algorithm의 품질을 평가하는 하나의 방법은 supervised dataset에 이를 feature extractor로 적용해보는 것이며 이 feature의 top에 linear model을 fitting 시켜서 성능을 평가하는 것이다.
CIFAR-10 dataset에 대해서, feature learning algorithm으로 K-means를 활용하는 single layer feature extraction pipeline으로부터 매우 강력한 baseline performance가 검증되어 왔다.
매우 많은 양의 feature maps (4800)을 사용했을 때, 이 방법은 80.6% accuracy를 달성했다.
이 방법을 unsupervised multi-layered로 확장하면 82.0% accuracy를 달성했다.
Supervised tasks를 위해 DCGANs에 의해서 학습된 representation의 품질을 평가하기 위해 DCGAN을 Imagenet-1k에 학습하고 discriminator의 모든 layer에서 나온 convolutional feature를 사용하였으며 4x4 spatial grid를 만들기 위해서 각 layer의 representation을 max-pooling 했다.
이 feature들을 flatten 하고 이를 concatenate 해서 28672차원의 벡터를 만든 다음 이에 대해서 regularized linear L2-SVM classifier를 학습시킨다.
이는 82.8% accuracy를 달성했으며, 모든 K-means 기반 접근법보다 더 좋은 성능을 달성했다.
특히 discriminator는 K-means 기반의 기법과 비교했을 때 훨씬 적은 feature map을 가지지만 (가장 높은 layer에서 512개) 4x4 spatial locations의 많은 layer 때문에 더 큰 전체 feature vector size를 갖게 된다.
추가적으로, 우리의 DCGAN은 CIFAR-10에 학습이 되지 않았으며, 이 실험은 또한 학습된 feature의 domain robustness를 증명했다.

(Table 1에서는 기존의 K-means와 같은 unsupervised 방법론에 비해서 훨씬 더 좋은 accuracy를 보임을 나타내고 있습니다. 이를 통해, DCGAN이 학습한 unsupervised representation의 품질이 좋음을 알 수 있습니다.)
5.2는 SVHN 데이터에 실행한 결과라서, 생략하겠습니다.
6. Investigating and visualizing the internals of the networks
우리는 학습된 generator와 discriminator를 다양한 방식으로 살펴볼 것이다. 우리는 training set에 대해서 어떠한 종류의 nearest neighbor search를 하지 않았다.
pixel이나 feature space에서의 nearest neighbor는 작은 이미지 변환에 의해서 하찮게 속게 된다.
우리는 또한 모델을 정량적으로 평가하기 위해서 log-likelihood metrics를 사용하지 않았으며, 이는 안 좋은 metric이기 때문이다.
6.1. Walking in the latent space
우리가 한 첫 번째 실험은 latent space의 landscape를 이해하는 것이다. 학습된 manifold에서 걷는 것은 일반적으로 우리에게 memorization의 signs에 대해서 말해줄 수 있고 (만약 sharp transitions이 있는 경우) 공간이 계층적으로 collapsed 된 방법에 대해서도 말해줄 수 있다.
(latent space에서 값을 점차적으로 변화함에 따라서, 이미지가 확 바뀌게 되면 이는 training sample을 학습했다기보다는 그저 기억한다고 볼 수 있습니다. 그 부분을 memorization의 sign이라고 표현한 것으로 보입니다. )
만약 latent space에서 걷는 것이 이미지 생성에 대해서 의미론적인 변화를 야기하는 경우(객체가 추가되거나 제거되는 것을 의미) 우리는 모델이 관련되어 있는 표현을 학습했고 흥미로운 표현을 학습했다고 추론할 수 있다.
결과는 Fig. 4에서 확인할 수 있다.

6.2 Visualizing the discriminator features
이전 연구는 큰 이미지 데이터셋에 CNN을 supervised training 했을 때 매우 강력한 학습된 feature를 야기한다는 사실을 보였다.
추가적으로, scene classification에 학습된 supervised CNN은 object detectors를 학습한다.
우리는 large image dataset에 학습된 unsupervised DCGAN도 역시 흥미로운 특징의 계층을 학습할 수 있음을 보인다.
Springenberg et al. 에 의해 제안된 guided backpropagation을 사용해서, Fig.5에서 discriminator에 의해서 학습된 feature가 침대나 창문과 같은 bedroom의 특정한 부분에서 활성화된다는 것을 보였다.
비교를 위해서, 같은 이미지에서, 우리는 의미론적으로 관련이 있거나 흥미로운 어떤 것에 활성화되지 않은 임의로 초기화된 feature에 대한 baseline을 제공한다.
(guided backpropagation을 정확히 해당 논문에서 설명하지 않고 있어서, 저도 정확히는 알 수 없지만 discriminator가 진짜라고 판별하는 데 있어서 가장 크게 기여한 부분을 표현한 이미지가 아닐까 라는 생각이 듭니다.)

6.3 Manipulating the generator representation
6.3.1 forgetting to draw certain objects
Discriminator에 의해서 학습된 표현에 더하여, generator가 학습한 표현이 무엇인지에 대한 질문이 있다.
샘플의 품질은 generator가 베개, 창문, 램프, 문, 그리고 이것저것 다양한 가구와 같은 주요한 장면 요소에 대한 구체적인 object representation을 학습했음을 시사한다.
이러한 표현들이 취하는 형태를 탐구하기 위해, 우리는 generator에서 창문을 완전히 제거하려고 실험을 수행했다.
150개 sample에 대해서, 52개의 창문 bounding box를 직접 그렸다.
두 번째로 높은 convolution layer feature에 대해서, logistic regression은 bounding box 안쪽에 있는 activation은 positive로, 같은 이미지에서 랜덤한 샘플을 뽑아서 negative로 지정하는 기준을 사용해 feature activation이 window에 있는지 없는지를 예측하기 위해 fitting 되었다.
이 간단한 모델을 사용하면, 0보다 큰 weight를 가지는 모든 feature map이(총 200개) 모든 spatial location으로부터 떨어져 나간다.
그러고 나서, 임의의 새로운 샘플은 feature map removal을 가지고 만들어지고, 없이 만들어진다.
(솔직히 이 내용만 봐서는 정확히 어떻게 만들었는지가 와 닿지는 않은데, 특히 weight가 0보다 큰 경우에 해당 activation을 어떻게 처리하는지? 이 부분이 살짝 모호한 느낌이네요.)
Window dropout을 가지고 만들어진 이미지와 없이 만들어진 이미지는 Fig. 6에 나와있다.
그리고 흥미롭게도, 네트워크는 대개 bedroom에 window를 그리는 것을 까먹고, 이를 다른 object로 대체했다.

6.3.2 Vector arithmetic on face samples
단어의 학습된 학습된 representation을 평가하는 맥락에서 (Mikolov etal., 2013) 단순한 산술 연산이 representation space에서 풍부한 linear structure를 나타낸다는 것이 검증되었다.
하나의 표준이 되는 예시는 vector("King") - vector("Man") + vector("Woman")이 Queen을 의미하는 vector에 가장 가까운 vector를 야기한다는 사실을 나타낸다.
우리는 유사한 구조가 우리의 generator의 $Z$ representation에서 나타나는지 아닌지를 살펴보았다.
우리는 시각적 개념에 대한 예시 샘플 세트의 $Z$ 벡터에 대해 유사한 산수를 수행했다.
개념 당 오직 하나의 샘플로 실험을 진행하는 것은 불안정했으나, 3개의 예시에 대한 $Z$ vector를 평균 내는 것은 의미론적으로 산수를 따르는 안정적이고 일관된 생성을 보여주었다.
Fig. 7에 나타난 object manipulation에 더해서, 우리는 face pose 또한 $Z$ space에서 선형적으로 모델링 될 수 있음을 검증하였다. (Fig. 8)




이러한 검증은 우리 모델에 의해서 학습된 $Z$ representation을 사용하여 흥미로운 application이 개발될 수 있음을 제안한다.
Conditional generative model이 scale, rotation, position과 같은 object attribute를 설득력 있게 모델링하는 방법을 학습할 수 있음은 이전에 증명되었다. (Dosovitskiy et al., 2014)
이는 우리가 알기로는 완전히 unsupervised models에서 이러한 현상이 발생한다는 것을 증명한 첫 번째 사례이다.
위에서 언급된 벡터 산수를 더 탐구하고 개발하는 것은 복잡한 이미지 분포의 conditional generative modeling에 필요한 데이터의 양을 극적으로 줄일 수 있다.
7. Conclusion and future work
우리는 generative adversarial networks를 학습시키는 더욱 안정적인 아키텍처 set을 제안하였으며 adversarial networks가 generative modeling과 supervised learning을 위한 good image representation을 학습한다는 것에 대한 증거를 제시했다.
여전히 모델 불안정성의 몇 가지 형태가 남아 있으며 우리는 모델이 더 오래 학습할수록 그들이 때때로 filter의 subset을 하나의 oscillating mode로 붕괴된다는 것을 알고 있다.
이후 연구는 이런 불안정성의 형태를 다룰 필요가 있다.
우리는 이 framework를 video (frame prediction을 위한)나 audio (speech synthesis를 위한 pre-trained feature)와 같은 다른 분야로 확장하는 것이 매우 흥미로울 것이라고 생각한다.
학습된 latent space에 대한 특성을 더욱 조사해보는 것은 또한 흥미로울 것이다.
여기까지 DCGAN 논문에 대한 내용들을 쭉 다뤄보았는데요.
이전에 GAN을 이용해서 MNIST를 만들어본 적이 있지만, 아무래도 엄청 간단한 모델이고 하다보니 숫자처럼 보이는 샘플들이 나오기는 했으나 그렇게까지 좋은 샘플이 나오지는 못했습니다.
아마도 DCGAN을 활용하면 조금 더 진짜 같은 이미지가 나오지 않을까? 하는 기대를 해보면서 다음 글에서는 code review로 찾아오겠습니다.
'(paper + code) review' 카테고리의 다른 글
| 5. Wasserstein GAN (WGAN) - paper review (0) | 2021.04.15 |
|---|---|
| 4. Unsupervised Representation learning with Deep Convolutional Generative Adversarial Networks(DCGAN) - code review (0) | 2021.03.26 |
| 3. Adversarial Autoencoders(AAE) - code review (0) | 2021.03.22 |
| 3. Adversarial Autoencoders(AAE) - paper review (0) | 2021.03.21 |
| 2. Auto-Encoding Variational Bayes(VAE) - code review (3) | 2021.03.15 |